
Deploying Keras models using TensorFlow Serving and Flask
이 글은 Himanshu Rawlani의 Deploying Keras models using TensorFlow Serving and Flask을 참고하여 작성한 글입니다.
- 원글은 tensorflow serving 설치방법을 apt-get(리눅스 환경에서만 가능)를 이용하였으나, 본 글은 docker를 이용해 설치하는 방법을 이용해 MAC OSX에서 테스트한 내용을 추가하였습니다.
- 원글은 api서버로 Flask를 이용하였으나, 본 글은 django를 이용한 예제을 추가하였습니다. django APP의 전체코드는 이 깃헙 레포지토리를 참고하십시요.
- 추가된 부분은 Blockquotes 표시되어 있습니다.
학습한 모델을 상용환경에 배포하거나, 사용하기 쉬운 API endpoints로 제공해야할 때가 있습니다. 예를 들어, 누구든지 전처리나, 딥러닝 알고리즘에 대한 기술적인 지식없이도 POST 리퀘스트를 생성해서 모델의 추정값을 JSON 형태로 반환된 결과값을 얻을수 있게 URL endpoint를 제공할수 있습니다.
이 튜토리얼에서는 keras로 만들어진 이미지 분류를 위한 CNN 모델 중 하나인 InceptionV3를 배포하기 위해 Tensorflow serving server 생성하는 법을 이야기할 것입니다. 또한 POST 리퀘스트를 수락하기 위해서 간단한 Flask server(또는 Django)를 만들어, 이미지를 전처리한 후 Tensorflow serving server에 전송한 후 JSON 형태의 결과값을 반환하도록 할 예정입니다.
What is TensorFlow Serving? - Tensorflow Servign이란?
Serving은 모델을 학습한 후 학습된 모델을 실제 서비스에 적용하는 것입니다.
 더 자세히 알고 싶다면, 여기를 참고하세요.
더 자세히 알고 싶다면, 여기를 참고하세요.
텐서플로우 서빙을 이용하면 모델을 상용환경에 쉽고 빠르게 적용할 수 있습니다. 새로운 모델을 안전하게 배포하고 동일한 서버 아키텍쳐와 API 환경을 유지하면서 또 다른 실험을 수행할수 있는 환경을 제공합니다. 기본적으로 TensorFlow와 호환되지만 다른 프레임워크에서 학습된 모델도 지원하고 확장할 수 있습니다.
Installing TensorFlow Serving - 설치하기
사전 준비 : 파이썬 가상환경을 만든 후 텐서플로우 백엔드의 케라스를 설치하세요. 자세한 것은 이곳을 참고하세요.
참고 : 이 튜토리얼의 모든 커멘드는 우분투 18.04.1 LTS에서의 파이썬 가상환경에서 실행되었습니다.
이제 가상환경 내에서 다음과 같은 커멘드를 실행하십시오.(root 권한을 위해서 sudo 를 사용하십시오)
$ apt install curl
$ echo "deb [arch=amd64] http://storage.googleapis.com/tensorflow-serving-apt stable tensorflow-model-server tensorflow-model-server-universal" | sudo tee /etc/apt/sources.list.d/tensorflow-serving.list && curl https://storage.googleapis.com/tensorflow-serving-apt/tensorflow-serving.release.pub.gpg | sudo apt-key add -
$ apt-get update
$ apt-get install tensorflow-model-server
$ tensorflow_model_server --version
TensorFlow ModelServer: 1.10.0-dev
TensorFlow Library: 1.11.0
$ python --version
Python 3.6.6
새로운 버전으로 업그레이드하는 명령어는 다음을 사용하세요.
$ apt-get upgrade tensorflow-model-server
apt-get이 실행되지 않는 경우, 예를 들어 MAC OSX에서는 Docker를 이용할 수 있습니다.
도커 다운로드 :Docker for mac
다운받은 도커를 실행시킨후 터미널에서 아래와 같은 명령어를 수행하면 tensorflow-serving이 설치된 이미지를 받을 수 있습니다. 텐서플루우나 케라스 패키지를 따로 설치할 필요가 없습니다.$ docker pull tensorflow/serving
Directory overview of what we are going to build
먼저, 디렉토리 구조를 이해하는 것이 조금 더 명확한 큰 그림을 이해하는데 도움이 됩니다.
(tensorflow) ubuntu@Himanshu:~/Desktop/Medium/keras-and-tensorflow-serving$ tree -c
└── keras-and-tensorflow-serving
├── README.md
├── my_image_classifier
│ └── 1
│ ├── saved_model.pb
│ └── variables
│ ├── variables.data-00000-of-00001
│ └── variables.index
├── test_images
│ ├── car.jpg
│ └── car.png
├── flask_server
│ ├── app.py
│ ├── flask_sample_request.py
└── scripts
├── download_inceptionv3_model.py
├── inception.h5
├── auto_cmd.py
├── export_saved_model.py
├── imagenet_class_index.json
└── serving_sample_request.py
6 directories, 15 files
모든 파일들은 이 깃허브 레포지토리에서 다운로드할수 있습니다.
https://github.com/himanshurawlani/keras-and-tensorflow-serving
Exporting Keras model for Tensorflow Serving
이 튜토리얼에서는 InceptionV3 모델을 다운로드하여 h5파일로 저장하여 이용합니다. download_inceptionv3_model.py를 이용하세요. Karas.application 라이브러리(here)에 있는 다른 모델들도 모두 가능합니다. 또는 학습한 커스텀 모델(.h5)이 있다면 이 단계는 건너뛰어도 됩니다.
from keras.applications.inception_v3 import InceptionV3
from keras.layers import Input
inception_model = InceptionV3(weights='imagenet', input_tensor=Input(shape=(224, 224, 3)))
inception_model.save('inception.h5')
위의 스크립트를 실행한 후에는 다음과 같은 결과가 화면에 출력됩니다.
$ python download_inceptionv3_model.py
Using TensorFlow backend.
Downloading data from https://github.com/fchollet/deep-learning-models/releases/download/v0.5/inception_v3_weights_tf_dim_ordering_tf_kernels.h5
96116736/96112376 [==============================] - 161s 2us/step
이제 케라스 모델 형태로 저장된 CNN 모델이 로컬 파일에 있습니다. 우리는 텐서플로우 서버가 처리할수 있도록 이 모델을 내보내야합니다. 이 작업은 export_saved_model.py 스크립트를 이용하면 됩니다.
TensorFlow는 SavedModel 형식을 모델 내보내기 위한 범용 형식으로 사용합니다. Keras 모델은 TensorFlow 객체의 관점에서 완벽하게 호환되기 때문에 Tensorflow 메서드를 사용하여 아무 문제없이 잘 내보낼 수 있습니다. TensorFlow의 tf.saved_model.simple_save() 함수를 이용하면 되고, 대부분의 사용 사례에서 잘 작동합니다.
import tensorflow as tf
# The export path contains the name and the version of the model
tf.keras.backend.set_learning_phase(0) # Ignore dropout at inference
model = tf.keras.models.load_model('./inception.h5')
export_path = '../my_image_classifier/1'
# Fetch the Keras session and save the model
# The signature definition is defined by the input and output tensors
# And stored with the default serving key
with tf.keras.backend.get_session() as sess:
tf.saved_model.simple_save(
sess,
export_path,
inputs={'input_image': model.input},
outputs={t.name: t for t in model.outputs})
결과 :
$ python export_saved_model.py
WARNING:tensorflow:No training configuration found in save file: the model was *not* compiled. Compile it manually.
WARNING 메세지를 볼수 있지만, 여기서는 인퍼런스에서만 모델을 사용할 것이기 때문에 무시하시면 됩니다. 나중에 모델을 학습하기 위해서는 모델을 로딩한 후 compile() 함수를 실행해주어야 합니다. 스크립트를 성공적으로 실행시키면, 다음과 같은 파일들이 my_image_classifier 디렉토리에 저장될 것입니다.
├── my_image_classifier
└── 1
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index
2 directories, 3 files
만약 나중에 모델을 업데이트한다고 하면(학습데이터를 더 수집하거나, 업데이트된 데이터셋으로 모델을 학습하는 상황), 아래와 같이 수행할수 있습니다.
- 새로운 케라스 모델에 대해서 동일한 스크립트를 수행합니다.
- 단, export_path=‘../my_image_classifier/1’를 export_path=‘../my_image_classifier/2’로 변경합니다.
TensorFlow Serving은 자동으로 my_image_classifier 디렉토리 내에서 새로운 버전의 모델을 감지하여, 서버에서 업데이트할 것입니다.
Starting TensorFlow Serving server - 서빙 시작하기
로컬환경에서 서빙 서버를 시작하기 위해서 다음과 같은 커멘드를 실행하세요.
$ tensorflow_model_server \
--model_base_path=/keras-and-tensorflow-serving/my_image_classifier \
--rest_api_port=9000 --model_name=ImageClassifier
-
–model_base_path : 절대경로를 사용해야합니다. 그렇지 않으면 다음과 같은 에러 메세지가 나타납니다.
Failed to start server. Error: Invalid argument: Expected model ImageClassifier to have an absolute path or URI; got base_path()=./my_image_classifier -
–rest_api_port : Tensorflow Serving은 gRPC ModelServer를 포트 8500에서 시작하고 REST API는 포트 9000에서 사용할 수 있습니다.
-
–model_name : POST 리퀘스트를 보내게 될 서빙 서버의 이름입니다. 원하는 이름을 적으면 됩니다.
도커를 이용하는 경우 다음 명령어를 사용하세요. (도커에서는 forcast-lstm 디렉토리 내에 seq2seq모델인 lstm 모델을 저장하였습니다.)
$ docker run -p 8501:8501 \ --mount type=bind,source=/your-path/forcast-lstm,\ target=/models/lstm \ -e MODEL_NAME=lstm -t tensorflow/servingtype=bind부터 source,target까지 띄어쓰기가 없도록 주의하세요.
Testing our TensorFlow Serving server - 서빙 테스트하기
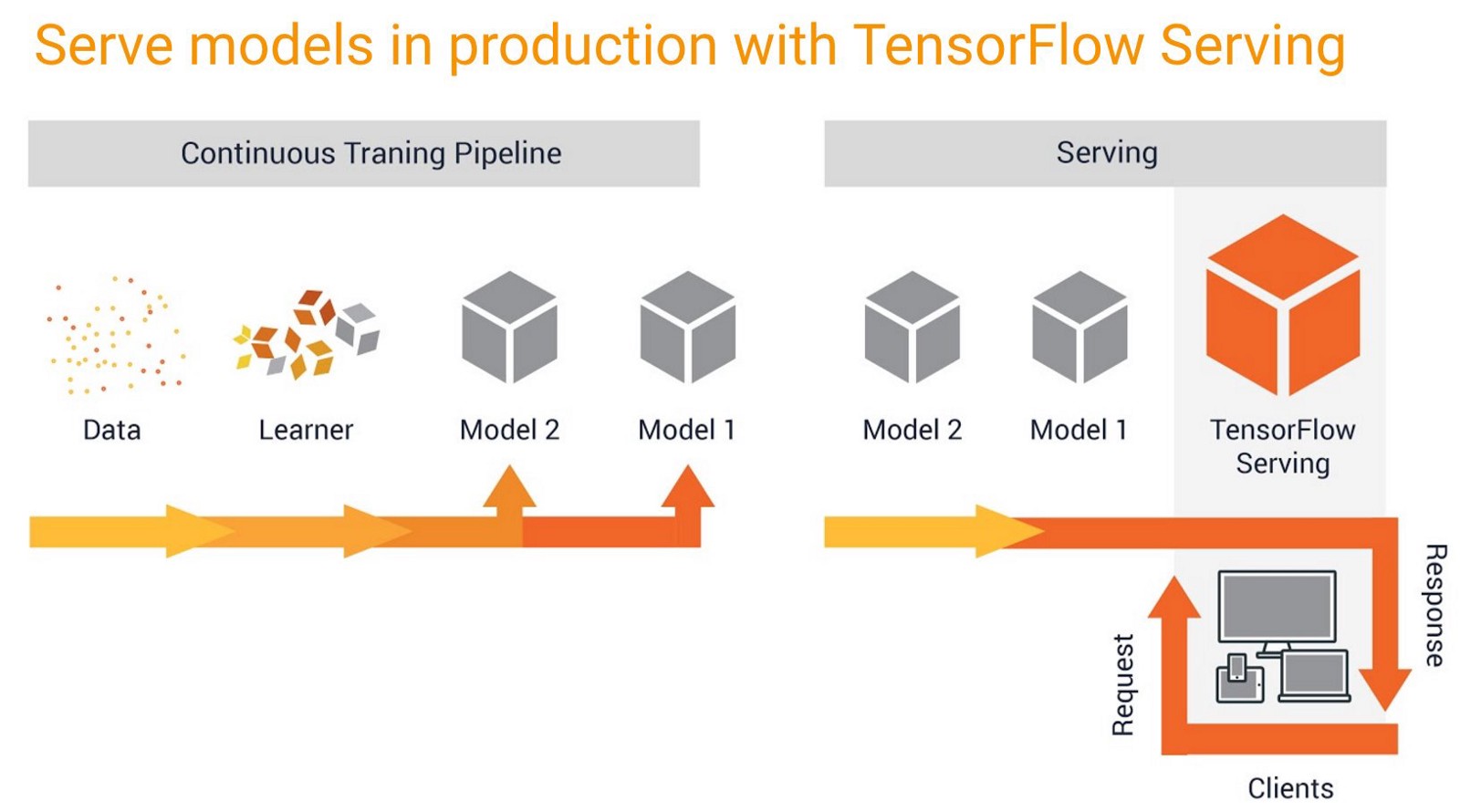 raw data에서 production model까지
raw data에서 production model까지
serving_sample_request.py 스크립트는 Tensorflow Serving server에 POST 리퀘스트를 생성합니다. 입력 이미지는 커멘드라인의 인자로 전달됩니다.
import argparse
import json
import numpy as np
import requests
from keras.applications import inception_v3
from keras.preprocessing import image
# Argument parser for giving input image_path from command line
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path of the image")
args = vars(ap.parse_args())
image_path = args['image']
# Preprocessing our input image
img = image.img_to_array(image.load_img(image_path, target_size=(224, 224))) / 255.
# this line is added because of a bug in tf_serving(1.10.0-dev)
img = img.astype('float16')
payload = {
"instances": [{'input_image': img.tolist()}]
}
# sending post request to TensorFlow Serving server
r = requests.post('http://localhost:9000/v1/models/ImageClassifier:predict', json=payload)
pred = json.loads(r.content.decode('utf-8'))
# Decoding the response
# decode_predictions(preds, top=5) by default gives top 5 results
# You can pass "top=10" to get top 10 predicitons
print(json.dumps(inception_v3.decode_predictions(np.array(pred['predictions']))[0]))
결과 :
$ python serving_sample_request.py -i ../test_images/car.png
Using TensorFlow backend.
[["n04285008", "sports_car", 0.998414], ["n04037443", "racer", 0.00140099], ["n03459775", "grille", 0.000160794], ["n02974003", "car_wheel", 9.57862e-06], ["n03100240", "convertible", 6.01581e-06]]
TensorFlow Serving server의 첫번째 리퀘스트는 이후 리퀘스트에 비해서 다소 시간이 좀 더 걸릴 수 있습니다.
간단히 터미널에서도 테스트를 해볼수 있습니다.
$ curl -d '{"instances": 'your-input-data'}' -X POST \ http://localhost:8501/v1/models/lstm:predict결과 :
{ "predictions": [[0.208057, 0.199001, 0.195517, 0.197754, 0.203455, 0.211004] ] }
Why do we need a Flask server? - Flask는 왜 필요한가
serving_sample_request.py(프로트엔드 콜러)에서는 이미지 전처리 부분을 포함합니다. 다음과 같은 이유 때문에 TensorFlow serving server 상위단에서 Flask server를 사용해야합니다.
- 프론트엔드팀에 API 엔드 포인트를 제공할때 전처리 과정의 부담을 주지 않습니다.
- 우리는 항상 Python 백엔드 서버 (예 : Node.js 서버)를 가지고 있지 않을 수도 있습니다. 따라서 전처리를 위해 numpy 및 keras 라이브러리를 사용하는 것이 어려울 수 있습니다.
- 여러 모델을 제공하려는 경우 여러 개의 TensorFlow Serving 서버를 만들어야하며 프론트 엔드 코드에 새 URL을 추가해야합니다. 그러나 Flask 서버는 도메인 URL을 동일하게 유지하며 새로운 경로 (함수) 만 추가하면됩니다.
- Flask 앱에서 서브스크립션 기반 액세스, 예외 처리 및 기타 작업을 수행 할 수 있습니다.
즉 우리는 TensorFlow Serving servers와 Frontend사이의 타이트한 커플링을 제거하기 위해 Flask를 백엔드 서버로 사용하고자 하는 것입니다.
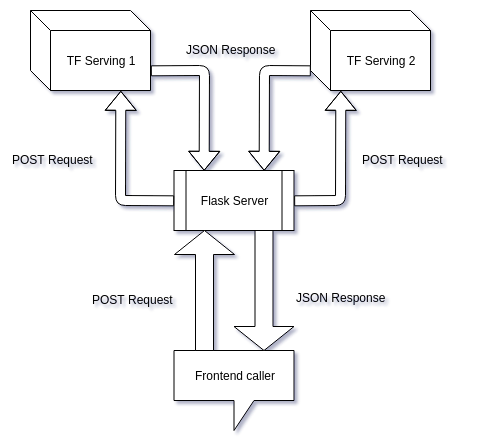
Flask server 뒤에 여러개의 TensorFlow Serving server를 숨길수 있음
이 튜토리얼에서는 TensorFlow Serving 이 설치된 동일한 머신의 가상환경 내에 Flask server를 생성하고 이미 설치된 라이브러리를 그대로 사용하고자 합니다. 이상적으로는 이 둘은 서로 분리된 머신에서 동작해야해야합니다. 리퀘스트의 수가 많아질수록 이미지 전처리를 수행하는 Flask server의 속도가 느려지기 때문입니다. 또한, 리퀘스트가 급격히 증가할 경우, 1대의 Flask server로는 충분하지 못할수 있습니다. 다중 프로트엔드 콜러를 사용할 경우, 큐잉시스템(queing system)을 사용해야할수도 있습니다. 그럼에도 불구하고, 이 튜토리얼에서 사용하는 방법이 Proof of concept으로는 충분할 것이라 생각됩니다.
Creating a Flask server - Flask server 만들기
사전 준비 : 여기를 참고하여 파이썬 가상 환경에 Flask를 설치하세요.
Flask server를 만들기위해서는 app.py라는 파일 한개만 있으면 됩니다.
import base64
import json
from io import BytesIO
import numpy as np
import requests
from flask import Flask, request, jsonify
from keras.applications import inception_v3
from keras.preprocessing import image
# from flask_cors import CORS
app = Flask(__name__)
# Uncomment this line if you are making a Cross domain request
# CORS(app)
# Testing URL
@app.route('/hello/', methods=['GET', 'POST'])
def hello_world():
return 'Hello, World!'
@app.route('/imageclassifier/predict/', methods=['POST'])
def image_classifier():
# Decoding and pre-processing base64 image
img = image.img_to_array(image.load_img(BytesIO(base64.b64decode(request.form['b64'])),
target_size=(224, 224))) / 255.
# this line is added because of a bug in tf_serving(1.10.0-dev)
img = img.astype('float16')
# Creating payload for TensorFlow serving request
payload = {
"instances": [{'input_image': img.tolist()}]
}
# Making POST request
r = requests.post('http://localhost:9000/v1/models/ImageClassifier:predict', json=payload)
# Decoding results from TensorFlow Serving server
pred = json.loads(r.content.decode('utf-8'))
# Returning JSON response to the frontend
return jsonify(inception_v3.decode_predictions(np.array(pred['predictions']))[0])
app.py 파일이 있는 경로에서 Flask server를 실행시키세요.
$ export FLASK_ENV=development && flask run --host=0.0.0.0
- FLASK_ENV=development : debug mode로 에러 로그를 제공합니다. 상용 환경에서는 사용하지 마세요.
- flask run 커멘드는 자동으로 현재경로에서 app.py 실행시킵니다.
- –host=0.0.0.0: 다른 머신에서 Flask server로 리퀘스트를 생성할수 있도록 합니다. 다른 머신으로부터 리퀘스트를 만들기 위해서는 localhost가 아닌, Flask server가 실행되고 있는 머신의 IP주소로 접근해야합니다.
결과 :
* Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
* Restarting with stat
* Debugger is active!
* Debugger PIN: 1xx-xxx-xx4
Using TensorFlow backend.
이제 TensorFlow Serving 서버를 시작하세요.
$ tensorflow_model_server --model_base_path=/home/ubuntu/Desktop/Medium/keras-and-tensorflow-serving/my_image_classifier --rest_api_port=9000 --model_name=ImageClassifier
수동으로 두 서버를 시작하는 것 대신에 auto_cmd.py를 이용해 서버 시작과 중단을 자동화 할 수 있습니다. 스크립트를 조금만 수정하면 2개 이상의 서버 동작을 처리할 수도 있습니다.
import os
import signal
import subprocess
# Making sure to use virtual environment libraries
activate_this = "/home/ubuntu/tensorflow/bin/activate_this.py"
exec(open(activate_this).read(), dict(__file__=activate_this))
# Change directory to where your Flask's app.py is present
os.chdir("/home/ubuntu/Desktop/Medium/keras-and-tensorflow-serving/flask_server")
tf_ic_server = ""
flask_server = ""
try:
tf_ic_server = subprocess.Popen(["tensorflow_model_server "
"--model_base_path=/home/ubuntu/Desktop/Medium/keras-and-tensorflow-serving/my_image_classifier "
"--rest_api_port=9000 --model_name=ImageClassifier"],
stdout=subprocess.DEVNULL,
shell=True,
preexec_fn=os.setsid)
print("Started TensorFlow Serving ImageClassifier server!")
flask_server = subprocess.Popen(["export FLASK_ENV=development && flask run --host=0.0.0.0"],
stdout=subprocess.DEVNULL,
shell=True,
preexec_fn=os.setsid)
print("Started Flask server!")
while True:
print("Type 'exit' and press 'enter' OR press CTRL+C to quit: ")
in_str = input().strip().lower()
if in_str == 'q' or in_str == 'exit':
print('Shutting down all servers...')
os.killpg(os.getpgid(tf_ic_server.pid), signal.SIGTERM)
os.killpg(os.getpgid(flask_server.pid), signal.SIGTERM)
print('Servers successfully shutdown!')
break
else:
continue
except KeyboardInterrupt:
print('Shutting down all servers...')
os.killpg(os.getpgid(tf_ic_server.pid), signal.SIGTERM)
os.killpg(os.getpgid(flask_server.pid), signal.SIGTERM)
print('Servers successfully shutdown!')
auto_cmd.py의 10번째 줄 경로가 app.py의 경로가 되도록 수정하세요. 또한 6번째 줄이 가상환경의 bin을 가르키도록 하세요. 그리고 나서 다음의 커멘드를 실행하세요(아무 경로나 상관없이 실행가능합니다)
$ python auto_cmd.py
Testing our Flask server and TensorFlow Serving server - 테스트하기
flask_sample_request.py 스크립트를 사용해서 간단한 리퀘스트를 만들 수 있습니다. 스크립트는 프로트엔드의 리퀘스트를 모방합니다.
- 인풋 이미지를 받아서, base64 포멧으로 인코딩 후, POST request를 사용하여 Flask server로 전달합니다.
- Flask server는 base64 이미지를 디코딩한 후 TensorFlow serving server에 전달하기 위해서 전처리를 수행합니다.
- Flask server는 TensorFlow serving server에 POST request를 만들고, 반환된 결과값을 디코딩합니다.
- 디코딩된 결과값은 포멧팅되어 프로트엔드로 전달됩니다.
# importing the requests library
import argparse
import base64
import requests
# defining the api-endpoint
API_ENDPOINT = "http://localhost:5000/imageclassifier/predict/"
# taking input image via command line
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path of the image")
args = vars(ap.parse_args())
image_path = args['image']
b64_image = ""
# Encoding the JPG,PNG,etc. image to base64 format
with open(image_path, "rb") as imageFile:
b64_image = base64.b64encode(imageFile.read())
# data to be sent to api
data = {'b64': b64_image}
# sending post request and saving response as response object
r = requests.post(url=API_ENDPOINT, data=data)
# extracting the response
print("{}".format(r.text))
결과 :
$ python flask_sample_request.py -i ../test_images/car.png
[
[
"n04285008",
"sports_car",
0.998414
],
[
"n04037443",
"racer",
0.00140099
],
[
"n03459775",
"grille",
0.000160794
],
[
"n02974003",
"car_wheel",
9.57862e-06
],
[
"n03100240",
"convertible",
6.01581e-06
]
]
이튜토리얼의 Flask server는 1개의 Tensorflow serving server를 처리할수 있도록 1개의 싱글 라우터만 존재합니다. app.py에 라우터를 추가하고, 모델에 따라 올바른 전처리가 수행될수 있도록 수정하면 여러개의 Tensorflow servign server를 만들어서 여러개의 모델을 같은 머신에서 동시에 서빙할수도 있습니다. 이렇게 작성된 라우터들을 프론트엔드팀에 전달하여 필요한 모델을 불러 사용하도록 할 수 있습니다.
Handling Cross-Origin HTTP request
Angular를 사용하여 POST 요청을하는 시나리오를 생각해보십시오. 다음과 같은 이유 때문에 Flask 서버는 POST가 아닌 OPTIONS 헤더를 받습니다.
- 웹 어플리케이션은 기존 출처와 다른 출처 (도메인, 프로토콜 및 포트)를 가진 리소스를 요청할 때 cross-origin HTTP 요청을 만듭니다.
- CORS (Cross Origin Resource Sharing)는 추가 HTTP 헤더를 사용하여 브라우저에 한 원점 (도메인)에서 실행중인 웹 응용 프로그램을 알리는 메커니즘입니다. CORS에 대한 자세한 내용은 여기를 참조하십시오.
따라서 Angular는 Flask 서버에서 어떤 응답도 받지 못하게 됩니다. 이 문제를 해결하기 위해서는 app.py에서 Flask-CORS를 활성화해야합니다. 더 자세한 사항은 여기를 참고하세요.
Django 버전의 api 만들기
python 기반의 웹 프레임워크는 flask 이외에 django가 있습니다. 아마도 여러분의 어플리케이션이 이미 django로 작성되어 있다면, tf-servering에 리퀘스트를 보내는 역할을 django에서 수행할수 있습니다. 장고 프로젝트를 설치한후 새로운 앱을 생성합니다. 장고에 대한 자세한 내용은 이 포스팅의 범위를 넘어서기 때문에 자세한 부분은 여기를 참 고하세요.
$ python manage.py startapp dashboard생성된 앱의 디렉토리 구조는 아래와 같습니다. 여기서는
model.py,views.py,predict.html,urls.py만 수정합니다.dashboard/ templates dashboard predict.html __init__.py admin.py apps.py migrations/ __init__.py models.py tests.py views.py urls.py
model.py
AirKoreaStation(측정소)와 AirKoreaData(측정데이터)로 두가지 모델이 있습니다. 여기서는 측정소를 지정하면 해당 측정소에서 측정된 초미세먼지 데이터(pm25value)를 이용해 미래값을 예측하는 것을 수행하고자 합니다.
from django.db import models
class AirKoreaStations(models.Model):
id = models.AutoField(db_column='ID', primary_key=True, blank=True, null=False)
stationname = models.TextField(db_column='stationName', blank=True, null=True)
#...(생략)...
class AirKoreaData(models.Model):
id = models.AutoField(db_column='ID', primary_key=True, blank=True, null=False)
stnfk = models.ForeignKey(AirKoreaStations, on_delete=models.CASCADE)
pm10value = models.IntegerField(db_column='pm10Value', blank=True, null=True)
pm25value = models.IntegerField(db_column='pm25Value', blank=True, null=True)
#...(생략)...
view.py
AirKoreaData의 pm25value 입력값으로 전처리를 수행하고, 이를 tensorflow serving server에 전달하여 reponse값을 받습니다. 전달받은 predictions값을 template에 ‘forcast’ 인자로 넘겨줍니다.
from django.shortcuts import render
from .models import AirKoreaData
import datetime as dt
import numpy as np
import pandas as pd
import requests
import json
def predict(request, station_name):
yesterday = dt.datetime.now().replace(microsecond=0, second=0, minute=0, hour=0)
recent_data = AirKoreaData.objects.filter(stnfk__stationname=station_name).\
filter(datatime__range=(yesterday - dt.timedelta(days=1), yesterday)).order_by('datatime')
## 전처리
x = list(recent_data.values_list('pm25value', flat=True))
x = pd.Series(x[-24:])
x = x.interpolate()
x = np.array(x)
x = x.reshape(-1, 24, 1)
## tensorflow serving server에 request
payload = {"instances": x.tolist()}
r = requests.post('http://localhost:8501/v1/models/lstm:predict', json=payload)
y_pred = json.loads(r.content.decode('utf-8'))
y_pred = y_pred['predictions'][0]
y_pred = [i * 200 for i in y_pred]
return render(request, "predict.html", {'forecast': y_pred})
predict.html
전달받은 forecast값을 화면에 표시해줍니다.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{ % for data in forecast %} { { data }}{ % endfor %}
</body>
</html>
urls.py
urls.py를 생성하여 http://localhost:8000/predict에 접속하면 view.predict가 실행되도록 해줍니다.
from django.urls import path
import dashboard.views as views
urlpatterns = [
path('predict/<str:station_name>/', views.predict, name='predict'),
]
자, 이제 tensorflow serving server를 실행시킵니다. 그리고 django app도 실행시킵니다.
$ docker run -p 8501:8501 --mount type=bind,source=/Users/jyj0729/PycharmProjects/mysite/forcast_model,target=/models/lstm -e MODEL_NAME=lstm -t tensorflow/serving
$ python manage.py runserver
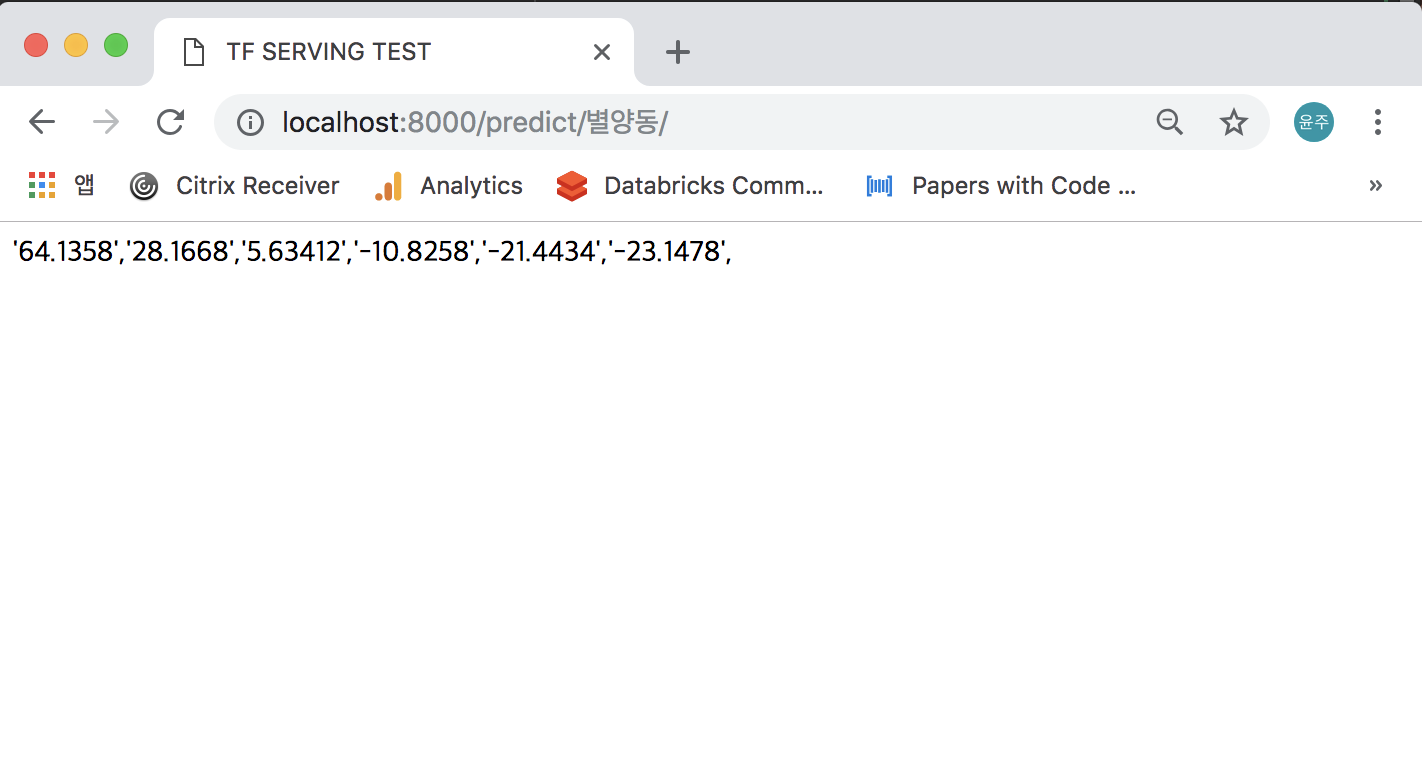
이제
http://localhost:8000/predict/별양동/으로 접속하면 모델 결과값이 출력되는 것을 볼 수 있습니다.
Conclusion - 결론
여기까지 머신러닝 모델을 배포하는 과정을 알아보았습니다. TensorFlow Serving은 머신러닝을 웹사이트나 다른 어플리케이션과 통합되도록 도와줍니다. 잘 학습된 다양한 케라스 모델을 사용하여 머신러닝에 대한 최소 지식으로도 유용한 어플리케이션 개발이 가능합니다.
Comments