
시계열 분석 part5 - ARMAX, ARFIMA, ARCH, GARCH
지금까지 우리는 시계열 데이터를 설명하기 위해 ARMA모델을 살펴보고, non-stationary 시그널의 경우 differecing을 통해서 stationary 시그널을 얻은 후, ARMA를 적용하는 ARIMA 모델을 공부하였습니다. 또한 여러개의 시그널을 동시에 모델링하도록
Vector AR 모델도 알아보았습니다.
이번 포스팅에서는 1) ARMA 모델에 exogenous(외적 요인) 입력이 추가된 형태인 ARMAX 모델과 2) 자연수 형태였던 difference order를 유리수로 확장하여 long-term memory를 모델링한 ARFIMA 모델, 3) non-linear 모형의 대표적인 예인 ARCH, GARCH에 대해서 설명드리고자 합니다. 각 각의 모델들은 ARIMA 모델들의 확장판으로 기존 모델과의 차이점을 이해하는 것을 목표로 합니다.
ARMAX - ARMA with exogenous inputs
ARMAX는 일반적인 ARMA(p, q) process에 시간따라 변하는 외적 요인(exogenous inputs, \(d_t\))을 추가하여 고려하는 모델입니다. ARMA 모델에 과거 b개의 외적 요인 \(\{d_t\}\)의 선형 조합이 포함되며, 이에 따라 \(\eta_1, ..., \eta_k\)가 모델 파라미터로 추가됩니다.
ARMA(p, q) : \(X_t = Z_t + \sum_{i=1}^p \phi_i X_{t-i} + \sum_{j=1}^q \theta_j Z_{t-j}\)
Definition ARMAX(p, q, b) :
\[X_t = Z_t + \sum_{i=1}^p \phi_i X_{t-i} + \sum_{j=1}^q \theta_j Z_{t-j} + \sum_{k=1}^b \eta_k d_{t-k}\]statsmodels의 시계열 모형 클래스 ARMA, ARIMA, SARIMAX 등은 모두 외부 시계열의 영향을 포함하기 위한 exog 라는 인자를 가지고 있습니다. 이 인자에 외부요인에 해당하는 데이터를 지정해주면 ARMAX 모델이 됩니다.
실제 데이터를 이용한 분석
- 데이터 : 경남 창원시 의창구 원이대로 450(시설관리공단 실내수영장 앞)에서 측정된 초미세먼지(PM2.5)와 인근 북창원의 기상 데이터(온도, 습도)
- 기간 : 2018-11-01 ~ 2018-12-1 (1개월, 1시간 단위)
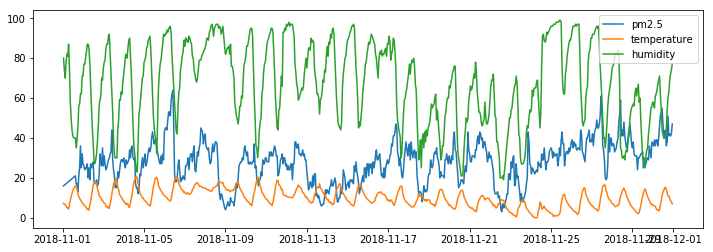
미세먼지 측정 농도는 온도와 습도에 영향을 받습니다. 측정방식에 따른 한게점이기도 하고, 미세먼지 발생량 자체가 온도, 습도 기상 상태에 따라 달라질 수 있기 때문입니다. 따라서 초미세먼지 농도를 예측함에 있어서 해당 시간대의 기상 데이터를 외부 요인으로 사용하여 모델을 추정해보았습니다.
df = df[['pm25Value', 'temp','hm']]
df = np.array(df)
arma_mod30 = sm.tsa.ARMA(df[:,0], (3,0)).fit(disp=False)
predict_pm25 = arma_mod30.predict(dynamic=True)
print("AR(3) model's RMSE: ", mean_forecast_err(df[3:,0], predict_pm25))
armax_mod30 = sm.tsa.ARMA(df[:,0], (3,0), exog=df[:,1:]).fit(disp=False)
predict_pm25 = armax_mod30.predict(dynamic=True)
print("ARX(3) model's RMSE: ", mean_forecast_err(df[3:,0], predict_pm25))
output :
AR(3) model's RMSE: 8.036039331569588
ARX(3) model's RMSE: 7.710071937116329
추정결과, 예측정확도를 평가하는 RMSE가 0.3 줄어든 것을 볼수 있습니다. 외부 요인을 도입함으로서 예측 성능을 높일 수 있다는 것을 보여주는 결과입니다.
ARFIMA - Autoregressive fractionally integrated moving average
일반적인 ARMA(p, q)모델은 ACF가 빠르게 감소하는 모습을 띕니다. 이러한 형태를 short-term memory process라고 합니다.
하지만 실제 사례에서의 시그널의 ACF는 이상적인 것처럼 빠르게 감소하지 않습니다. 이 경우, Part3에서 알아본 것처럼 differencing 등을 통해서 이상적인 성질(fast dacaying ACF)을 갖는 새로운 시그널로 변환하여 모델링한다고 설명하였지만, differencing을 반복적으로 수행하더라도 여전히 ACF가 long tail 형태를 띄는 경우가 있습니다. 이를 long-term memory process라고 하며, ARFIMA 모델을 사용합니다.
Definition
\[(1-B)^d X_t = Z_t, \ \ \ \ \ 0 \lt d \lt \frac{1}{2}\]ARIMA의 \((1-B)^d\) 부분은 d가 양수로 몇번의 differencing을 수행할것인지를 의미했습니다. 하지만 ARFIMA모델에서는 d가 0과 1/2 사이의 유리수라는 점이 다릅니다. 여기서 \((1-B)^d\)는 “fractionally differenced”된 \(\Phi(B)\) 라고 부릅니다.
ACF of \(X_t\):
\[\rho(h) = \frac{\Gamma(h+d)\Gamma(1-d)}{\Gamma(h-d+1)\Gamma(d)} \sim h^{2d-1} \ for \ large \ h\] \[\sum_{h=-\infty}^{\infty} |\rho(h)| = \infty\]위와 같이 모든 lag에 대한 ACF를 모두 더하면 \(\infty\)가 되기 때문에, 이를 long-term memory process를 설명할 수 있습니다. 추정해야할 모델 파라미터는 \(d\)가 되며, 일반적인 ARFIMA(p, d, q)는 다음과 같습니다.
statsmodels에는 ARFIMA 기능이 지원되지 않아, 분석 사례는 생략하도록 하겠습니다.
ARCH
앞서 살펴본 모델들은 {X_t}가 이전 값 혹은 white noise 등 과의 선형(linear) 조합으로 설명되는 경우였습니다. 지금부터는 non-linear 모델의 대표적인 예인 ARCH와 GARCH를 소개하도록 하겠습니다. 먼저 ARCH(autoregressive conditional heteroskedasticity) 모델은 다음과 같이 정의됩니다.
Definition
\[\begin{align} X_t & = \sigma_t * Z_t \\ \sigma_t^2 & = \alpha_0 + \sum_{I=1}^p \alpha_i x_{t-i}^2 \end{align}\]ARCH(p)를 이해하기 위해서 평균과 분산을 살펴보겠습니다.
\[\begin{align} E[X_t \vert X_{t-1}, X_{t-2}, …] & = E[\sigma_t * Z_t \vert X_{t-1}, X_{t-2}, …] \\ & = \sigma_t E[ Z_t \vert X_{t-1}, X_{t-2}, …] \\ & = 0 \\ \\ E[X_t] & = E_{X_{t-1}, X_{t-2}, …}[E_{X_t \vert X_{t-1}, X_{t-2}, …} [X_t] ] \\ &= 0\\ \\ Var[X_t \vert X_{t-1}, X_{t-2}, …] & = E[X_t^2 \vert X_{t-1}, X_{t-2}, …] \\ & = E[ \sigma_t^2Z_t^2 \vert X_{t-1}, X_{t-2}, …] \\ & = \sigma_t^2 E[ Z_t^2 \vert X_{t-1}, X_{t-2}, …] \\ & = \sigma_t^2 \\ \\ Cov[X_{t+h}, X_t] & = E[X_{t+h} X_t] \\ & = E_{X_{t+h-1}, X_{t+h-2}, …}[X_t E_{X_{t+h} \vert X_{t+h-1}, X_{t+h-2}, …} [X_{t+h}] ]\\ & =0 \end{align}\]\(\{X_t\}\)의 평균은 0이고, lag=h인 관측값간의 공분산은 0입니다. 즉 시간에 따라 변하지 않는 성질을 가지고 있습니다. (\(\{X_t\}\)가 white noise라는 것을 의미합니다) 하지만 \(Var[X_t]=\sigma_t^2\)이기때문에, nonstationary합니다. \(\sigma_t^2\)를 volatility 라고 부르기도 합니다.
example
ARCH(1) : \(\left\{ \begin{align} X_t & = \sigma_t * Z_t \\ \sigma_t^2 & = \alpha_0 + \alpha_1 X_{t-1}^2 \\ \end{align} \right.\)
첫번째 식을 제곱한 후, 두 식을 빼면 다음과 같습니다.
\[\begin{align} X_t^2 & = \sigma_t^2 * Z_t^2 \\ \alpha_0 + \alpha_1 X_{t-1}^2 & = \sigma_t^2 \\ X_t^2 - (\alpha_0 + \alpha_1 X_{t-1}^2) & = \sigma_t^2(Z_t^2 - 1) \\ X_t^2 & = \alpha_0 + \alpha_1 X_{t-1}^2 + \sigma_t^2(Z_t^2 - 1) \end{align}\]마지막 수식을 살펴보면 \(\{X_t^2\}\) 가 직전 값인 \(\{X_{t-1}^2\}\)에 영향을 받는 auto-regressive 형태로 설명됩니다. 즉, ARCH(1) 모델은 \(\{X_t^2\}\)가 AR(1)인 프로세스와 동일한 것을 알 수 있습니다. 다만 AR(1)의 noise가 non-Gaussian인 것은 주의해야합니다.
ARCH(p) 모델에서 추정해야하는 모델 파라미터는 \(\alpha_0, \alpha_1\)으로 Maximum Likelihood Estimation(MLE)를 이용해 추정합니다.
ARCH(p) 모델을 앞서 살펴본 linear 모델들과 합친 joint ARCH model도 생각해볼수 있습니다. 예를 들어, AR(1)-ARCH(1) 모델은 다음과 같습니다.
example
AR(1)-ARCH(1) : \(\{X_t\}\)는 AR(1) process이고, \(\{Z_t\}\)가 ARCH인 모델
\[\left\{ \begin{align} X_t & = \phi X_{t-1} + Z_t \\ \sigma_t^2 & = \alpha_0 + \alpha_1 Z_{t-1}^2 \\ \end{align} \right.\]Generalized ARCH(GARCH)
GARCH는 ARCH 모델의 \(\sigma_t^2\)에 auto-regressive한 성질을 추가한 것입니다.
example
GARCH(1, 1) : \(\left\{ \begin{align} X_t & = \sigma_t * Z_t \\ \sigma_t^2 & = \alpha_0 + \alpha_1 X_{t-1}^2 + \beta_1 \sigma_{t-1}^2 \\ \end{align} \right.\)
일반적인 GARCH(p, q) 모델은 다음과 같습니다.
Definition
\[\begin{align} X_t & = \sigma_t * Z_t \\ \sigma_t^2 & = \alpha_0 + \sum_{i=1}^p \alpha_i X_{t-i}^2 + \sum_{j=1}^q \beta_j \sigma_{t-j}^2 \end{align}\]\(\{X_t\}\)가 ARCH(p) 모델일 경우, \(\{X_t^2\}\)는 AR(p)모델이 된다는 것을 앞서 설명드렸습니다. 마찬가지로, \(\{X_t\}\)가 GARCH(p, q) 모델일 경우, \(\{X_t^2\}\)는 ARMA(p, q)모델이 됩니다.
실제 데이터를 이용한 분석
ARCH 계열의 모델에 적합한 시계열 데이터은 그 자체로는 auto-correlation 관계가 없지만, 데이터의 제곱값간의 auto-correlation이 존재하는 경우입니다. 주가의 수익률이 대표적인 ARCH모델에 설명되는 시계열 데이터입니다.
여기서는 ARCH모델을 이용해 주가의 수익률을 예측해보았습니다.이 분석 사례를 참고하여 작성하였습니다.
import pandas_datareader.data as web
import datetime as dt
st = dt.datetime(1990,1,1)
en = dt.datetime(2016,1,1)
data = web.get_data_yahoo('^GSPC', start=st, end=en)
returns = 100 * data['Adj Close'].pct_change().dropna()
returns.plot(figsize=(15,4))
plt.show()
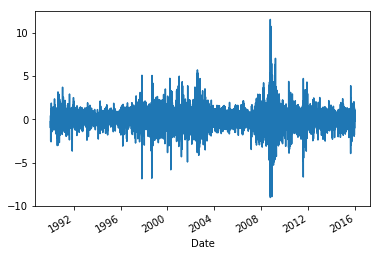
수익률 그 자체로는 자기 상관관계가 없지만, 수익률의 제곱값은 자기 상관관계를 갖고 있는 것을 볼 수 있습니다.
sm.graphics.tsa.plot_acf(returns - returns.mean(), lags=100)
plt.show()
sm.graphics.tsa.plot_acf((returns - returns.mean())**2, lags=100)
plt.show()
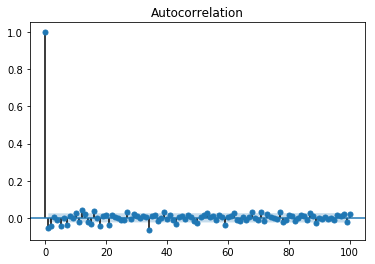
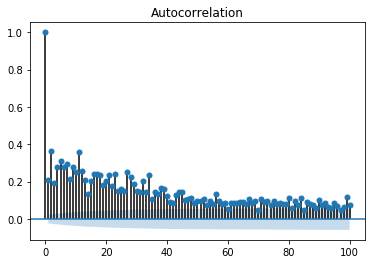
ARCH모델은 파이썬의 arch패키지를 통해서 사용할 수 있습니다. ARCH(1)모델로 추정해보도록 하겠습니다.
from arch import arch_model
am1 = arch_model(returns, p=1, q=0)
res1 = am1.fit()
print(res1.summary())
output :
Iteration: 1, Func. Count: 5, Neg. LLF: 10051.187042085134
Iteration: 2, Func. Count: 14, Neg. LLF: 10047.115662777182
Iteration: 3, Func. Count: 23, Neg. LLF: 9820.333972115874
Iteration: 4, Func. Count: 29, Neg. LLF: 9810.75544390718
Iteration: 5, Func. Count: 35, Neg. LLF: 9804.073095175208
Iteration: 6, Func. Count: 40, Neg. LLF: 9801.645677600663
Iteration: 7, Func. Count: 45, Neg. LLF: 9801.613667614067
Iteration: 8, Func. Count: 50, Neg. LLF: 9801.613523562157
Iteration: 9, Func. Count: 55, Neg. LLF: 9801.613520460578
Optimization terminated successfully. (Exit mode 0)
Current function value: 9801.613520460529
Iterations: 9
Function evaluations: 55
Gradient evaluations: 9
Constant Mean - ARCH Model Results
==============================================================================
Dep. Variable: Adj Close R-squared: -0.000
Mean Model: Constant Mean Adj. R-squared: -0.000
Vol Model: ARCH Log-Likelihood: -9801.61
Distribution: Normal AIC: 19609.2
Method: Maximum Likelihood BIC: 19629.6
No. Observations: 6552
Date: Sat, Jan 19 2019 Df Residuals: 6549
Time: 17:13:45 Df Model: 3
Mean Model
============================================================================
coef std err t P>|t| 95.0% Conf. Int.
----------------------------------------------------------------------------
mu 0.0482 1.487e-02 3.239 1.202e-03 [1.902e-02,7.732e-02]
Volatility Model
========================================================================
coef std err t P>|t| 95.0% Conf. Int.
------------------------------------------------------------------------
omega 0.9115 4.354e-02 20.935 2.568e-97 [ 0.826, 0.997]
alpha[1] 0.3147 4.866e-02 6.467 9.971e-11 [ 0.219, 0.410]
========================================================================
Covariance estimator: robust
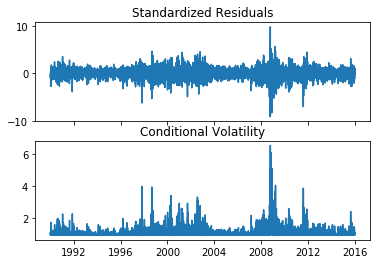
res1.plot()
Reference
[1] Introduction to Time Series and Forecasting, Peter J. Brockwell, Richard A. Davis,
[2] Statsmodel’s Documentation
[4] https://en.wikipedia.org/wiki/Autoregressive_fractionally_integrated_moving_average
[5] https://en.wikipedia.org/wiki/Autoregressive%E2%80%93moving-average_model#ARMAX
[6] https://en.wikipedia.org/wiki/Autoregressive_conditional_heteroskedasticity
[7] https://datascienceschool.net/view-notebook/dac8a9bfac6740ff85d5b6dcc9e9e908/
Comments