
How does batch normalization help optimization?
Shibani Santurkar, Dimitris Tsipras, Andrew Ilyas et al. (2018, MIT)
Abstract
- BatchNorm은 딥러닝의 안정적이고 학습속도를 빠르게 하는데 도움을 주는 기법으로 널리 활용되고 있습니다.
- 하지만 그 활용성에 비해서 왜 BatchNorm이 효과적인지에 대한 실질적인 고찰은 거의 없었으며, 대부분은 internal covariance shift를 줄이는 효과를 줄이기 때문이라고 믿고 있습니다.
- 이 논문에서는 internal covariance shift라는 것이 실제로는 BatchNorm과 거의 상관없다는 것을 실험적으로 확인하였습니다. BatchNorm기법이 최적화 함수를 훨씬 smoother하게 만들어주기 때문이라는 것을 이론적, 실험적으로 확인하였으며, 이 영향으로 인해 그래디언트가 더 안정적으로 움직여 빠른 학습이 가능하다는 것을 주장합니다.
Introduction
- 지난 몇년간 딥러닝이 컴퓨터비전, 스피치 인식 등과 같은 풀기어려운 문제를 해결하는데 성공하였으며, 이러한 성공에는 BatchNorm이 큰 기여를 하고 있습니다.
- BatchNorm의 실용성은 논란의 여기가 없지만, 그러한 효과가 왜 발생하느지에 대한 명확한 이유는 아직 밝혀지지 않았습니다.
- BatchNorm이 처음 제안되었을 때는 internal covariance shift(ICS)를 최소화하기 위한 방안으로 설명되었지만, 이 연구에서는 ICS와의 연관성을 말해주는 상세한 증거를 찾지 못하였습니다,
- Constribution
- BatchNorm과 ICS는 아무런 관련이 없다는 것을 설명하며
- BatchNorm이 효과적인 이유는 최적화 함수를 더 smooth하게 만들어 learning rate가 더 크더라도 안정적인 그래디언트를 보장하여 더 빠른 학습을 가능하게 하기 때문임을 확인하였습니다.
- 이러한 내용을 실험적인 확인 이외에 loss함수와 그 gradient의 Lipschitzness 를 이용해 이론적으로 설명하였습니다.
- 이 고찰을 통해서 BatchNorm과 동일한 효과를 가져오는 다른 기법들이 존재할수 있는 가능성을 제시하였습니다.
Batch normalization and internal covariance shift
- 처음에 Ioffe and Szegedy의 BatchNorm은 모델이 학습될때는 파라미터가 바뀌기때문에 각 레이어의 입력값들의 분포가 달라지는 현상(internal covariate shift)를 줄이기 위해 제안되었습니다.
-
BatchNorm이란 각 레이어의 액티베이션값을 평균과 분산을 각 각 0과 1로 정규화시킨 후, 모델의 설명력을 유지하기 위해 다시 scaled and shifted를 해주는 과정으로 이루집니다. 이 과정은 이전 레이어의 non-linearity전에 이루어집니다.
- Does BatchNorm’s performance stem form controlling internal covariate shift?
- BatchNorm 논문에서는 각 레이어의 인풋 분포의 평균과 분산을 제한하는 것이 학습성능에 직접적인 영향을 준다고 주장하였습니다. 이 것을 입증하기 위해 한가지 실험을 수행하였습니다.
- 배치놈 이후에 랜덤한 노이즈를 일부러 주입하여 네트워크를 학습시켜 보았습니다. 노이즈는 평균이 0이 아니고, 분산도 1이 아닌 분포에서 추출하여 각 레이어의 액티베이션에 더해주었습니다. 이 때, 각 스텝마다 노이즈의 분포가 달라지도록 하여 꽤 심한 covariate shift를 만들어보았습니다.
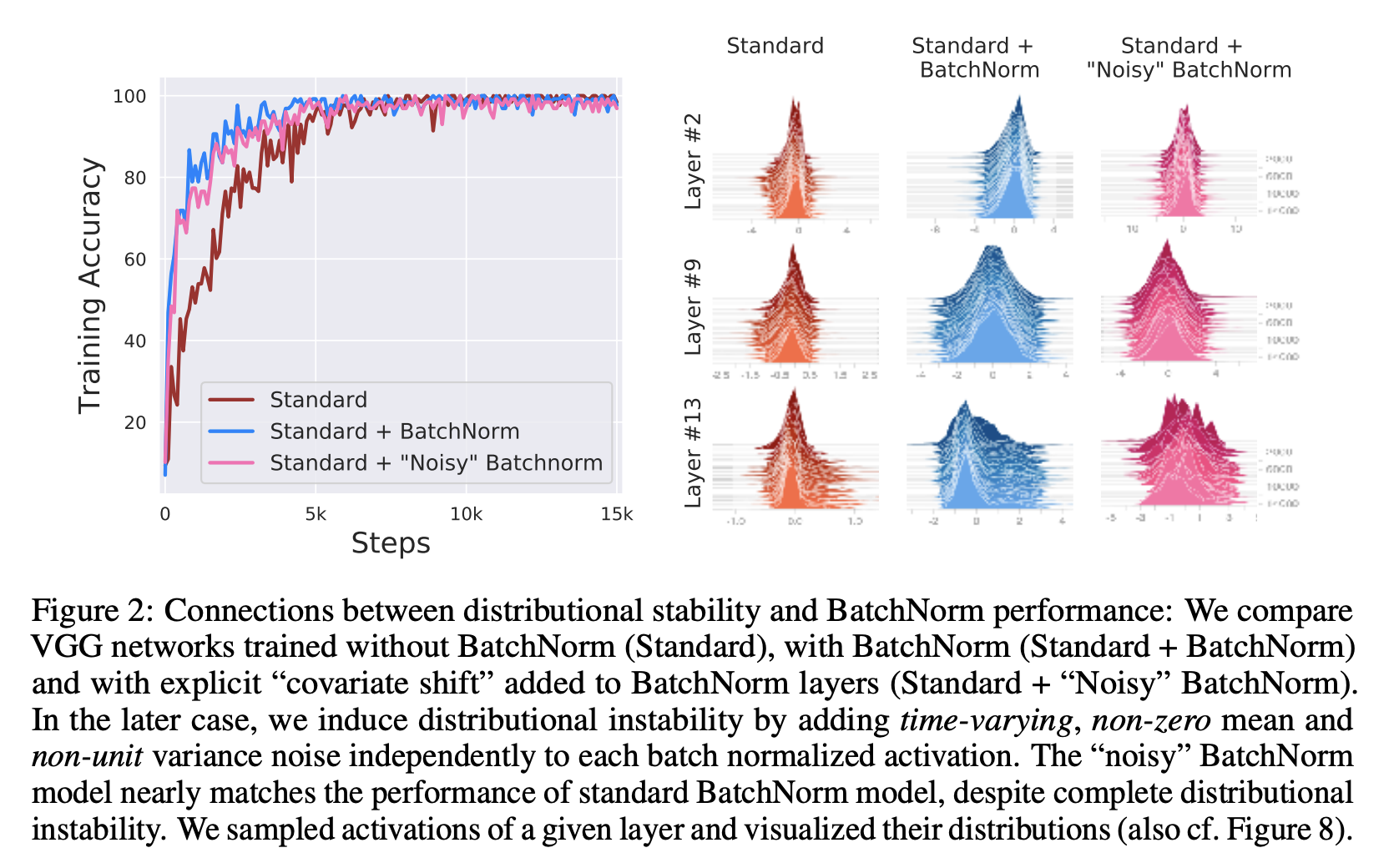
- Fig2는 standard, standard + batchnorm, standard + noisy batchnorm 세가지 네트워크의 학습 성능(좌)을 나타냅니다. 또한 시간에 따른 레이어의 액티베이션의 분포들(우)을 함께 표시하였습니다. 그림에서 볼수 있듯이, 학습데이터셋을 기준으로 batchnorm과 noisy batchnorm의 성능차이는 거의 없는 것을 확인하였습니다. 두가지 모두 standard 보다 높은 성능을 보였습니다.
-
Noisy batchnorm의 액티베이션 분포들은 불안정하지만, 학습 성능은 좋다는 실험 결과는 batchnorm의 효과가 레이어의 인풋 분포를 안정시키기 때문이다는 주장을 반박하는 결과입니다.
- Is BatchNorm reducing internal covariate shift?
- 그렇다면 더 광의적인 측면의 internal covariate shift가 batchnorm의 높은 학습성능과 직접적으로 연관된 것은 아닐까?
- 네트워크의 각각 레이어는 주어진 인풋에 대해서 리스크 최적화 문제를 푸는 것으로 생각할수 있고, 파라미터가 업데이트될 때마다 인풋을 바꾸고, 결과적으로 최적화 문제 자체를 바꾸게 됩니다. Ioffe and Szegedy는 이 현상을 internal covariate shift라고 불렀고, 각 레이어의 인풋 분포 관점에서 설명하려고 했습니다. 하지만 이 관점은 batchnorm의 성공적인 성능을 설명해주지 못한다는 것을 앞서 실험을 통해 살펴보았습니다.
- 인풋 분포가 아니라 전체 최적화 관점에서 각 레이어의 그래디어트 변화를 살펴보도록 하겠습니다.
- 이를 위해서 어떤 레이어의 전(before)/후(after) 그래디언트 변화를 다음과 같이 정의하도록 하겠습니다.
- \(G_{t, i}\)는 모든 레이어가 동시에 업데이트되는 가정에서의 그래디언트(as is typical)이고, \(G’_{t, I}\)는 i번째 레이어 이전의 레이어들이 새로운 값으로 업데이트된 후의 그래디언트입니다. 따라서 G와 G’의 차이는 i번째 레이어의 인풋이 변함에 따라 그 파라미터(\(W_i\))의 optimization landscape가 얼마나 변화하는지를 나타냅니다.
- 정의된 지표를 internal covariate shift 정도로 사용하고, batchnorm을 사용했을때와 사용하지 않았을때를 비교했습니다. 기존의 Batchnorm 논문의 주장대로라면 batchnorm을 사용하는 경우, G와 G’간의 상관관계가 높아지기 때문에 ICS는 낮아져야합니다.
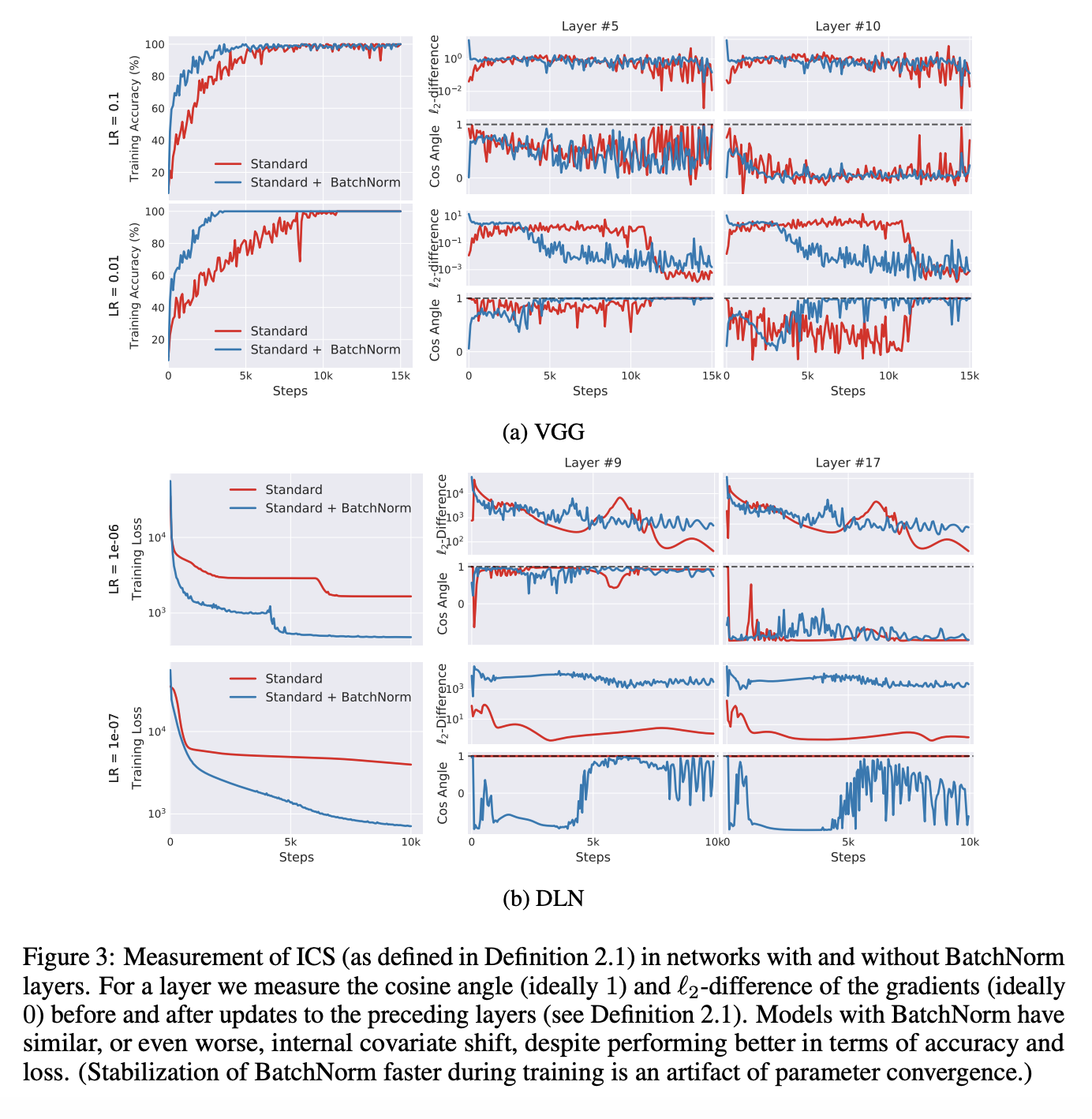
- 실험결과, BatchNorm을 사용한 네트워크의 ICS가 오히려 증가하는 것으로 나타났습니다. - fig3
- (Fig3) Standard + batchNorm가 standard 보다 더 빠르게 학습되지만 (첫번째 컬럼, 정확도와 로쓰 차트), Standard + batchNorm와 standard의 ICS 변화는 거의 비슷하거나, Standard + batchNorm의 ICS가 standard보다 높은 것으로 나타났습니다. (두번째 & 세번째 컬럼)
- 이 실험결과는 batchNorm 사용하더라도 G와 G’가 서로 uncorrelated하다는 것을 의미합니다. 즉 batchnorm을 사용하여 인풋 분포를 조절하는게 internal covariate shift를 줄이지 못한다는 것입니다.
Why does BatchNorm work?
- The smoothing effect of BatchNorm
- 그렇다면 왜 BatchNorm이 효과적일까?
- 결론부터 말하면, BatchNorm이 우리가 풀어야할 최적화문제의 landscape를 smooth하게 만들어주기 때문입니다. loss function의 Lipschitzness를 높여줘, 더 효과적인 \(\beta\)-smoothness를 갖도록 합니다. loss가 작은 비율로 변화하면 gradient의 변화량도 작아집니다.
\(\mbox{f is L-Lipschitz, If} \left\vert f(x_1) - f(x_2) \right\vert \le L \lVert x_1 - x_2 \rVert, \mbox{for all} x_1 \ and \ x_2 \\ \mbox{f is } \beta-smooth \mbox{, If its gradients are } \beta-Lipschitz \mbox{i.e, if} \left\vert \nabla f(x_1) - \nabla f(x_2) \right\vert \le \beta \lVert x_1 - x_2 \rVert, \mbox{for all } x_1 \ and \ x_2\)
-
Non-BatchNorm 네트워크의 loss function은 non-convex하고 flat regions 또는 sharp local minima를 갖고 있고 있어 gradient가 갑자기 사라지거나(flat region), 갑자기 폭발하기도(sharp local minima)하죠. 반면 BatchNorm에 의해 smooth된 loss function은 gradient가 이러한 위험에 빠질 가능성이 더 낮아 더 안정적이고 예측가능한 학습을 할수 있게 됩니다.
- Exploration of the optimization landscape
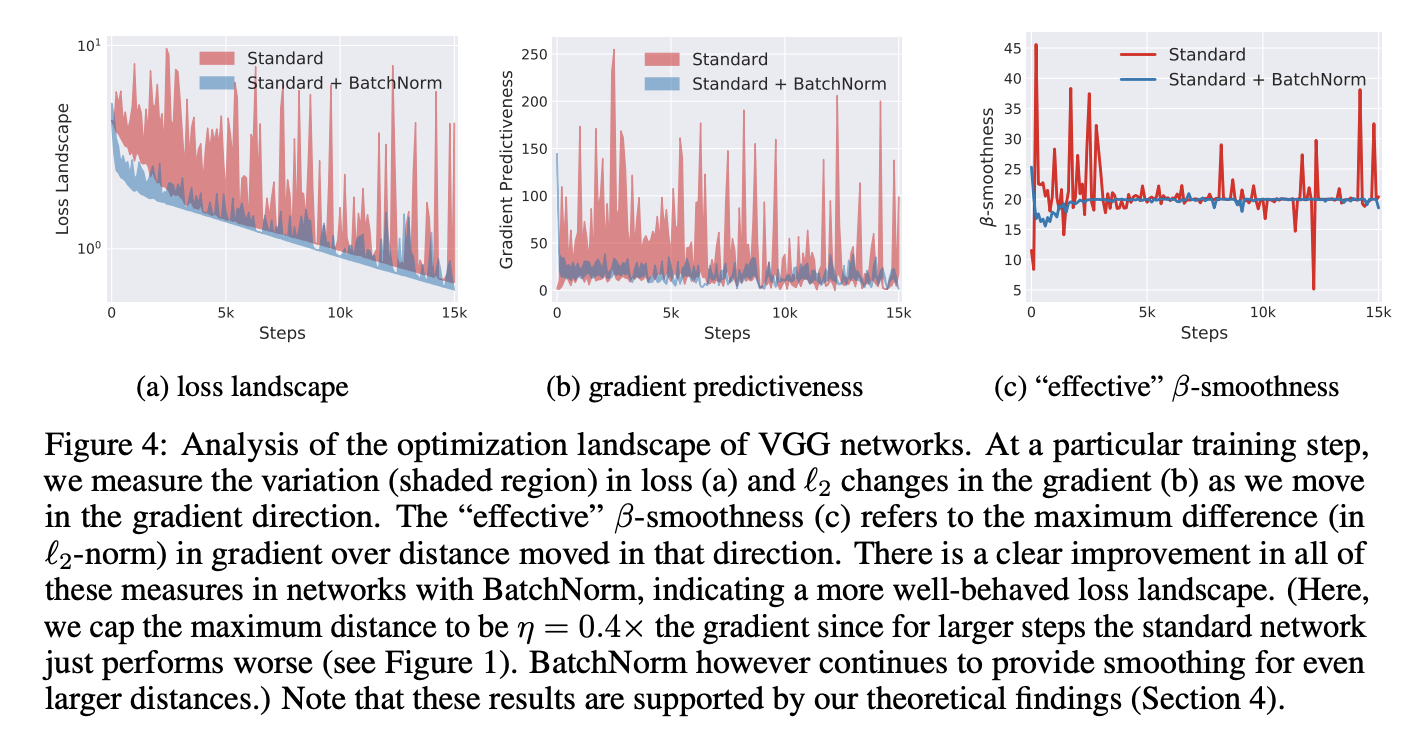
- 우선 Loss function의 Lipschitzness를 실험적으로 살펴보았습니다.
- (Fig4)(a)는 학습시간에 따라 그래디언트에 따라서 움직였을때, loss값이 얼마나 바뀌었는지를 나타냅니다. BatchNorm을 사용한지 않은 바닐라 네트워크에서는 값의 변동폭이 큰 것을 볼수 있습니다. (b)현재 그래디언트 방향과 이전 그래디언트 방향간의 l2 distance를 나타납니다. 마찬가지로 바닐라 네트워크는 그래디언트 간의 거리가 상대적으로 멀고 이는 predictiveness of the gradient가 낮다는 것을 의미합니다. (c)는 effective \(\beta\)-smoothness를 나타냅니다. effective라는 것은 그래디언트 방향으로 움직였을때 그래디언트가 얼마나 바뀌는지를 나타내며, 낮을수록 effective하다고 생각합니다. 이 결과도 앞서와 마찬가지로 BatchNorm을 사용한 경우가 더 effective하다고 나타납니다.
- Is BatchNorm the best (only?) way to smoothen the landscape?
- loss function의 landscape을 smooth하게 만드는 것이 BatchNorm방식이 유일한 것일까?
- 실험을 위해서 여기서는 first momentum(평균)은 batchnorm처럼 고정하고 normalizes를 \(l_p\)-norm으로 normalizes해보았습니다. (이렇게 정규화된 값들은 더이상 가우시안 분포가 아니고 안정적인 분포를 보장하진 않지만, Fig5에서 나타나듯 BatchNorm과 동일한 성능을 보입니다.
- 논문에서는 Appendix 결과들을 통해서 \(l_p\)-normalization 기법들이 covariate shift를 더 많이 일으키지만, Batchnorm과 마찬가지로 standard 네트워크보다 성능이 좋고 landscape의 smoothness를 개선시킨다는 결과를 말해주고 있습니다.
Theoretical Analysis
- TBU
Conclusion
- 이 논문에서는 batchnorm의 효과성이 어디에서 오는지 근본적인 원인을 살펴보았습니다.
- batchnorm은 internal covariate shift와 거의 상관이 없으며, batchnorm이 오히려 internal covariate shift를 증가시키는 것으로 나타났습니다.
- 대신에 batchnorm은 최적화문제의 landscape를 부드럽게 해주는 효과를 가져오고, 이로 인해서 그래디언트가 예측가능하고, 잘 움직이게 합니다. 이로 인해서 하이퍼파라미터에 로버스트하고, 그래디언트가 사라지거나 폭발하는 현상이 줄어들게 됩니다. 또한 이러한 효과는 batchnorm이 유일하지 않고, 다른 노말리제이션방법들도 동일한 결과를 얻을수 있음을 확인하였습니다.
Comments