
시계열 분석 part2 - practical example
지난 포스팅에서는 시계열 데이터를 모델링하기 위한 모델과 모델의 파라미터를 추정하기 위한 이론적 배경을 살펴보았습니다.
stationary하고 causal하다는 가정 하에서 Auto-Regressive 또는 Moving average, 또는 두가지가 섞인 ARMA 모델을 사용할 수 있고, 모델의 order를 결정하기 위해서 ACF와 PACF를 사용하는 방법을 학습하였습니다.
실제 분석 과정에서는 ACF, PACF 이외에 여러가지 방법을 복합적으로 사용하여 적합한 모델을 찾아나갑니다. 예를 들어 1차로 시계열 모델을 추정한 후 추정값과 실제값의 차이로 residual을 계산합니다. residual이 정규분포를 따르는 white noise라는 가정을 검증함으로써 모델이 적합한지 확인할 수 있습니다. 이를 위해 q-q plot 등을 사용합니다. 또한 이론적인 예측력을 확인하기 위해서 AIC(Akaike Information Criterion), BIC(Bayesian information criterion)와 같은 지표를 살펴봅니다. 새로운 데이터에 대해서도 로버스트한지 확인하기 위해 cross validation기법 등을 사용할 수도 있습니다.
정리하면, 실제 분석 과정은 이와 같은 검증 기법들을 사용하여 적합한 모델을 규명하고, unknown 파라미터를 추정하는 방법을 반복하여 점점 더 좋은 성능의 모델을 찾아내는 방식으로 진행됩니다.
Model Building
1) identify model
2) estimate unknowns
3) diagonstic checking
4) prediction
for 1), 3) use :
- ACF, PACF
- for large - n cases, Box-Ljung test, Sign test, Rank test, q-q plot .. => for the residuals after fitting the model
- theoretical predictive power : AIC, BIC
- empirical predictive power : Cross validation
이번 포스팅에서는 실제 데이터를 이용해 시계열 데이터를 모델링하는 전반적인 과정에 대해서 알아보도록 하겠습니다. 특히 모델을 선택하는데 사용할 지표(AIC, BIC, HQIC)와 검증 방법들(residual’s auto-correlation function, q-q plot)에 대해서 개념적으로 이해하고, statsmodels 패키지에서 출력되는 결과값들을 해석하며 더 나은 성능의 모델을 찾아가는 방법에 대해서 소개하도록 하겠습니다.
실제 데이터 - 초미세먼지 농도
분석할 데이터는 초미세먼지 농도입니다.
- 데이터 : 경남 창원시 의창구 원이대로 450(시설관리공단 실내수영장 앞)에서 측정된 초미세먼지(PM.25)
- 기간 : 2018-9-18 19:00 ~ 2018-12-18 17:00 (3개월, 1시간 단위)
import sqlite3
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from datetime import datetime as dt
import matplotlib.pyplot as plt
import statsmodels.api as sm
% %matplotlib inline
df.pm25Value.plot(figsize=(15,4))
가장 먼저 할일은 시계열 차트를 그려보는 것입니다. Part1에서의 내용들은 모두 시계열 데이터가 stationary하다는 가정이 있습니다. 평균과 분산이 시간에 따라 변하지 않아야합니다.
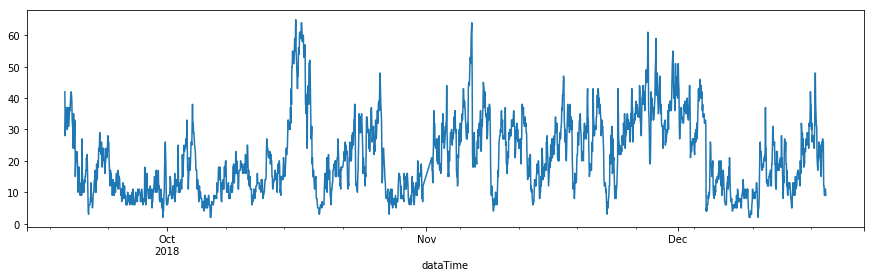
어떻게 보이시나요? 보기에 따라 stationary하다고 판단할수도 있고 그렇지 않다고 할수도 있겠습니다. 특히 9월부터 10월초까지는 대체적으로 초미세먼지의 농도가 낮게 지속된 것으로 보이네요. 그래프를 통해서 stationary를 판단하는 것은 아무래도 주관적인 판단이 개입할수밖에 없습니다.
통계적인 방법으로 stationary를 확인할수 있는 방법도 있습니다.
Augmented Dickey-Fuller test는 단일변량 프로세스에서 unit root가 존재여부를 검증하기 위해서 사용됩니다.
Part1을 잘 보셨다면 causality condition에서 \(\phi(B)\)의 모든 해가 unit circle밖에 존재할 경우, causality를 만족한다는 부분을 기억하실겁니다. causality condition을 만족하는 프로세스는 이에 대응되는 유일한(unique) stationary solution이 한개 존재한다는 것을 보장합니다. Augmented Dickey-Fuller test에서의 귀무가설은 unit root가 존재한다이고 귀무가설을 기각하면 unit root가 존재하지 않는다, 즉 주어진 데이터가 stationary하다는 결론을 얻을 수 있습니다.
statmodels 패키지의 adfuller 함수를 이용해 stationary를 검증해보도록 하겠습니다.
result = sm.tsa.stattools.adfuller(df.pm25Value)
print('ADF Statistic: %f' % result[0])
print('p-value: %f' % result[1])
print('Critical Values:')
for key, value in result[4].items():
print('\t%s: %.3f' % (key, value))
ADF Statistic: -4.860059
p-value: 0.000042
Critical Values:
10%: -2.567
1%: -3.433
5%: -2.863
adfuller 검증 결과, p-value가 0.05 이하로 critical value보다 작기때문에 우리는 귀무가설을 기각할수 있습니다. 이를 통해 주어진 데이터가 stationary하다는 가정이 합리적임을 확인할 수 있습니다.
두번째 단계는 ACF와 PACF를 통해서 데이터에 적합한 모델을 규명하는 것입니다. statmodels의 plot_acf와 plot_pacf함수를 사용할 수 있습니다.
fig = plt.figure(figsize=(12,8))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(df.pm25Value, lags=100, ax=ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(df.pm25Value, lags=100, ax=ax2)
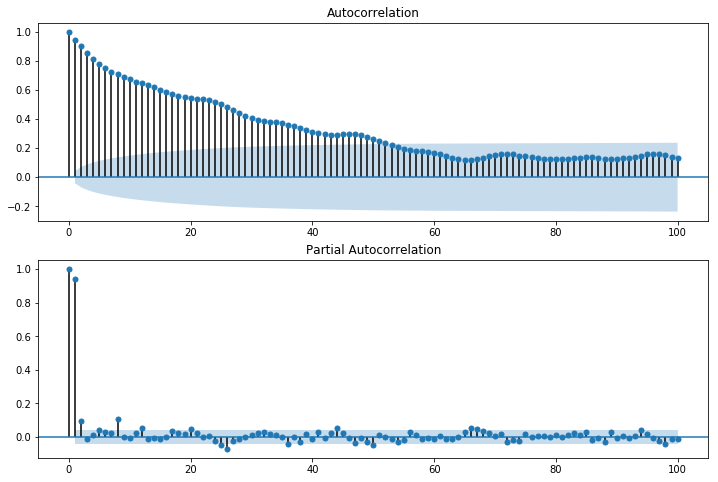
ACF는 lag가 증가할수록 decay 혹은 tail-off 모습을 보입니다. PACF는 lag=1일때 강한 스파이크를 보이고 이후 값들은 제로에 가까운 값들을 보입니다. 이를 토대로 모델을 선정한다면 AR(1)프로세스로 추정할수 있습니다. 다만 PCAF 상에서 \(lag \ge 2\) 값들이 confidence-band에 걸쳐있기때문에 AR(1)이외에 AR(2)와 AR(3)의 가능성도 조금은 열어두도록 하겠습니다.
우선 AR(1)이라는 가정하에 모델의 파라미터를 추정해보도록 하겠습니다. tsa.ARMA(series, order=(p, q))로 ARMA 모델 객체를 만들고, fit 메서드를 이용해 파라미터를 추정할수 있습니다. summary를 통해서 추정된 파라미터의 값과 모델 성능에 대한 지표를 얻을 수 있습니다.
arma_mod10 = sm.tsa.ARMA(df.pm25Value, (1,0)).fit(disp=False)
print(arma_mod10.summary())
ARMA Model Results
==============================================================================
Dep. Variable: pm25Value No. Observations: 2183
Model: ARMA(1, 0) Log Likelihood -6095.592
Method: css-mle S.D. of innovations 3.947
Date: Wed, 26 Dec 2018 AIC 12197.184
Time: 09:39:11 BIC 12214.249
Sample: 09-18-2018 HQIC 12203.422
- 12-18-2018
===================================================================================
coef std err z P>|z| [0.025 0.975]
-----------------------------------------------------------------------------------
const 21.1381 1.512 13.983 0.000 18.175 24.101
ar.L1.pm25Value 0.9446 0.007 134.299 0.000 0.931 0.958
Roots
=============================================================================
Real Imaginary Modulus Frequency
-----------------------------------------------------------------------------
AR.1 1.0587 +0.0000j 1.0587 0.0000
-----------------------------------------------------------------------------
우리가 가정한 모델은 다음과 같습니다.
\[X_t -\phi X_{t-1} = Z_t + const\]const는 상수값으로 모델 평균에 해당합니다. 약 26.4892로 추정되며, 이계수에 대한 p-value가 0.000으로 통계적으로 유의한 수준으로 나타납니다. 또한 \(\phi\)는 이전 데이터에 대한 계수로 0.9589으로 추정되며, 마찬가지로 p-value가 0.000으로 통계적으로 유의합니다.
위 결과 테이블에서 주의깊게 보아야할 것은 AIC, BIC, HQIC입니다. 이 지표들은 추정된 모델의 성능을 이론적으로 나타나낸 값들로 이 지표들의 값이 낮을수록 모델이 데이터를 더 잘 설명하는 모델이됩니다. 세가지 모두 데이터가 가지고 있는 정보량 중 모델에 의해 설명되는 정보량을 빼어 모델이 설명하지 못하는 정보량(손실되는 정보량)의 크기를 측정하는 것입니다. 손실되는 정보량이 적을수록 모델이 본래 데이터가 가진 정보를 그대로 표현하는 것이기때문에 더 나은 모델이라고 할 수 있습니다. 또한 3가지 모두 파라미터의 개수(k)에 따라 penalty를 주어 같은 정보량을 표현하더라도 파라미터가 적은 단순한 모델을 더 나은 모델로 판단하도록 합니다. 세 지표의 차이점은 파라미터수에 따른 penalty를 주는 방법이 다릅니다. (n = number of observation)
\[AIC = -2*ln(maximum likelihood) + 2k \\ BIC = -2*ln(maximum likelihood) + ln(n)*k \\ HQIC = -2*ln(maximum likelihood) + 2k*ln(ln(n))\]더 자세한 내용은 여기를 참고하세요. AIC, BIC, HQIC
arma_mod20 = sm.tsa.ARMA(df.pm25Value, (2,0)).fit(disp=False)
print(arma_mod20.summary())
ARMA Model Results
==============================================================================
Dep. Variable: pm25Value No. Observations: 2183
Model: ARMA(2, 0) Log Likelihood -6087.365
Method: css-mle S.D. of innovations 3.932
Date: Wed, 26 Dec 2018 AIC 12182.729
Time: 09:39:19 BIC 12205.483
Sample: 09-18-2018 HQIC 12191.047
- 12-18-2018
===================================================================================
coef std err z P>|z| [0.025 0.975]
-----------------------------------------------------------------------------------
const 21.1422 1.647 12.839 0.000 17.915 24.370
ar.L1.pm25Value 0.8625 0.021 40.340 0.000 0.821 0.904
ar.L2.pm25Value 0.0869 0.021 4.064 0.000 0.045 0.129
Roots
=============================================================================
Real Imaginary Modulus Frequency
-----------------------------------------------------------------------------
AR.1 1.0487 +0.0000j 1.0487 0.0000
AR.2 -10.9723 +0.0000j 10.9723 0.5000
-----------------------------------------------------------------------------
위 결과는 AR(2)로 가정한 후 파라미터를 추정한 결과입니다.
\[X_t -\phi_1 X_{t-1} -\phi_2 X_{t-2} = Z_t + const\]\(const, \phi_1, \phi_2\)는 각각 21.1422, 0.8625, 0.0869로 추정되며, 모두 p-value가 0.000으로 유의한 수준임을 알수 있습니다.
arma_mod30 = sm.tsa.ARMA(df.pm25Value, (3,0)).fit(disp=False)
print(arma_mod30.summary())
ARMA Model Results
==============================================================================
Dep. Variable: pm25Value No. Observations: 2183
Model: ARMA(3, 0) Log Likelihood -6087.201
Method: css-mle S.D. of innovations 3.931
Date: Wed, 26 Dec 2018 AIC 12184.401
Time: 09:59:51 BIC 12212.843
Sample: 09-18-2018 HQIC 12194.798
- 12-18-2018
===================================================================================
coef std err z P>|z| [0.025 0.975]
-----------------------------------------------------------------------------------
const 21.1413 1.627 12.994 0.000 17.952 24.330
ar.L1.pm25Value 0.8635 0.021 40.245 0.000 0.821 0.906
ar.L2.pm25Value 0.0975 0.028 3.446 0.001 0.042 0.153
ar.L3.pm25Value -0.0123 0.021 -0.573 0.567 -0.054 0.030
Roots
=============================================================================
Real Imaginary Modulus Frequency
-----------------------------------------------------------------------------
AR.1 1.0500 +0.0000j 1.0500 0.0000
AR.2 -6.0083 +0.0000j 6.0083 0.5000
AR.3 12.8897 +0.0000j 12.8897 0.0000
-----------------------------------------------------------------------------
AR(3)는 어떨까요? AR(3)로 가정한 후 파라미터를 추정한 결과입니다.
\[X_t -\phi_1 X_{t-1} -\phi_2 X_{t-2} -\phi_3 X_{t-3} = Z_t + const\]\(const, \phi_1, \phi_2, \phi_3\)는 각각 21.1413, 0.8635, 0.0975, -0.0123로 추정되며, \(\phi_3\)을 제외한 나머지 파라미터는 p-value가 0.000 수준으로 유의한 수준입니다. \(\phi_3\)은 p-value가 0.567로 유의수준(95%신뢰수준, >0.05)보다 크기 때문에, 95%신뢰수준으로는 유의하지 않은 계수로 판단됩니다.
order변화에 따라 AIC와 BIC, HQIC의 값을 정리하면 다음 표와 같습니다. AR(2)모델에서 세 지표 모두 가장 낮은 값을 보이고 있습니다.
| model | AIC | BIC | HQIC |
|---|---|---|---|
| AR(1) | 12197.184 | 12214.249 | 12203.422 |
| AR(2) | 12182.729 | 12205.483 | 12191.047 |
| AR(2) | 12184.401 | 12212.843 | 12194.798 |
좀더 편리하게 statmodels의 AR 모듈에서 제공하는 select_order 메소드를 이용할수도 있습니다. 탐색할 order의 최대값과 평가기준으로 삼을 지표를 지정하면 자동으로 최적은 order를 선택하여 출력해줍니다. 단 order의 최대값이 10이상이 될 경우, 계산속도가 눈에 띄게 늦어지니 주의하시길 바랍니다.
sm.tsa.AR(df.pm25Value).select_order(10, 'aic')
8
aics=[]
bics=[]
hqics=[]
for i in range(10):
model = sm.tsa.ARMA(df.pm25Value, (i+1,0)).fit(disp=False)
print(i+1)
aics.append(model.aic)
bics.append(model.bic)
hqics.append(model.hqic)
1
2
3
4
5
6
7
8
9
10
plt.plot(range(1, 11), aics)
plt.plot(range(1, 11), bics)
plt.plot(range(1, 11), hqics)
plt.legend(['AIC', 'BIC', 'HQIC'])
plt.show()
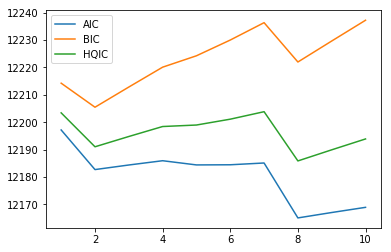
order를 1부터 10까지 변경하면서 모델을 평가해보면 AIC, HQIC 기준으로는 order=8에서 가장 낮은 값을 보이고, BIC 기준으로는 order=2에서 가장 낮은 값을 보입니다.
여기서는 모델의 복잡도를 고려하여 이후 과정은 AR(2)에 대해서만 수행하도록 하겠습니다.
그렇다면 정말 AR(2)가 적합한 모델일까요? 모델의 파라미터를 추정한 이후에는 우리가 가정한 것들이 실제로 그러한지 diagonstic checking이 필요합니다. 특히 실제 값에서 모델의 추정값을 뺀 나머지 잔차(residual)에 대해서 이 잔차가 정규분포를 따르는 white noise인지를 확인해야합니다.
먼저 가로축을 시간으로 하는 잔차를 그려보아 시간에 다른 분포의 변화가 있는지 확인합니다. 또한 t 시점의 residual은 이전, 이후 시점의 residual과 서로 uncorrelate되어야하기 때문에 residual의 ACF와 PACF를 그렸을때, lag=0(자기자신과의 correlation)을 제외하고는 모두 제로에 가까워야합니다.
resid = arma_mod20.resid
fig = plt.figure(figsize=(12,8))
ax = fig.add_subplot(111)
ax = resid.plot(ax=ax)
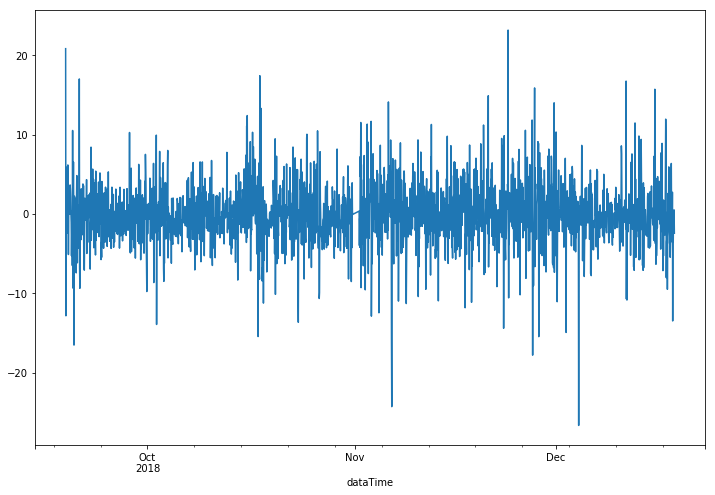
fig = plt.figure(figsize=(12,8))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(resid.values.squeeze(), lags=100, ax=ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(resid, lags=100, ax=ax2)
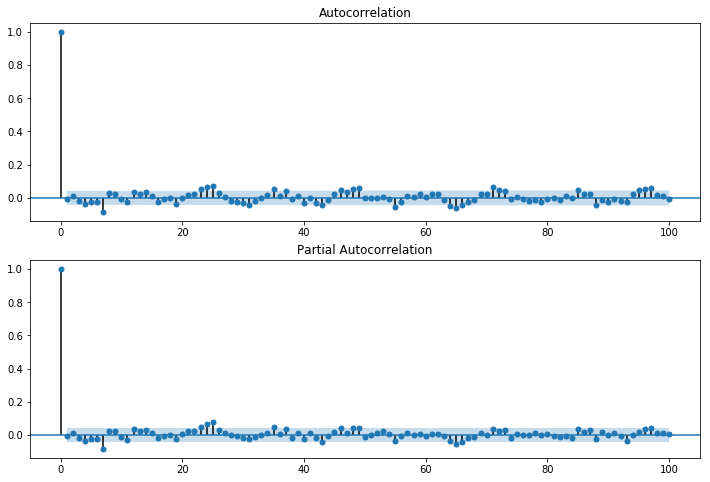
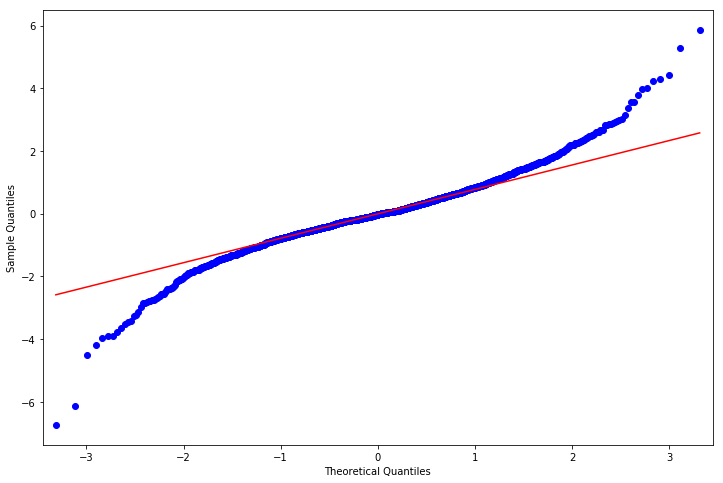
두번째로는 q-q plot을 통해서 정규분포 가정을 확인할 수 있습니다. residual이 정규분포를 따를 경우, q-q plot의 점들은 linear한 모습을 띄어야합니다. q-q plot에 대한 자세한 내용은 여기를 참고하세요.
세번재로는 통계적인 검증 방법으로 scipy의 normaltest를 이용할 수도 있습니다. residual plot이나 q-q plot이 그래프를 통해서 눈으로 확인하는 것이라면, scipy의 normaltest는 skewness와 kurtosis를 이용해 정규성을 통계적으로 검증하는 방법입니다. 이때 귀무가설은 샘플데이터들이 정규분포를 따른다는 것으로 p-value가 유의수준보다 적을 경우, 귀무가설이 기각되어 샘플데이터가 정규분포를 따르지 않는 다는 결론을 얻게 됩니다. 참고를 참고하세요.
fig = plt.figure(figsize=(12,8))
ax = fig.add_subplot(111)
fig = sm.graphics.qqplot(resid, line='q', ax=ax, fit=True)
from scipy import stats
stats.normaltest(resid)
NormaltestResult(statistic=211.93394539357183, pvalue=9.530781075241752e-47)
normaltest의 p-value가 0.05보다 작기때문에 residual이 정규분포를 따른다는 귀무가설을 기각하게 됩니다. 즉 AR(2) 모델을 사용할 경우, white noise가 정규분포를 따른다는 가정이 위배되기 때문에 이는 적합한 모델이 아닐수 있습니다. 실제 분석에서는 이런 경우가 발생할 때는 log transformation(로그변환)이나 differencing(차분)등 합리적인 전처리를 수행하고 전처리된 데이터를 이용해 위의 과정을 반복하여 적합한 시계열 모델을 찾아야합니다.
반복적인 작업을 통해서 적합한 모델이 만들어지면, 이제 이 모델을 이용해 미래값을 예측할 수 있습니다. statmodels의 모델 객체는 predict 메소드를 통해서 미래값을 쉽게 얻을 수 있습니다. dynamic 옵션을 False로 설정하는 것은 항상 in-sample 데이터를 사용하여 미래값을 예측하는 것이고, True로 설정할 경우 이전 lag의 모델 예측값을 사용해서 계산하는 것입니다. 첫번째 예측값을 이후 lag에서 계속 사용하게 됩니다.
predict_pm25 = arma_mod20.predict(2000, 2200, dynamic=False)
print(predict_pm25)
2018-12-11 03:00:00 17.296624
2018-12-11 04:00:00 17.209714
2018-12-11 05:00:00 18.072176
2018-12-11 06:00:00 19.021547
2018-12-11 07:00:00 18.245995
2018-12-11 08:00:00 19.884008
2018-12-11 09:00:00 20.920289
2018-12-11 10:00:00 21.007199
2018-12-11 11:00:00 21.869661
2018-12-11 12:00:00 20.231647
2018-12-11 13:00:00 34.719674
2018-12-11 14:00:00 24.985140
2018-12-11 15:00:00 23.855313
2018-12-11 16:00:00 14.368236
2018-12-11 17:00:00 13.412229
2018-12-11 18:00:00 14.274691
2018-12-11 19:00:00 12.636677
2018-12-11 20:00:00 12.462858
2018-12-11 21:00:00 12.462858
2018-12-11 22:00:00 12.462858
2018-12-11 23:00:00 15.050242
2018-12-12 00:00:00 15.310972
2018-12-12 01:00:00 16.173433
2018-12-12 02:00:00 15.397881
2018-12-12 03:00:00 17.035895
2018-12-12 04:00:00 17.209714
2018-12-12 05:00:00 12.897406
2018-12-12 06:00:00 12.462858
2018-12-12 07:00:00 18.500089
2018-12-12 08:00:00 19.108457
...
2018-12-18 06:00:00 19.623279
2018-12-18 07:00:00 25.232597
2018-12-18 08:00:00 24.891594
2018-12-18 09:00:00 26.529607
2018-12-18 10:00:00 23.253581
2018-12-18 11:00:00 25.493326
2018-12-18 12:00:00 13.679594
2018-12-18 13:00:00 12.462858
2018-12-18 14:00:00 9.875473
2018-12-18 15:00:00 9.614744
2018-12-18 16:00:00 10.477205
2018-12-18 17:00:00 11.426577
2018-12-18 18:00:00 9.788563
2018-12-18 19:00:00 10.294849
2018-12-18 20:00:00 10.800036
2018-12-18 21:00:00 11.279740
2018-12-18 22:00:00 11.737373
2018-12-18 23:00:00 12.173754
2018-12-19 00:00:00 12.589889
2018-12-19 01:00:00 12.986715
2018-12-19 02:00:00 13.365129
2018-12-19 03:00:00 13.725984
2018-12-19 04:00:00 14.070096
2018-12-19 05:00:00 14.398240
2018-12-19 06:00:00 14.711159
2018-12-19 07:00:00 15.009559
2018-12-19 08:00:00 15.294112
2018-12-19 09:00:00 15.565463
2018-12-19 10:00:00 15.824223
2018-12-19 11:00:00 16.070976
Freq: H, Length: 201, dtype: float64
fig, ax = plt.subplots(figsize=(12, 8))
ax1 = fig.add_subplot(211)
ax1 = df.iloc[1800:].plot(ax=ax1)
fig = arma_mod20.plot_predict(2000, 2200, dynamic=True, ax=ax1, plot_insample=False)
ax1.set_title('Dynamic : True - in-sample forecasts are used in place of lagged dependent variables')
ax2 = fig.add_subplot(212)
ax2 = df.iloc[1800:].plot(ax=ax2)
fig2 = arma_mod20.plot_predict(2000, 2200, dynamic=False, ax=ax2, plot_insample=False)
ax2.set_title('Dynamic : False - the in-sample lagged values are used for prediction')
plt.show()
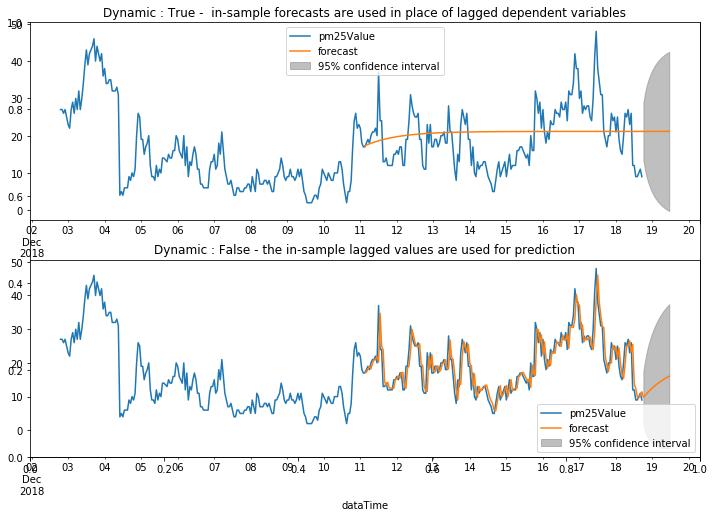
학습한 AR(2)모델을 이용해서 한시간 뒤의 초미세먼지 농도를 예측했을 때, 어느정도로 정확할까요? 회귀분석과 마찬가지로 RMSE 값을 이용해 예측력을 평가할 수 있습니다. AR(2) RMSE가 2.9750로 평균적으로 약 2.9750 ㎍/㎥ 오차가 발생하는 수준입니다.
def mean_forecast_err(y, yhat):
return np.sqrt(y.sub(yhat)**2).mean()
mean_forecast_err(df.pm25Value, predict_pm25)
2.9750026461548287
arma_mod10 = sm.tsa.ARMA(df.pm25Value, (1,0)).fit(disp=False)
predict_pm25 = arma_mod10.predict(2000, 2200, dynamic=False)
print("AR(1) model's RMSE: ", mean_forecast_err(df.pm25Value, predict_pm25))
arma_mod30 = sm.tsa.ARMA(df.pm25Value, (3,0)).fit(disp=False)
predict_pm25 = arma_mod30.predict(2000, 2200, dynamic=False)
print("AR(3) model's RMSE: ", mean_forecast_err(df.pm25Value, predict_pm25))
arma_mod80 = sm.tsa.ARMA(df.pm25Value, (8,0)).fit(disp=False)
predict_pm25 = arma_mod80.predict(2000, 2200, dynamic=False)
print("AR(8) model's RMSE: ", mean_forecast_err(df.pm25Value, predict_pm25))
AR(1) model's RMSE: 3.006486217286414
AR(3) model's RMSE: 2.9717700323027256
AR(8) model's RMSE: 2.9174007777104203
여기까지 실제 데이터와 statmodels 패키지를 이용해 ARMA 모델을 학습하는 방법을 알아보았습니다!
다음 포스팅에서는 non-stationary 모델이 어떤 것들이 있는지 살펴보도록 하겠습니다.
Happy new year!
Reference
Comments