
시계열 분석 part6 - Spectral analysis
지금까지 우리는 time domain에서의 여러가지 시계열 모델을 살펴보았습니다. 이번 포스팅은 주어진 시계열 데이터를 frequency domain에서 분석하는 방법에 대해서 설명하도록 하겠습니다. 수학적으로 다소 복잡해보이지만, 실제로는 numpy 등을 통해서 쉽게 활용할수 있는 방법입니다. 여기서는 이론적인 내용을 통해서 주파수 도메인에서의 개념을 직관적으로 이해하고, 실제 데이터를 통해서 결과값을 이해하고 활용할 수 있는 것을 목표로 합니다. 주파수 분석은 주어진 시계열 데이터의 주기성을 확인하거나, 노이즈를 제거하는 등에 활용될 수 있습니다.
What we can do with spectral analysis is
- Frequency detection
- Noise removal
- Model detection
- Lag detection (lagged regression)
- Feature detection
Time domain에서의 시계열 데이터는 특정 시점의 데이터가 과거 시점의 데이터와 어떤 관계가 있는지를 알아보기 위해서 auto covariance function(ACF)을 이용하였습니다. 먼저, Time domain에서의 ACF가 frequency domain에서의 spectral density \(f\)로 변형될수 있음(interchangeable)을 살펴보도록 하겠습니다.
spectral density
Definition
Suppose that \(\{X_t\}\) is a zero-mean stationary time series with auto covariance function \(\gamma(\cdot)\) satisfying \(\sum_{h=-\infty}^\infty \left\vert \gamma(h) \right\vert \lt \infty\). The spectral density of \(\{X_t\}\) is the function \(f(\cdot)\) defined by
\[f(\lambda) = \frac{1}{2\pi} \sum_{h=-\infty}^\infty e^{-ih\lambda} \gamma(h), \ \ \ \ -\infty \lt \lambda \lt \infty\]where \(e^{ i\lambda} = cos(\lambda) + i sin(\lambda)\) and \(i = \sqrt{-1}\).
\(\left\vert \gamma(\cdot) \right\vert\)의 summability로 인해 \(f\) 역시 절대적으로 수렴하며, cos와 sin의 주기가 \(2\pi\)이기때문에 \(f\)의 주기도 \(2\pi\)가 됩니다. 또한 앞으로의 수식에서는 \((-\pi, \pi]\) 구간에서의 \(f\)의 값만 고려하도록 하겠습니다.
Basic Properties of \(f\)
(a) \(f\) is even, i.e., \(f(\lambda) = f(-\lambda)\)
(b) \(f(\lambda) \ge 0\) for all \(\lambda \in (-\pi, \pi]\),
and
(c) \(\gamma(k) =\int_{-\pi}^\pi e^{ik\lambda} f(\lambda) d\lambda = \int_{-\pi}^\pi cos(k\lambda) f(\lambda) d\lambda\)
\(f(\lambda)\)는 대칭성을 가지고 있고, \((-\pi, \pi]\)에서 항상 양수값을 갖습니다. 그리고 spectral density를 (c)와 같이 적분하여 타임 도메인의 auto covariance function으로 변환할 수 있습니다.
즉, \(\gamma_X\)가 가진 정보와 \(f_X(\lambda)\)가 가진 정보가 완전히 동일합니다. 또한 spectral densities는 essentially unique하기 때문에 \(\gamma(\cdot)\)에 대응되는 Spectral densities \(f\)와 \(g\)가 있다면, 이 둘은 \(f\)와 \(g\)는 서로 동일한 Fourier coefficients를 갖게 되어, 서로 동일한 함수라고 할수 있습니다.
다음은 우리가 알고 있는 몇개의 stationary time series의 sepectral density를 구하는 예제를 살펴보도록 하겠습니다.
Example
White noise : If \(\{X_t\} \sim WN(0, \sigma^2)\), then \(\gamma(0)=\sigma^2\) and \(\gamma(h)=0\) for all \(\left\vert h \right\vert \gt 0\). This process has a flat spectral density
\[f(\lambda) = \frac{\sigma^2}{2\pi}, \ \ \ \ \ \ -\pi \gt \lambda \gt \pi\]Each Frequency in the spectrum contributes equally to the variance of the process.
AR(1): If \(X_t = \phi X_{t-1} + Z_t\) where \(\{Z_t\} \sim WN(0, \sigma^2)\), then \(\{X_t\}\) has spectral density
\[\begin{align} f(\lambda) & = \frac{\sigma^2}{2\pi(1-\phi^2)} (1 + \sum_{h=1}^\infty \phi^h (e^{-ih\lambda} + e^{ih\lambda})) \\ & = \frac{\sigma^2}{2\pi(1-\phi^2)} (1 + \frac{\phi e^{i\lambda}}{1- \phi e^{i\lambda}} + \frac{\phi e^{-i\lambda}}{1- \phi e^{-i\lambda}}) \\ & = \frac{\sigma^2}{2\pi} (1 -2\phi cos \lambda + \phi^2)^{-1} \end{align}\]MA(1): If \(X_t = Z_t + \theta Z_{t-1}\) where \(\{Z_t\} \sim WN(0, \sigma^2)\), then \(\{X_t\}\) has spectral density
\[\begin{align} f(\lambda) & = \frac{\sigma^2}{2\pi} (1 + \theta^2 + \theta(e^{-i\lambda} + e^ {i\lambda})) \\ & = \frac{\sigma^2}{2\pi} (1 + 2\theta cos \lambda + \theta^2) \end{align}\]ARMA(p, q) : If \(\{X_t\}\) is a causal ARMA(p, q) process satisfying \(\phi(B)X_t = \theta(B)Z_t\), then
\[f_X(\lambda) = \frac{\sigma^2}{2\pi} \frac{\left\vert \theta(e^{-i\lambda})\right\vert ^2}{\left\vert \phi(e^{-i\lambda})\right\vert ^2}\]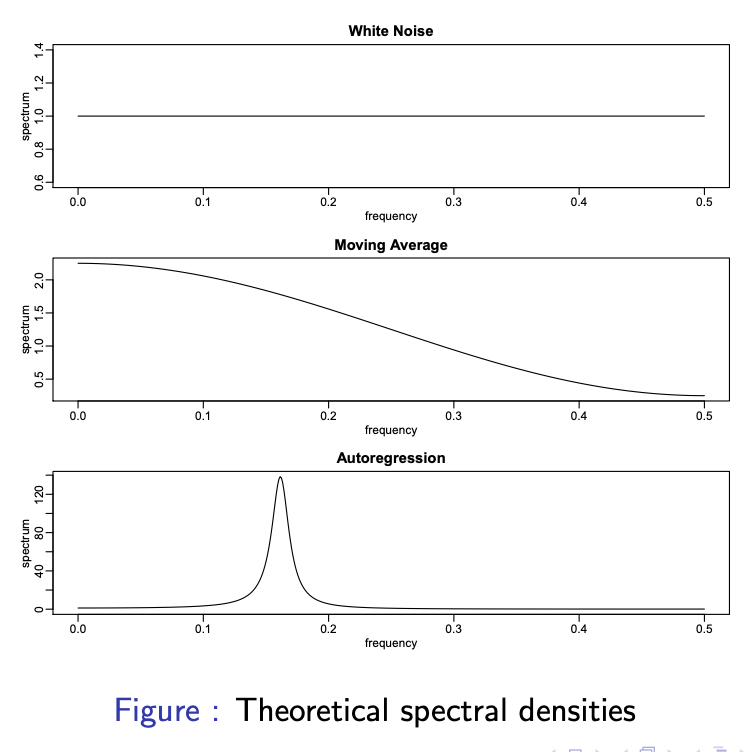
출처 : Time Series Analysis Lecture Note
여기까지 주어진 시계열데이터의 타임 도메인에서의 auto-covariance function이 주파수 도메인의 spectral density function으로 변환가능함을 살펴보았습니다. 앞서 우리는 시계열 데이터의 샘플들로부터 sample ACF를 추정하는 방법을 알아보았습니다. 마찬가지로 주어진 샘플데이터로부터 spectral density function을 추정하는 것은 어떻게 할까요? 이제 시계열 데이터의 spectral density function의 estimate인 periodogram에 대해서 알아보도록 하겠습니다.
Periodogram
먼저 periodogram을 설명하기 위해 복소수 벡터 \(x\)를 생각해보도록 하겠습니다.
여기서 \(\mathbb{C^n}\)는 복소수를 포함한 가능한 모든 컬럼벡터의 집합을 의미합니다. 이제 \(w_k = 2 \pi k/n\)라고 표기하고, 여기서 \(k\) 는 -(n-1)/2와 n/2 사이의 (inclusive) 자연수라고 하겠습니다. 즉,
\[w_k = \frac{2\pi k}{n}, \ \ \ k = -[\frac{n-1}{2}], \cdots, [\frac{n}{2}],\][y]라는 표기는 y보다 작거나 같은 가장 큰 자연수를 나타냅니다.
\(w_k\)와 같은 값들의 집합 \(F_n\)를 샘플사이즈가 n인 Fourier frequencies 라고 합니다. 이때, \(F_n\) 는 \((-\pi, \pi]\) 구간의 부분집합으로 표현됩니다.
마찬가지로 아래와 같은 n개의 벡터를 생각해보도록 하겠습니다.
\[e_k = \frac{1}{\sqrt{n}} \begin{bmatrix} e^{iw_k} \\ e^{2iw_k} \\ \vdots \\ e^{niw_k} \end{bmatrix}, \ \ \ \ \ k = -[\frac{n-1}{2}], \cdots, [\frac{n}{2}].\]여기서 \(e_1, \cdots, e_n\) 는 아래와 같은 관계를 만족시키는 서로 수직(orthonormal)인 벡터들입니다.
\[e_j * e_k = \begin{cases} 1, & \mbox{if } j =k \\ 0, & \mbox{if } j \ne k \end{cases}\]\(e_j *\)는 \(e_j\)의 k번째 컴포넌트를 복소수 컨주게이트값으로 바꾼 행벡터를 타나냅니다. row vector whose \(k\)th component is the complex conjugate of the \(k\)th component of \(e_j\).
이는 곧 \(\{e_1, \cdots, e_n\}\) 가 \(\mathbb{C^n}\) 집합의 basis인 것을 의미하고, 따라서, \(\mathbb{C^n}\) 에 속하는 임의의 벡터 \(x\)는 이 basis의 선형 조합으로 표현될 수 있습니다.
\[x = \sum_{k = -[\frac{n-1}{2}]}^{[\frac{n}{2}]} a_k e_k \ \ \ \ \mbox{(eq.1)}\]이 때, coefficients \(a_k\)는 다음과 같이 구할수 있습니다.
\[a_k = e_k * x = \frac{1}{\sqrt{n}} \sum_{t=1}^n x_t e^{-itw_k}\]여기서 {\(a_k\)} 시퀀스를 \(\{x_1, \cdots, x_n\}\)의 discrete Fourier transform 라고 부릅니다.
Definition
The periodogram of \(\{x_1, \cdots, x_n\}\) is the function
\[I_n(\lambda) = \frac{1}{n} \left\vert \sum_{t=1} ^{n} x_t e^{-it \lambda} \right\vert ^2\]다음의 proposition은 \(I_n(\lambda)\)가 \(2\pi f(\lambda)\)의 샘플 추정값으로 간주될수 있음을 보입니다. 먼저 sepectral density \(f(\lambda)\)의 정의가 다음과 같다는 것을 상기하도록 합니다.
\[2\pi f(\lambda) = \sum_{h=-\infty}^\infty \gamma(h)e^{-ih\lambda}, \ \ \ \ \ \lambda \in (-\pi, \pi] \ \ \ \ \ \ \ \mbox{(eq.2)}\]proposition
If \(x_1, \cdots, x_n\) are any real numbers and \(w_k\) is any of the nonzero Fourier frequencies \(2\pi k/n\) in \((-\pi, \pi]\), then
\[I_n(w_k) = \sum_{\left\vert h \right\vert \lt n} \hat{\gamma}(h)e^{-ihw_k}, \ \ \ \ \ \ \ \mbox{(eq.3)}\]where \(\hat{\gamma}(h)\) is the sample ACVF of \(x_1, \cdots, x_n\).
(eq.2)와 (eq.3)을 비교하면 두 식이 비슷한 것을 볼수 있고, 자연스럽게 \(I_n(w_k)\)이 \(f(\lambda)\)의 estimator로 사용할 수 있다는 것을 알 수 있습니다.
실제 데이터를 이용한 분석
이제 실제 시계열 데이터에서 spectral analysis를 수행해보겠습니다.
- 데이터 : 북창원의 기상 데이터(온도)
- 기간 : 2018-11-01 ~ 2018-12-1 (1개월, 1시간 단위)
먼저 Fourier transform통해서 데이터의 주기를 파악해보도록 하겠습니다. Discrete Fourier transform는 numpy 패키지를 통해 쉽게 이용할 수 있습니다.
df = df.rename(columns={'지점':'stn', '일시':'dataTime', '기온(°C)':'temp',
'풍속(m/s)':'ws',
'풍향(16방위)':'wd',
'습도(%)':'hm'})
df['dataTime'] = pd.to_datetime(df['dataTime'], format='%Y-%m-%d %H:%M')
df = df.set_index('dataTime')
df = df.sort_index()
signal = df.temp ## 온도 데이터
fourier = np.abs(np.fft.fft(signal)) ### fft 수행
n = signal.size
freq = np.fft.fftfreq(n) ### 주파수 시퀀스
plt.subplot(2,1,1)
plt.plot(dff.temp)
plt.grid()
plt.subplot(2,1,2)
plt.plot(freq[:int(n/2)], fourier[:int(n/2)])
plt.xlabel('frequency(Hz)')
plt.ylabel('amplitude')
plt.grid()
plt.show()
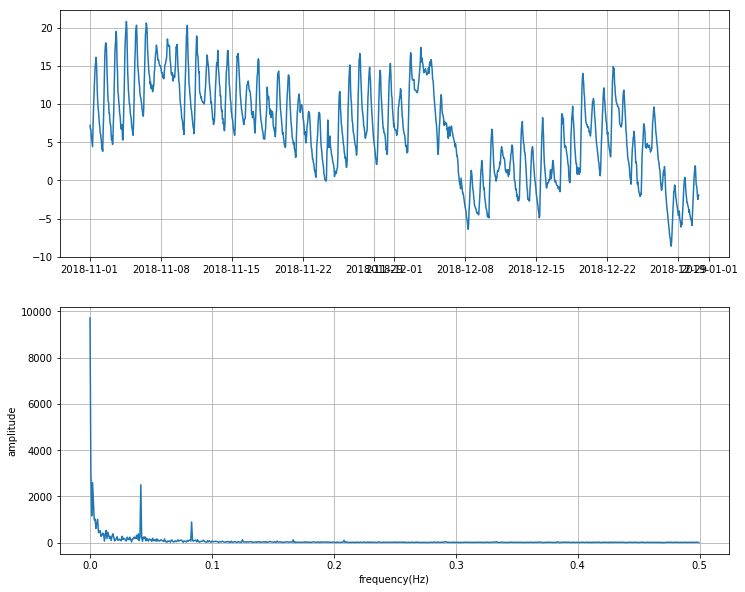
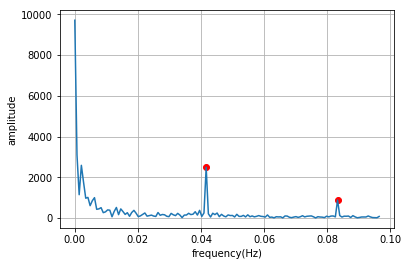
주파수 도메인으로 변환된 그래프를 살펴보면 2개의 peak가 있는 것을 볼 수 있습니다. 해당 주파수 대역을 좀더 확대해서 보면 다음과 같이 약 0.041 과 0.083 에서 peak가 발생한 것으로 보입니다. 따라서 주어진 온도 데이터는 주파수가 0.041인 시그널1과 주파수가 0.083인 시그널2의 합쳐진 것으로 생각할 수 있습니다.
주기 = 1/주파수 이기때문에 주어진 온도 데이터의 주기는 1/0.041 = 24로 구해집니다. 해당 데이터의 시간 단위가 1시간이고 주기가 24라는 것을 통해 온도 데이터가 24시간의 주기를 가지고 있다는 사실을 확인할 수 있습니다. 하루동안의 온도 패턴이 반복적인 것을 생각하면 매우 직관적인 결과입니다.
이제 주파수 값들에서 노이즈에 해당하는 값들을 0으로 바꾼 후 다시 타임 도메인으로 변경해보도록 하겠습니다.
## fourier[60]과 fourier[120]의 값을 제외하고 모두 0으로 변경
fourier[:60] = 0
fourier[61:120] = 0
fourier[121:] = 0
## inverse fourier transform
denoise = np.fft.ifft(fourier)
plt.figure(figsize=(12, 10))
plt.subplot(2,1,1)
plt.plot(df.index, denoise)
plt.grid()
plt.subplot(2,1,2)
plt.plot(freq[:int(n/2)], fourier[:int(n/2)])
plt.xlabel('frequency(Hz)')
plt.ylabel('amplitude')
plt.grid()
plt.show()
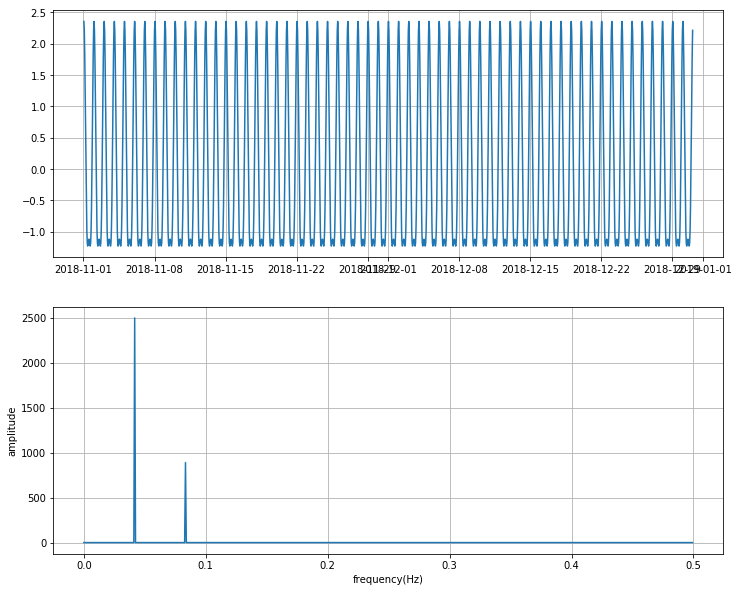
디노이즈 작업은 주파수 도메인에서 강한 값으로 보인 부분(fourier[60]과 fourier[120])을 제외한 나머지 값들은 모두 0으로 변경하는 방식을 사용하였습니다. 그 후 다시 타임 도에인으로 바꿔 시그널의 패턴을 확인하였습니다. 변환된 시계열 데이터는 24시간을 주기로 매우 반복적인 패턴을 보이는 시그널로 변경된 것을 볼 수 있습니다.
위와 같은 주파수 도메인에서의 분석은 음향이나 설비의 진동 등의 신호처리에 많이 사용되고 있으니 알아두시면 매우 유용할 것같습니다.
그동안 시계열 분석 포스팅을 읽어주셔서 감사합니다. 시계열 분석 포스팅은 이 포스팅을 마지막으로 마무리짓고자 합니다. 이후에는 딥러닝 논문 리뷰, 모델 구현 등의 포스팅으로 찾아뵙도록 하겠습니다.
앞으로도 같이 즐겁고 재미나게 공부합시다!
[1] Introduction to Time Series and Forecasting, Peter J. Brockwell, Richard A. Davis,
Comments