
Self-Supervised Generative Adversarial Networks
Ting Chen et al. (Google Brain, 2018)
Abstract
- Conditional GAN은 이미지 생성에서 탁월한 성능을 보이지만, 많은 양의 라벨링 데이터를 필요로 한다는 단점이 있습니다.
- 이 논문은 self-supervision learning과 adversarial training 기법을 적용하여 별도의 라벨링 없이도 image representations을 학습하고 좋은 품질의 이미지를 생성할 수 있음을 보였습니다.
Introduction
- GAN의 학습은 고차원의 파라미터 공간에서 non-convex 게임의 내쉬 이퀼리브리움을 찾는 것이기때문에 매우 불안정한다는 단점은 잘 알려져있습니다.
- 학습이 불안정한 현상을 보이는 이유는 generator와 discrimator가 non-stationary environment 에서 학습되기 때문입니다. 특히 discriminator는 fake class의 분포가 계속 변하게 되어 학습에 어려움을 겪습니다. Non-stationary 환경에서는 뉴럴넷은 이전에 학습 정보를 잊어버리고, 만약 discriminator가 이전의 분류 바운더리를 잊어버리면 학습 과정이 불안정(unstable)해지거나 주기적(cyclic)인 현상이 나타납니다.
- 이 현상을 극복하기 위해서 이전 연구들은 주로 conditioning 기법을 사용하였습니다. Supervised information(클래스 라벨)을 이용해 discriminator를 학습시키면 학습이 더 안정되고 catastrophic forgetting같은 현상이 경감됩니다.
- 하지만 기존 방식은 많은 양의 라벨링 데이터가 필요합니다. 또한 라벨링데이터가 있다하더라도 굉장히 sparse하기 때문에 고차원의 추상화된 공간을 모두 커버하기에는 한계가 존재합니다.
Contribution
- 이 논문은 라벨링된 데이터 없이 conditioning기법의 장점을 이용하고자 기존 GAN에 self-supervised loss를 더한 Self supervised GAN(SSGAN)을 제안하였습니다.
- 실험을 통해서 self-supervised GAN(SSGAN)이 동일한 실험 조건에서는 unconditional GAN보다 더 좋은 성능을 보임을 확인하였습니다.
- SSGAN은 향후 high quality, fully unsupervised, natural image synthesis의 새로운 가능성을 제시하였습니다.
A key Issue : discriminator forgetting
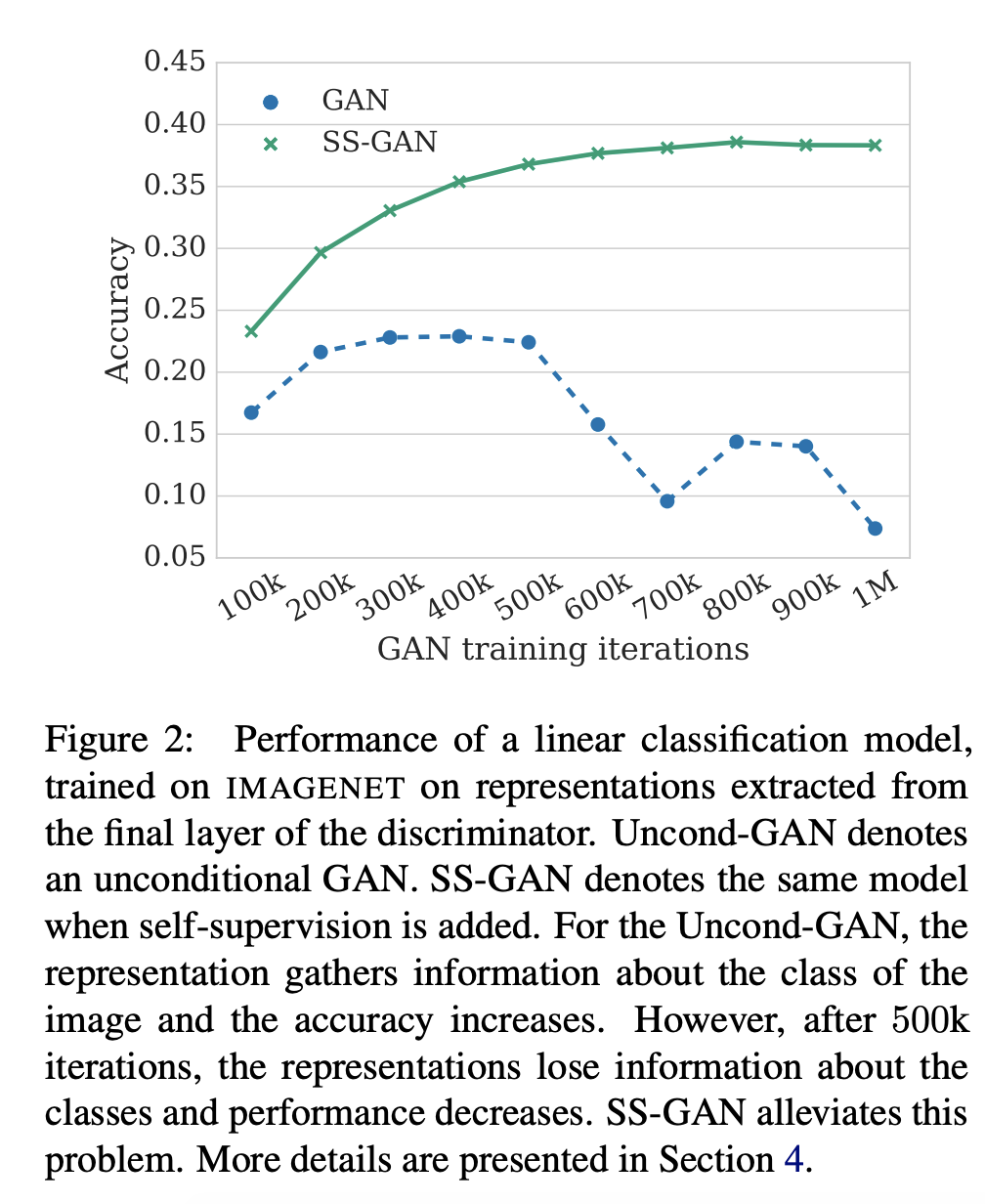
- Fig2 : 학습이 진행될동안 discriminator의 분류 정확도를 관찰한 결과, unconditional GAN은 500k iterations 이후에는 학습된 정보를 잃어버리고 성능이 낮아지는 현상이 일어났습니다. 반면 SSGAN은 학습이 지속됨에 따라 분류 성능도 점차 향상하는 것을 볼 수 있었습니다. (이미지넷 데이터)
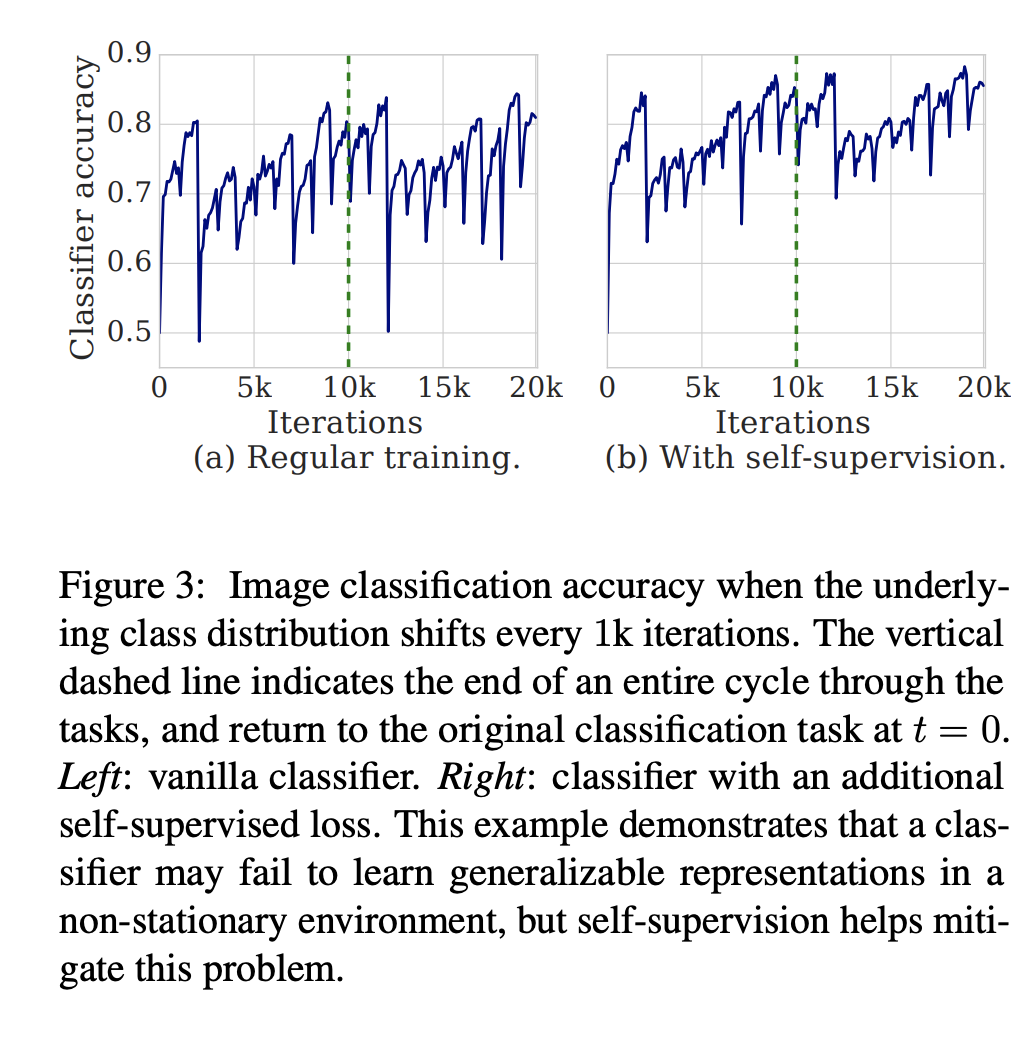
- Fig3 : cifar10 데이터에 대해서 각 클래스마다 1k iterations을 학습시키고 10개 클래스에 대해서 10k iterations이 지나면, 다시 처음 클래스를 학습하는 실험을 하였습니다. (a)는 바닐라 클래시파이어로 10k 이후에도 클래스가 바뀔때마다 학습성능이 떨어졌다가 올라가는 모습이 나타나지만, (b)self-supervised loss가 추가된 클래시파이어는 이전 정보를 잃어버리는 현상이 완화된 것을 볼 수 있습니다.
The Self-Supervised GAN
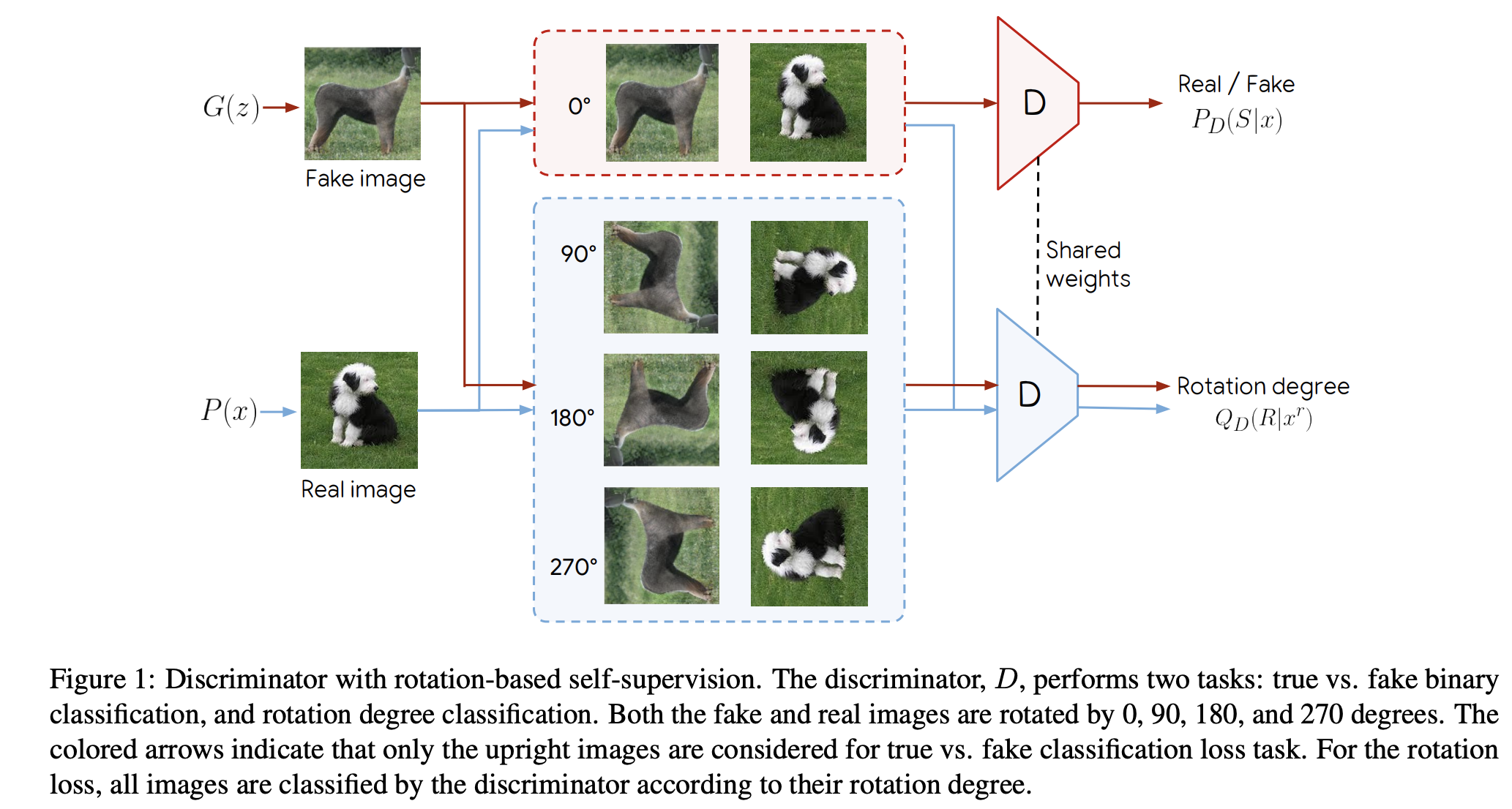
-
Fig1 : SSGAN의 구조는 discriminator가 generator의 학습성능과 상관없이 의미있는 representation을 학습하도록 되어있습니다. 이를 위해서 이미지를 회전시킨 후 회전된 각도를 예측하도록 하는 self-supervision task을 사용하였습니다.
-
회전각도를 예측하는 것을 포함한 loss function은 다음과 같습니다.
- \(V(G,D)\)은 GAN의 loss function이고, \(r \in R\)은 회전각입니다. 이 논문에서는 \(R={0도, 90도, 180도, 270도}\)을 사용하였습니다. 이미지 x가 r degree만큼 회전한 것을 \(x^r\)이라고 나타냈으며, \(Q(R \vert x^r)\)은 주어진 샘플에 대해서 discriminator의 회전각 예측 분포를 의미합니다.
Collaborative Adversarial Training
-
SSGAN에서는 기존 GAN과 마찬가지로 true vs. fake prediction에서는 적대적인 학습을 합니다. 하지만 rotation task에서는 discriminator와 generator가 서로 협력적인 (collaborative) 학습을 하게 됩니다.
- 먼저 generator가 실제 이미지와 유사하게 이미지를 생성하여 회전시킨 후 discriminator에게 전달하면, discriminator는 회전된 각도를 감지하게 됩니다. 여기서 generator는 조건부 정보(rotation)을 사용하지 않으므로 항상 회전되지 않은 unright 이미지를 생성합니다.
- discriminator는 실제 데이터에 대해서만 rotation 을 얼마나 정확하게 예측했는지를 기준으로 학습됩니다. 즉 실제 데이터에 대한 rotation loss만 반영하여 파라미터가 업데이트 됩니다.
-
generator는 회전을 쉽게 감지할수 있도록 이미지를 생성하여 discriminator가 회전을 잘 감지할수있도록 도와줍니다. (discriminator는 실제 이미지의 로테이션을 잘 감지하도록 학습되었기때문에)
- Fig1은 학습과정의 파이프라인을 나타냅니다.
- discriminator의 목적은 1) non-rotated img에 대해서 true or fake를 잘 맞추는 것 2) rotated real img에 대해서 rotation angle을 잘 찾는 것 입니다.
- generator의 목적은 실제 데이터와 유사하게 이미지를 생성하는 것인데, discrimator가 실제 데이터의 로테이션을 잘 감지되도록 학습했기때문에 generator도 회전을 쉽게 감지할수 있는 이미지를 생성하게 됩니다.
Experiments
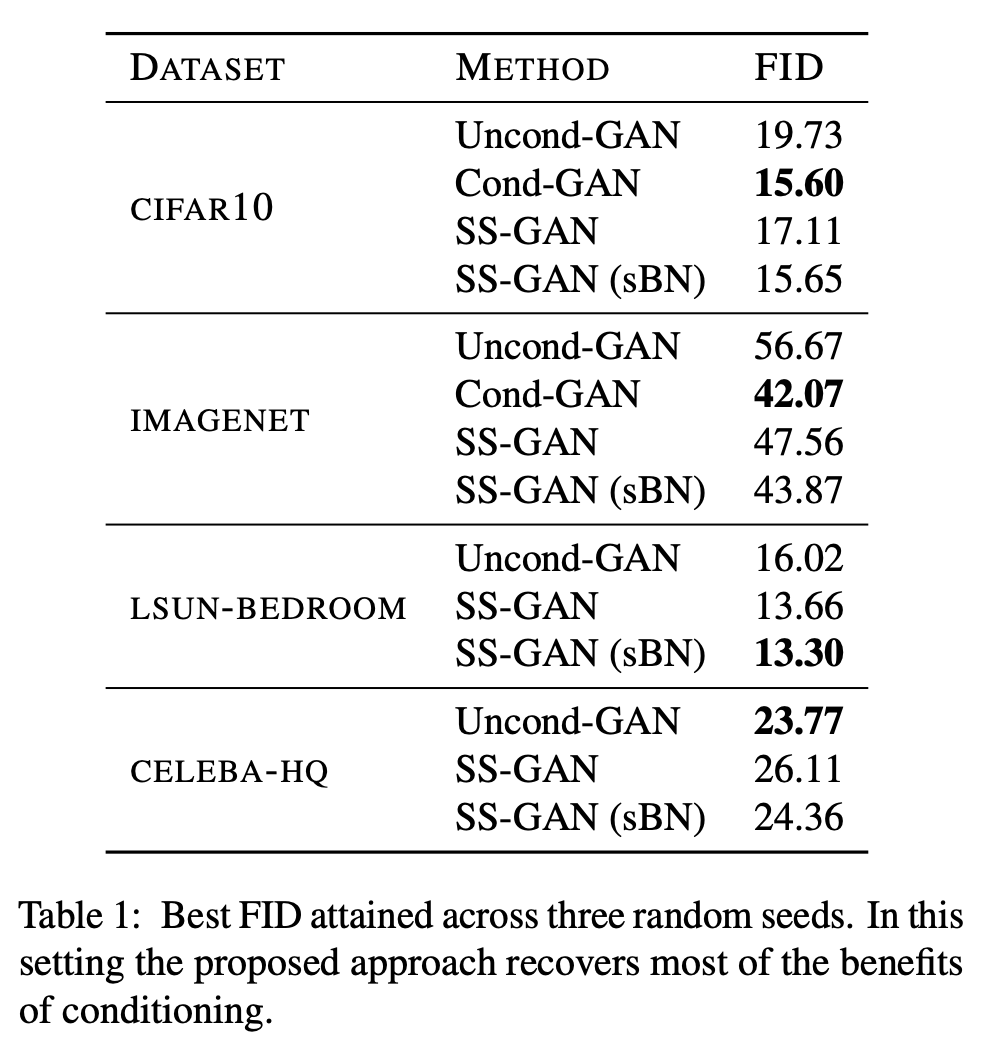
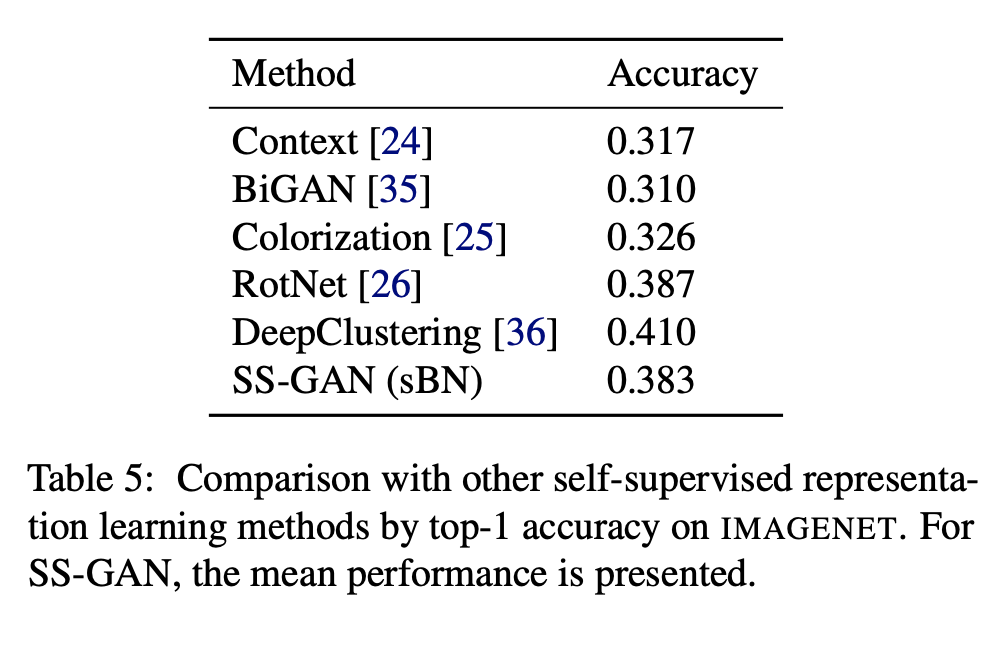
- 실험을 통해서 1) self-supervision이 baseline GAN과 비교하여 representation의 품질을 향상시킴 2) 동일한 학습 조건에서 conditional GAN과 비교가능 수준으로 conditional generation을 향상시킴 을 보였습니다.
Experimental settings
- dataset : IMAGENET, CIFAR10, LSUN-BEDROOM, CELEBA-HQ
- Models :
- baseline models
- unconditional GAN with spectral normalization (Uncond-GAN)
- conditional GAN using the label-conditioning strategy (Cond-GAN)
- label-conditional batch normalization in Cond-GAN
- ResNet architectures for the genertor and discriminator
- self-modulated batch normalization in SS-GAN(sBN)
- baseline models
Results
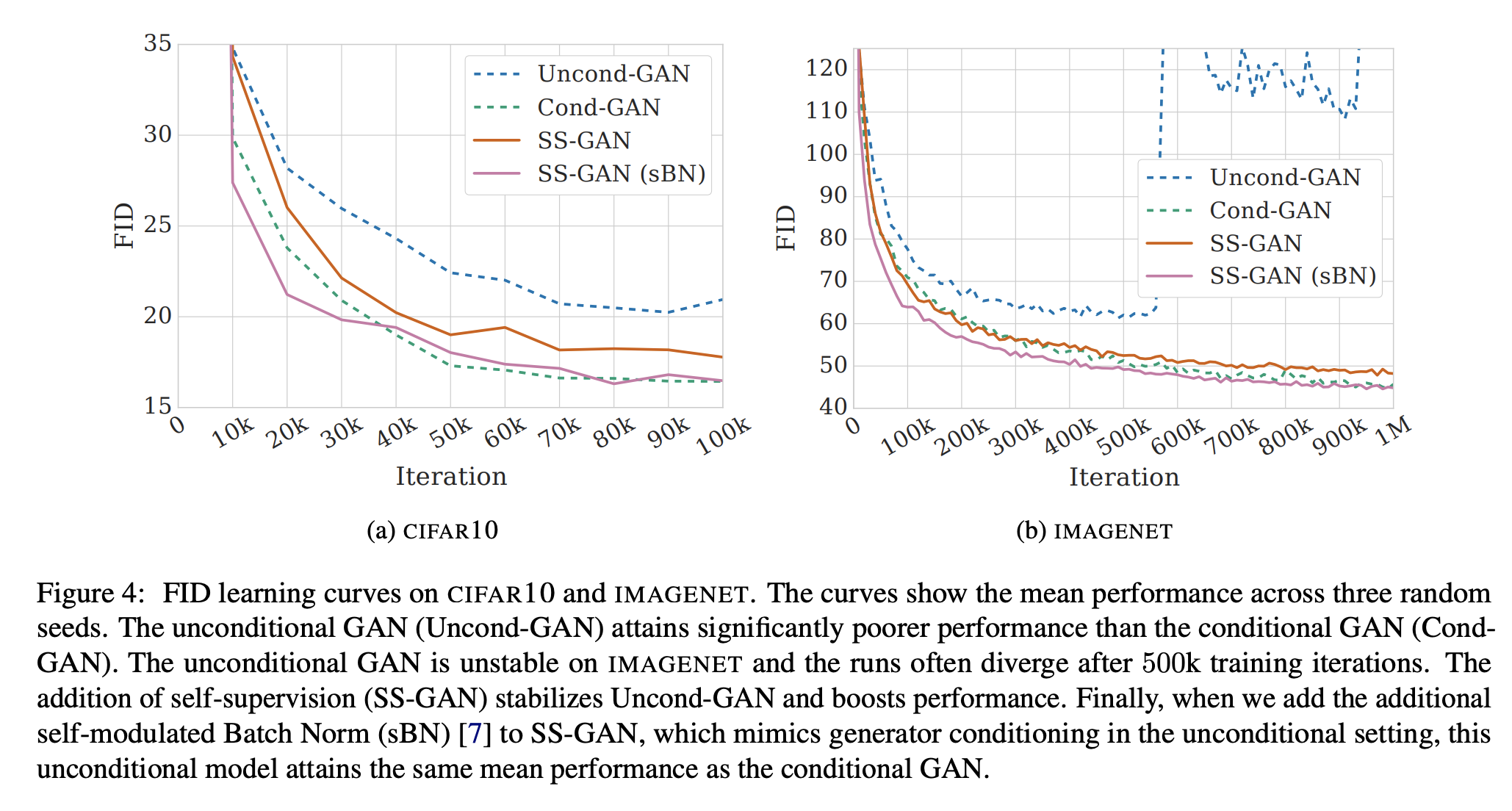

Comments