
시계열 분석 part3 - Non-stationary
Part1에서는 stationarity를 가정으로, 시계열 데이터의 기본 모델인 AR과 MA에 대해서 알아보고 모델의 파라미터를 추정하기 위해서 Yule-Walker Equations을 알아보았습니다. 또한 모델의 order를 결정하기 위해 ACF, PACF를 이용하는 방법을 살펴보았습니다. 실제 분석에서 모델의 파라미터를 추정하는 것은 소프트웨어를 이용해 자동적으로 계산되기 때문에 하나 하나를 기억할 필요는 없지만, 그 원리에 대해서 이해하는 것을 목적으로 합니다. Part2에서는 실제 데이터를 이용해 stationarity 가정을 검증하고, 적합한 모델을 찾고 모델의 order를 결정하는 방법, 추정한 모델을 진단하고 검증하는 방법들을 알아보았습니다. AIC, BIC, HQIC와 같은 지표를 사용하여 여러가지 모델 중 더 나은 성능의 모델을 선택할 수 있고, 모델의 residual을 이용해 모델을 진단하는 과정을 직접 수행해보았습니다. 또한 최종 선택한 모델을 이용해 미래 값을 예측(forecast)해보고, MSE를 이용해 예측력을 평가해보기도 하였습니다.
이번 Part3에서는 non-stationary 시계열 데이터를 모델링하는 방법들에 대해서 이야기해보도록 하겠습니다. 앞서 포스팅에서 살펴보았듯이 주어진 데이터 \({x_1, …, x_n}\)에 대한 시계열 차트를 그렸을때, (a) stationarity와 비교하여 명확한 편차 변화가 보이지 않고 (b) ACF가 점차 감소하는 모습을 보이면 (평균을 0로 맞춘 후) ARMA를 사용하면 됩니다.
그렇지 않았을 때는 주어진 데이터를 변환시켜 (a)와 (b) 특정을 갖는 새로운 시계열 데이터를 생성하는 방법을 사용해야합니다. 이 때 주로 사용하는 방법은 “difference(차분)”으로, difference를 통해 얻은 새로운 시리즈 \({y_1, … y_n}\)가 ARMA를 따를 때, ARIMA 프로세스를 따른다고 표현합니다.
A generalization of this class, which incorporates a wide range of nonstationary series, is provided by the ARIMA processes, i.e., processes that reduce to ARMA processes when differenced finitely many times
Definition
If d is a nonnegative integer, then \({X_t}\) is an ARIMA(p, d, q) process if \(Y_t := (1-B)^dX_t\) is a causal ARMA(p, q) process.
\(Y_t - \phi Y_{t-1} = Z_t + \theta Z_{t-1}\) where \(Y_t = X_t - X_{t-1}\)
\(X_t - \phi X_{t-1} = Z_t + \theta Z_{t-1}\) where \(Z_t \sim N(0, \sigma^2)\)
\[\begin{align} \begin{bmatrix} X_t \\ Y_t \end{bmatrix} = & \begin{bmatrix} \phi_{X, X} & \phi_{X,Y} \\ \phi_{Y,X} & \phi_{Y,Y} \end{bmatrix} \begin{bmatrix} X_{t-1} \\ Y_{t-1} \end{bmatrix} + \begin{bmatrix} Z_t \\ W_t \end{bmatrix}\end{align}\]참고로 B는 backward shift operator를 의미합니다. \(BX_t = X_{t-1}\)로 \(\nabla X_t = X_t - X_{t-1} = (1-B) X_t\)로 표기합니다.
이해를 돕기 위해서 ARIMA(1, 1, 0) process를 따르는 데이터를 생성한후, sample ACF, sample PACF를 살펴보도록 하겠습니다. statsmodels의 arma_generate_sample를 이용해 ARMA(1,0) 프로세스를 따르는 데이터를 생성한 후(\(\phi\) = 0.8), cumsum()을 이용하면 ARIMA(1,1,0) 프로세스를 따르는 데이터를 생성할 수 있습니다.
import statsmodels.api as sm
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
n = 200
alphas = np.array([0.8])
ar = np.r_[1, -alphas]
ma = np.r_[1]
arma10 = sm.tsa.arma_generate_sample(ar=ar, ma=ma, nsample=n)
arima110 = arma10.cumsum()
이 인공 데이터의 sample ACF와 sample PACF를 나타내면 아래와 같습니다.
plt.plot(arima110)
plt.show()
sm.tsa.graphics.plot_acf(arima110, lags=50)
sm.tsa.graphics.plot_pacf(arima110, lags=50)
plt.show()
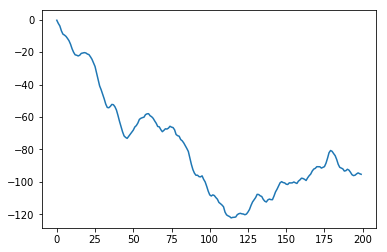
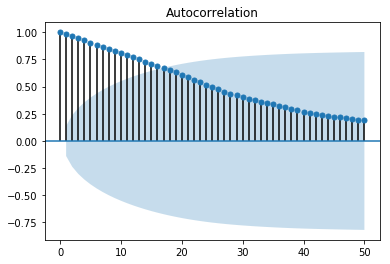
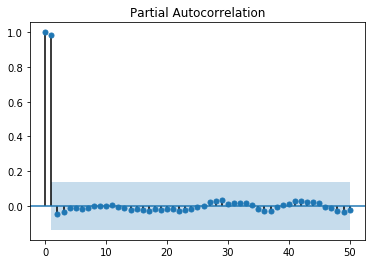
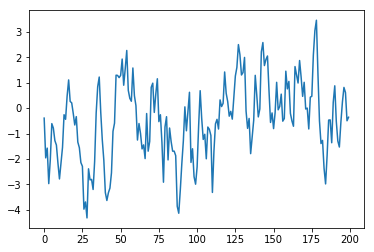
위 그림에서도 알 수 있듯이 ARIMA 모델의 적합성을 나타내는 가장 큰 증거는 양의 sample ACF가 천천히 감소하는 모습을 띄는 것입니다. 따라서 non-stationary로 진단되는 데이터의 경우에는, 데이터가 ARMA 프로세스로 표현될수 있게 \(\nabla = 1-B\) 오퍼레이터를 적용해야합니다. \(\nabla = 1-B\) 오퍼레이터를 적용하는 것은 ACF가 현재보다 더 급격하게 감소하는 모습을 보일 때까지 반복할 수 있습니다. 실제로 위의 인공데이터에서 \(\nabla\) 오퍼레이터를 한번 적용한 후 다시 시계열 차트와 sample ACF, sample PACF를 그려본 결과는 아래와 같습니다. (앞의 것에 비해서 ACF가 더 급격히 감소하는 것을 볼 수 있습니다)
plt.plot(arma10)
plt.show()
sm.tsa.graphics.plot_acf(arma10, lags=50)
sm.tsa.graphics.plot_pacf(arma10, lags=50)
plt.show()
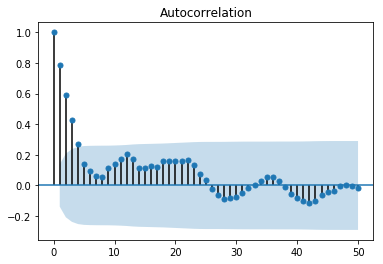
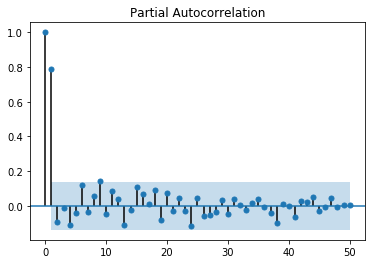
arima_mod110 = sm.tsa.ARIMA(arima110, (1,1,0)).fit(trend='nc')
print(arima_mod110.summary())
print('variance :', arima_mod110.resid.var())
ARIMA Model Results
==============================================================================
Dep. Variable: D.y No. Observations: 199
Model: ARIMA(1, 1, 0) Log Likelihood -270.813
Method: css-mle S.D. of innovations 0.941
Date: Mon, 31 Dec 2018 AIC 545.626
Time: 06:49:49 BIC 552.212
Sample: 1 HQIC 548.291
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1.D.y 0.8085 0.041 19.576 0.000 0.728 0.889
Roots
=============================================================================
Real Imaginary Modulus Frequency
-----------------------------------------------------------------------------
AR.1 1.2369 +0.0000j 1.2369 0.0000
-----------------------------------------------------------------------------
variance : 0.8895674306182718
- Estimated parameters from data : \((1-0.8085)(1-B)X_t = Z_t, \ \ \ \ \ \ \ \{Z_t\} \sim WN(0, 0.8798)\)
- True generating Process : \((1-0.8)(1-B)X_t = Z_t, \ \ \ \ \ \ \ \ \ \ \ \ \{Z_t\} \sim WN(0, 1)\)
statsmodel의 ARIMA를 이용해 추정한 모델 파라미터와 실제 데이터를 생성할 때 사용한 파라미터가 거의 비슷한 것을 볼 수 있습니다. ARIMA 모델을 추정하는 방법은 difference을 적용하는 것을 제외하고는 이후 과정은 ARMA와 비슷한 맥략을 유지합니다.
Identification Techniques
(a) Preliminary Transformations ARMA 모델을 사용하기 전에 주어진 데이터가 stationarity 가정에 더 부합한 새로운 시리즈로 변환할 필요성이 있는지 검토해야합니다. 예를 들어 스케일에 대해 의존도가 나타나는 경우, 로그변환을 취해서 의존성을 제거해야합니다.(Box-Cox transformation) 또한 시계열 차트에서 전체적으로 우상향/우하향하는 추세(trend)나 주기적으로 반복되는 패턴(seasonality)이 발견될 수 있습니다. 이런 경우 2가지 방법으로 처리할 수 있습니다.
1) Classical decomposition - trend component, seasonal component, random residual component
2) Differencing - Wine sale의 예시에서는 12개월 주기로 반복되는 패턴이 존재하므로, \({(1-B^{12})V_t}\)를 적용
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
df = pd.read_csv('monthly-australian-wine-sales-th.csv', skiprows=1, header=None, encoding='euc-kr')
u_t = df[1]
v_t = np.log(u_t)
v_t_st = v_t.diff(12)
fig = plt.figure(figsize=(12,10))
fig.add_subplot(311)
plt.plot(df[1], marker='o')
plt.legend(['$U_t$'])
fig.add_subplot(312)
plt.plot(v_t, c='orange', marker='o')
plt.legend(['$V_t = lnU_t$'])
fig.add_subplot(313)
plt.plot(v_t_st, c='green', marker='o')
plt.legend(['$V_t^* = (1-B^{12})V_t$'])
plt.suptitle('Monthly Australian Wine Sales')
plt.show()
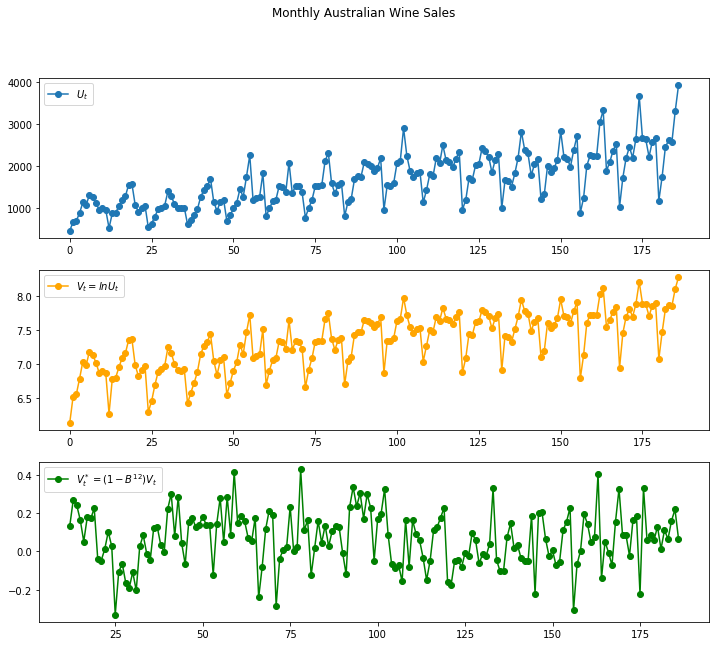
(b) Identification and Estimation 전처리 변환을 통해서 stationarity 가정에 부합하는 시리즈를 얻을 후에는 적합한 ARMA(p, q)를 찾습니다. p와 q를 먼저 결정해야하는데, 보통 p와 q를 크게 설정할 수록 추정된 모델의 성능이 더 좋은 것으로 나타납니다. 추정해야하는 파라미터 갯수가 많아질수록 패널티가 증가하도록 AIC 등과 같은 지표를 사용하는 것이 바람직합니다. 또한 모델을 선택한 후에는 residual이 white noise가 맞는지 검증하는 작업을 수행해야합니다. 이에 대한 내용은 part2에서 이미 살펴보았으니 이번에는 자세히 다루지 않겠습니다.
stationary_series = np.array(v_t_st.dropna())
result = sm.tsa.stattools.arma_order_select_ic(stationary_series, ic=['aic', 'bic'], trend='nc')
## result.aic_min_order = (2,2)
## result.bic_min_order = (1,1)
wine_model = sm.tsa.ARMA(np.array(v_t_st.dropna()), result.aic_min_order).fit(trend='nc')
print(wine_model.summary())
print('variance :', wine_model.resid.var())
ARMA Model Results
==============================================================================
Dep. Variable: y No. Observations: 175
Model: ARMA(2, 2) Log Likelihood 95.322
Method: css-mle S.D. of innovations 0.139
Date: Mon, 31 Dec 2018 AIC -180.643
Time: 20:50:06 BIC -164.819
Sample: 0 HQIC -174.225
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1.y 0.0304 0.055 0.556 0.579 -0.077 0.138
ar.L2.y 0.8740 0.047 18.621 0.000 0.782 0.966
ma.L1.y 0.2052 0.086 2.398 0.018 0.038 0.373
ma.L2.y -0.7948 0.085 -9.367 0.000 -0.961 -0.628
Roots
=============================================================================
Real Imaginary Modulus Frequency
-----------------------------------------------------------------------------
AR.1 1.0524 +0.0000j 1.0524 0.0000
AR.2 -1.0872 +0.0000j 1.0872 0.5000
MA.1 -1.0000 +0.0000j 1.0000 0.5000
MA.2 1.2582 +0.0000j 1.2582 0.0000
-----------------------------------------------------------------------------
variance : 0.019416898661637372
Seasonal ARIMA models
앞선 설명에서 이미 차분을 통해서 seasonality를 제거하는 방법을 언급하였지만, 조금 더 포멀한 방식으로 seasonal ARIMA를 정의하면 다음과 같습니다.
Definition
If d and D are nonnegative integers, then \(\{X_t\}\) is a seasonal \(ARIMA(p, d, q) \times (P, D, Q)_s\) process with period s if the differenced series \(Y_t=(1-B)^d(1-B^s)^D X_t\) is a causal ARMA process defined by
\[\phi(B)\Phi(B^s)Y_t = \theta(B)\Theta(B^s)Z_t, \ \ \ \{Z_t\} \sim WN(0, \sigma^2)\]where \(\phi(z) = 1 - \phi_1z - ... - \phi_p z^p, \Phi(z) = 1 -\Phi_1z - ... - \Phi_Pz^P, \\ \theta(z) = 1 + \theta_1z + ... + \theta_qz^q\) and \(\Theta(z) = 1+ \Theta_1z + ... + \Theta_Qz^Q.\)
모델 order를 결정하기 위해서 총 7가지의 파라미터\((p, d, q, P, D, Q)_s\)가 존재합니다. 예를 들어 살펴보도록 하겠습니다.
- p : order of non-seasonal AR terms
- d : order of non-seasonal differencing
- q : order of non-seasonal MA terms
- P : order of seasonal AR (i.e. SAR) terms
- D : order of seasonal differencing (I.e. power of (1 - \(B^s\))
- Q : order of seasonal MA (i.e. SMA) terms
- s : the number of time steps for a single seasonal period
Example - \(SARIMA(1, 0, 0, 1, 0, 1)_{12}\)
\((1-\phi_1B)(1-\Phi_1B^{12})X_t = (1+\Theta_1B^{12})Z_t\) \(X_t - \phi_1X_{t-1} - \Phi_1X_{t-12} + \phi_1\Phi_1X_{t-13} = Z_t + \Theta_1Z_{t-12}\)
Example - \(SARIMA(0, 1, 1, 0, 0, 1)_{4}\)
\((1-B)X_t = (1+\Theta_1B^{4})(1+\theta_1B)Z_t\) \(X_t - X_{t-1} = Z_t + \theta_1Z_{t-1} + \Theta_1Z_{t-4} + \theta_1\Theta_1Z_{t-5}\)
Seasonality가 존재하는 시계열 데이터의 ACF는 아래와 같이 zero에 수렴하지 않고 주기적인 패턴이 나타나는 것이 특징입니다. 예를 들어 \(SARIMA(0,0,1, 0, 0,1)_{12}\) 의 ACF를 계산해보도록 하겠습니다.
Example - \(SARIMA(0, 0, 1, 0, 0, 1)_{12}\)
\[\begin{align} X_t & = (1 + \Theta_1B^{12})(1+\theta_1B)Z_t \\ X_t & = Z_t + \theta_1Z_{t-1} + \Theta_1Z_{t-12} + \theta_1\Theta_1Z_{t-13} \\ \\ \gamma(0) & = Cov(X_t, X_t)=Var(X_t) \\ X_t & = Z_t + \theta_1Z_{t-1} + \Theta_1Z_{t-12} + \theta_1\Theta_1Z_{t-13} \\ Var(X_t) & = \sigma_Z^2 + \theta_1^2\sigma_Z^2 + \Theta_1^2\sigma_Z^2 + \theta_1^2\Theta_1^2\sigma_Z^2 \\ \gamma(0) & = (1+\theta_1^2)(1+\Theta_1^2)\sigma_z^2 \\ \\ \gamma(1) & = Cov(X_t, X_{t-1}) \\ X_t & = Z_t + \theta_1Z_{t-1} + \Theta_1Z_{t-12} + \theta_1\Theta_1Z_{t-13} \\ X_{t-1} & = Z_{t-1} + \theta_1Z_{t-2} + \Theta_1Z_{t-13} + \theta_1\Theta_1Z_{t-14} \\ \gamma(1) & = \theta_1\sigma_Z^2 + \theta_1\Theta_1^2\sigma_Z^2\\ \gamma(1) & = \theta_1(1+\Theta_1^2)\sigma_Z^2 \end{align}\]참고. \(Z_t\) is independent with \(Z_{t-1}\)
\[\begin{align} \rho(1) & = \frac{\gamma(1)}{\gamma(0)} = \frac{\theta_1}{1 + \theta_1^2} \le \frac{1}{2} \\ \\ \gamma(2) & = Cov(X_t, X_{t-2}) \\ X_t & = Z_t + \theta_1Z_{t-1} + \Theta_1Z_{t-12} + \theta_1\Theta_1Z_{t-13} \\ X_{t-2} & = Z_{t-2} + \theta_1Z_{t-3} + \Theta_1Z_{t-14} + \theta_1\Theta_1Z_{t-15} \\ \rho(2) & = 0 \\ \rho(i) & = 0, \ \ \ \ \ \ \ for \ i = 2, 3, … 10\\ \\ \gamma(11) & = Cov(X_t, X_{t-11}) \\ X_t & = Z_t + \theta_1Z_{t-1} + \Theta_1Z_{t-12} + \theta_1\Theta_1Z_{t-13} \\ X_{t-11} & = Z_{t-11} + \theta_1Z_{t-12} + \Theta_1Z_{t-23} + \theta_1\Theta_1Z_{t-24} \\ \gamma(11) & = \theta_1\Theta_1\sigma_Z^2\\ \rho(11) & = \frac{\gamma(11)}{\gamma(0)} = \frac{\theta_1\Theta_1}{(1 + \theta_1^2)(1 + \Theta_1^2)} \le \frac{1}{4} \end{align}\]import statsmodels.api as sm
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
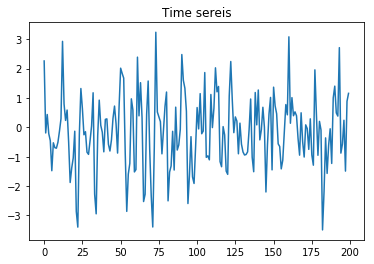
sarima_00100112 = sm.tsa.arma_generate_sample([1], [1, 0.4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.6, 0.24], nsample=200)
plt.plot(sarima_00100112)
plt.show()
sm.tsa.graphics.plot_acf(sarima_00100112, lags=100)
plt.show()
sm.tsa.graphics.plot_pacf(sarima_00100112,lags=50)
plt.show()
model = sm.tsa.statespace.SARIMAX(sarima_00100112, order=(0, 0, 1), seasonal_order=(0, 0, 1, 12)).fit()
print(model.summary())
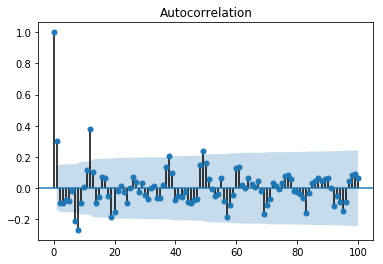
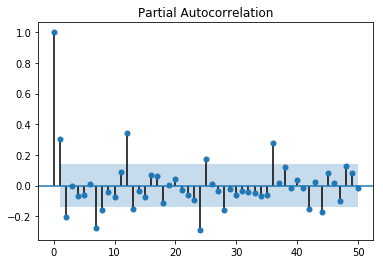
Statespace Model Results
==========================================================================================
Dep. Variable: y No. Observations: 200
Model: SARIMAX(0, 0, 1)x(0, 0, 1, 12) Log Likelihood -272.506
Date: Wed, 02 Jan 2019 AIC 551.013
Time: 22:27:26 BIC 560.908
Sample: 0 HQIC 555.017
- 200
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ma.L1 0.4721 0.070 6.791 0.000 0.336 0.608
ma.S.L12 0.6453 0.061 10.587 0.000 0.526 0.765
sigma2 0.8638 0.093 9.326 0.000 0.682 1.045
===================================================================================
Ljung-Box (Q): 36.60 Jarque-Bera (JB): 1.18
Prob(Q): 0.62 Prob(JB): 0.55
Heteroskedasticity (H): 1.10 Skew: -0.18
Prob(H) (two-sided): 0.70 Kurtosis: 2.93
===================================================================================
위에서 말씀드렸다시피, Seasonal ARIMA는 7개의 hyper parameter(trend order: p,d,q와 seasonal order : P,D,Q,S)를 갖습니다. Part2에서 이야기한 검증 방법들을 사용하여 7개의 hyper parameter를 구성할수 있지만, 각각에 맞춰 신중한 분석과 도메인 지식이 필요합니다. (대안으로 hyper parameter 모음을 그리드 서치 형태로 실험한 후 선택할 수 있습니다. 자세한 내용은 포스팅을 참고하세요.
실제 데이터를 이용한 Seasonal ARIMA Forecasting
Part2에서 사용한 초미세먼지 농도를 사용하여 Seasonal ARIMA를 적용해보도록 하겠습니다.
- 데이터 : 경남 창원시 의창구 원이대로 450(시설관리공단 실내수영장 앞)에서 측정된 초미세먼지(PM2.5)
- 기간 : 2018-9-18 19:00 ~ 2018-12-18 17:00 (3개월, 1시간 단위)
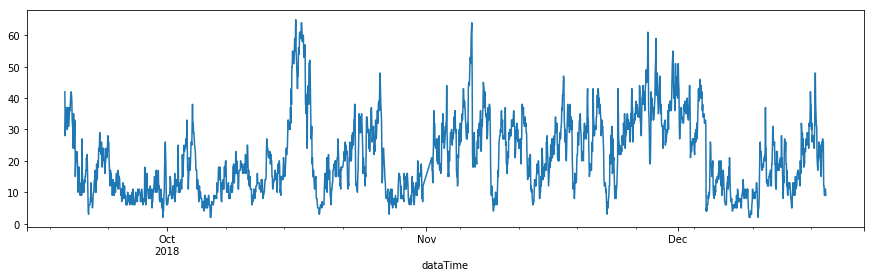
grid search방식을 사용하여 적절한 모델 order를 탐색하였습니다. 7개의 파라미터의 탐색범위는 아래와 같고, 모델 선택 기준으로는 AIC 지표를 사용하였습니다.
- p_params = [0, 1, 2]
- d_params = [0, 1]
- q_params = [0, 1, 2]
- t_params = [‘n’,’c’,’t’,’ct’]
- P_params = [0, 1, 2]
- D_params = [0, 1]
- Q_params = [0, 1, 2]
- m_params = [24] ## 하루 주기가 있다고 가정하여 24시간으로 고정
- 총 1,296개의 조합을 탐색
전체 코드는 여기를 참고하세요.
탐색결과 best 3 : [(2, 0, 2), (1, 1, 2, 24), ‘n’] 11723.18462075862 [(2, 0, 2), (1, 1, 2, 24), ‘c’] 11725.455126156874 [(1, 0, 2), (1, 1, 2, 24), ‘n’] 11725.651159324498
1296가지 모델들의 AIC 히스토그램
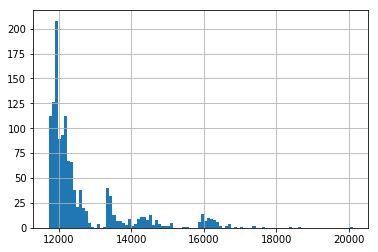
AIC가 가장 낮았던 \(SARIMA(2, 0, 2, 1, 1, 2)_{24}\) 모델을 검증하고, 모델을 이용해서 예측을 수행해보도록 하겠습니다.
residual plot
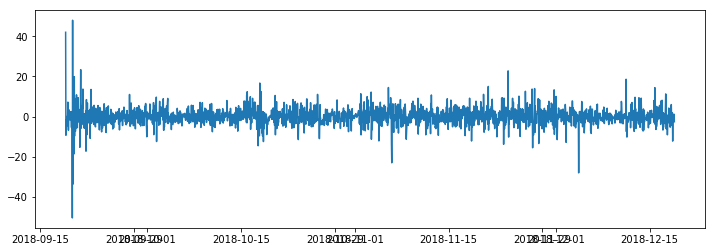
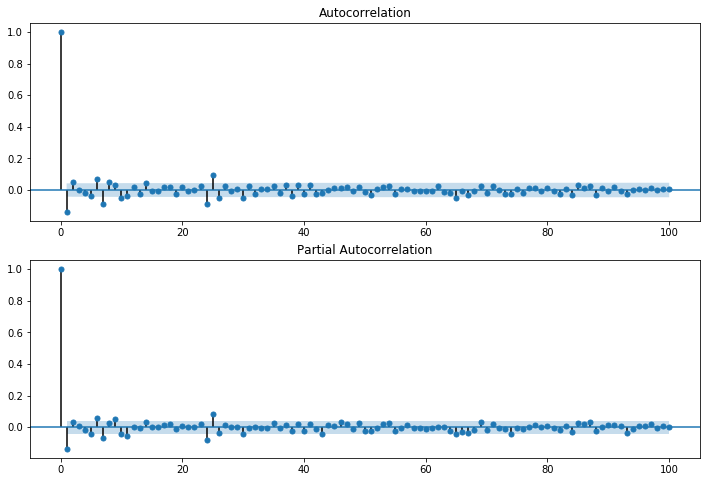
residual acf, pacf
residual qq plot
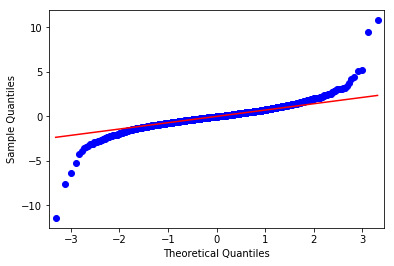
residual normality test :
NormaltestResult(statistic=561.8797124030831, pvalue=9.758222244224708e-123)
위 결과를 종합해보면 residual이 White Noise이고, 정규분포를 따른다고 할 수 있습니다.
이제 이 모델을 이용하여 forcasting을 수행해보도록 하겠습니다. dynamic 옵션을 False로 설정하는 것은 항상 in-sample 데이터를 사용하여 미래값을 예측하는 것이고, True로 설정할 경우 이전 lag의 모델 예측값을 사용해서 계산하는 것입니다. 첫번째 예측값을 이후 lag에서 계속 사용하게 됩니다.
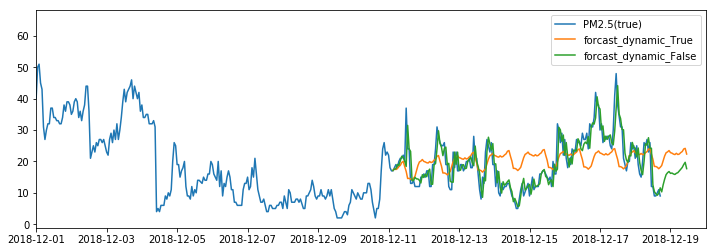
예측력을 평가하기 위해 RMSE는 다음과 같습니다. AR(8) 모델과 비교하여 약 0.0257가 감소한 것을 볼 수 있습니다.
- SARIMA(2,0,2,1,1,2, 24) model’s RMSE : 2.8916720525590627
- AR(1) model’s RMSE: 3.006486217286414
- AR(3) model’s RMSE: 2.9717700323027256
- AR(8) model’s RMSE: 2.9174007777104203
여기까지 non-stationary 모델을 살펴보았습니다. Differencing을 이용해 ARMA을 적용하는 ARIMA모델을 살펴보았고, seasonality까지 함께 고려하는 SARIMA까지 알아보았습니다. 또한 실제 데이터를 이용하여 SARIMA의 하이퍼파라미터를 그리드탐색하여 최적의 모델 order를 결정하였고, 이를 통해서 AR모델 대비 예측력(RMSE)가 0.0257가 향상된 결과를 얻을수 있었습니다.
다음 포스팅에서는 multivariate time series에 대해서 살펴보도록 하겠습니다.
감사합니다!
Reference
[1] Introduction to Time Series and Forecasting, Peter J. Brockwell, Richard A. Davis,
[2] Statsmodel’s Documentation
[3] Coursera - Practical Time Series Analysis
[5] wikipedia - Partial correlation
[6] How to grid search SARIMA model hyperparameters for time series forecasting in python
Comments