
RNN for Quick drawing
Tutorial : https://www.tensorflow.org/tutorials/sequences/recurrent_quickdraw
Code : https://github.com/tensorflow/models/blob/master/tutorials/rnn/quickdraw/train_model.py
발번역 주의
Recurrent Neural Networks for Drawing Classification
Quick, Draw!는 플레이어가 물체를 그리고, 컴퓨터가 그림을 인식해서 어떤 물체를 그린것인지 맞출 수 있는지 확인하는 게임입니다.
Quick, Draw!에서는 사용자가 그린 그림에서 x,y의 점의 시퀀스를 입력으로 받아 학습된 딥러닝 모델이 사용자가 그렸던 물체의 카테고리를 맞추는 것으로 동작합니다.
이 튜토리얼에서는 RNN-based recognizer를 학습하는 방법을 설명합니다. 모델은 convolutional layers와 LSTM 레이어, 소프트맥트 아웃풋 레이어로 구성됩니다.
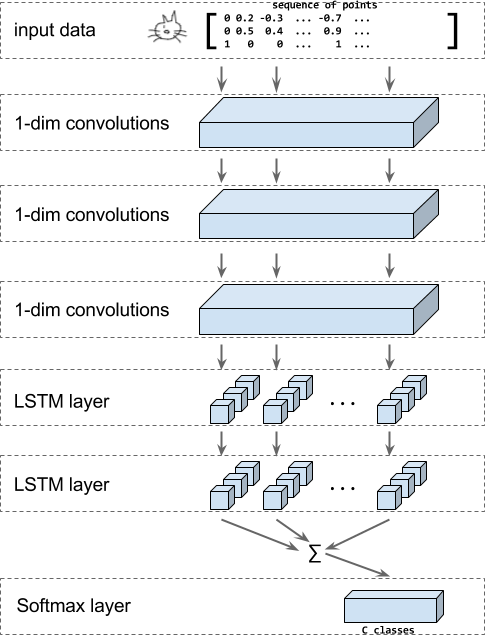
위 그림은 모델의 구조를 보여줍니다. 인풋은 x, y, n으로 인코딩된 값의 시퀀스입니다. n은 이 포인트가 시작점인지 아닌지를 알려주는 값입니다.
그리고 나서 1-dimensional convolutions이 적용됩니다. 그 후 LSTM이 적요되고 모든 LSTM 결과값을 합(sum)한 것이 소프트멕트 레이어의 인풋값으로 들어갑니다. 소프트맥트는 최종 분류 결과값을 산출합니다.
데이터는 공개된 데이터셋을 이용합니다. 345 카테고리에 대해서 총 50M 장의 그림이 있습니다.
Run the tutorial code 이 튜토리얼을 실행하기 위해서
- 텐서플로우를 설치하세요
- 튜토리얼 코드를 다운받으세요
- [여기]에서 TFRecord format의 데이터를 다운받으세요. 더 자세한 정보는 Quick, Draw! 데이터를 다운받는 법과 데이터를 TFRecord로 변화하는 법을 살펴보세요.
- 아래 명령어로 모델을 학습시켜보세요. 데이터가 있는 경로를 올바르게 조정하세요.
python train_model.py \
--training_data=rnn_tutorial_data/training.tfrecord-?????-of-????? \
--eval_data=rnn_tutorial_data/eval.tfrecord-?????-of-????? \
--classes_file=rnn_tutorial_data/training.tfrecord.classes
Tutorial details
Download the data
TFExample을 포함한 TFRecord 파일의 데이터는 아래에서 받을 수 있습니다. http://download.tensorflow.org/data/quickdraw_tutorial_dataset_v1.tar.gz
또는 구글 클라우드에서 ndjson 포멧의 데이터를 다운로드한 다음 TFRecord파일로 변환할 수 있습니다. 아래의 섹션을 따라하세요.
Optional : Download the full Quick Draw Data
전체 Quick, Draw! dataset은 구글 클라우드 저장소에서 ndjson file형태로 카테고리별로 나뉘어져 있습니다. 클라우드 콘솔에서 파일 목록을 조회할 수 있습니다.
전체 데이터를 다운로드하기 위해서 gsutil을 사용하는 것을 추천합니다. 전체 ndjson file은 ~22GB 크기인 것을 참고하세요.
gustil이 잘 설치되었고 데이터 버켓에 접근가능한지 확인하기 위해 아래의 명령어를 수행하세요.
gsutil ls -r "gs://quickdraw_dataset/full/simplified/*"
아래와 같은 결과가 나타나는지 확인하세요.
gs://quickdraw_dataset/full/simplified/The Eiffel Tower.ndjson
gs://quickdraw_dataset/full/simplified/The Great Wall of China.ndjson
gs://quickdraw_dataset/full/simplified/The Mona Lisa.ndjson
gs://quickdraw_dataset/full/simplified/aircraft carrier.ndjson
...
그리고나서 폴더를 생성하고 그 폴더에 데이터를 다운로드하세요.
mkdir rnn_tutorial_data
cd rnn_tutorial_data
gsutil -m cp "gs://quickdraw_dataset/full/simplified/*" .
Optional: Converting the data
ndjson 파일을 tf.train.Example 프로토콜을 포함한 TERecord파일로 변환하ㅣ 위해 아래 명령어를 수행하세요.
python create_dataset.py --ndjson_path rnn_tutorial_data \
--output_path rnn_tutorial_data
이 명령어는 클래스별로 10000개의 아이템을 학습 데이터로, 1000개의 아이템은 평가 데이터로 하는 TFRecord를 10개의 샤드로 저장하게 해줍니다.
이 변환 작업은 더 자세히 아래와 같습니다.
OuickDraw의 원본데이터인 ndjson 파일의 각 라인은 아래와 같은 JSON 형태로 이루어져 있습니다.
{"word":"cat",
"countrycode":"VE",
"timestamp":"2017-03-02 23:25:10.07453 UTC",
"recognized":true,
"key_id":"5201136883597312",
"drawing":[
[
[130,113,99,109,76,64,55,48,48,51,59,86,133,154,170,203,214,217,215,208,186,176,162,157,132],
[72,40,27,79,82,88,100,120,134,152,165,184,189,186,179,152,131,114,100,89,76,0,31,65,70]
],[
[76,28,7],
[136,128,128]
],[
[76,23,0],
[160,164,175]
],[
[87,52,37],
[175,191,204]
],[
[174,220,246,251],
[134,132,136,139]
],[
[175,255],
[147,168]
],[
[171,208,215],
[164,198,210]
],[
[130,110,108,111,130,139,139,119],
[129,134,137,144,148,144,136,130]
],[
[107,106],
[96,113]
]
]
}
분류기를 학습하기 위해서 필요한 것은 word와 drawing 필드입니다. ndjson 파일을 parsing하는 동시에 drawing필드를 [number of points, 3]의 텐서로 변환하기 위해서 아래와 같은 함수를 사용합니다. 이 함수는 클래스 이름을 스트링으로 반환합니다.
def parse_line(ndjson_line):
"""Parse an ndjson line and return ink (as np array) and classname."""
sample = json.loads(ndjson_line)
class_name = sample["word"]
inkarray = sample["drawing"]
stroke_lengths = [len(stroke[0]) for stroke in inkarray]
total_points = sum(stroke_lengths)
np_ink = np.zeros((total_points, 3), dtype=np.float32)
current_t = 0
for stroke in inkarray:
for i in [0, 1]:
np_ink[current_t:(current_t + len(stroke[0])), i] = stroke[i]
current_t += len(stroke[0])
np_ink[current_t - 1, 2] = 1 # stroke_end
# Preprocessing.
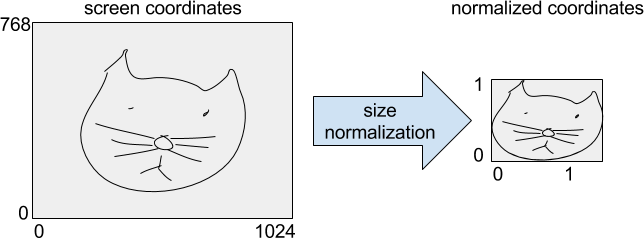
# 1. Size normalization.
lower = np.min(np_ink[:, 0:2], axis=0)
upper = np.max(np_ink[:, 0:2], axis=0)
scale = upper - lower
scale[scale == 0] = 1
np_ink[:, 0:2] = (np_ink[:, 0:2] - lower) / scale
# 2. Compute deltas.
np_ink = np_ink[1:, 0:2] - np_ink[0:-1, 0:2]
return np_ink, class_name
모델을 학습할 때 데이터가 잘 섞이도록 하기 위해 카테고리별로 분할된 파일들을 랜덤한 순서로 읽어오고, 파싱한 결과값을 랜덤한 샤드에 저장합니다.
학습데이터에는 각 클래스별로 10000개 아이템을 읽어오고, 평가데이터에는 각 클래스별로 1000개 아이템을 읽습니다.
이 데이터는 [num_training_samples, max_length, 3] 형태의 텐서로 변형됩니다. 이 후 화면 상의 원래 그림을 모두 담을수 있는 최소 박스 크기를 결정하여 전체 그림이 유닛 길이를 갖도록 정규화합니다.
마지막으로 연속된 점간의 차이값을 계산하고, ink를 키값으로 하여 tensorflow.example의 VarLenFeature로 저장합니다. 또한 class_index를 단일 항목으로 FixedLengthFeature에 저장하고, ink의 shape을 길이가 2 인 FixedLengthFeature로 저장합니다.
Defining the model
모델을 정의하기위해 새로운 Estimator를 만듭니다. Estimator를 대해서 더 자세히 알고 싶다면 이 튜토리얼을 읽어보세요.
모델을 만들기 위해
- 입력값을 원래 shape으로 벼경합니다. - 각각의 미니 배치들은 최대 길이로 pedding됩니다. ink data뿐만아니라 각 데이터들의 lenght와 target class가 필요합니다. 이는 _get_input_tensor 함수에서 수행됩니다.
- 입력값이 _add_conv_layers 함수에서 일련의 convolution layer를 통과하게 됩니다.
- 컨볼루션의 아웃품은 바이디렉셔널 LSTM 레이어로 연결됩니다. _add_rnn_layers로 연결되고 마지막에는 각 타임스탬프의 결과값은 합산되어 고정된 길의 인풋값으로 변경됩니다.
- 이 임배딩 벡터를 소프트맥스 레이어를 이용해 _add_fc_layers에서 최종 분류합니다.
코드는 아래와 같습니다.
inks, lengths, targets = _get_input_tensors(features, targets)
convolved = _add_conv_layers(inks)
final_state = _add_rnn_layers(convolved, lengths)
logits =_add_fc_layers(final_state)
_get_input_tensors
## feature dict에서 shape을 얻습니다.
shapes = features["shape"]
## 입력 시퀀스의 길이값을 가진 1D 텐서(사이즈:[batch_size])를 만듭니다.
lengths = tf.squeeze(
tf.slice(shapes, begin=[0, 0], size=[params["batch_size"], 1]))
## Sparse Tensor형태인 ink 필드를 dense tensor로 변경하고, [batch_size, ?, 3]형태로 바꿔줍니다.
inks = tf.reshape(
tf.sparse_tensor_to_dense(features["ink"]),
[params["batch_size"], -1, 3])
## target 필드가 넘겨지면, [batch_size] 형태의 1D텐서로 저장합니다.
if targets is not None:
targets = tf.squeeze(targets)
_add_conv_layers
param dict의 num_conv와 conv_len 파라미터값을 통해 각 몇개의 컨볼루션 레이어를 쌓을지, 필터의 길이는 어느정도로 할지를 구성합니다.
인풋은 3차원의 포인트들의 시퀀스입니다. 우리는 1D convolutions을 사용하고, 3개의 피처는 채널로 대응되도록 할 것입니다. 이 말은 [batch_size, length, 3] 형태의 텐서를 인풋으로 받고, 아웃풋은 [batch_size, length, number_of_filters] 형태의 텐서라는 말입니다.
## inks 데이터를 입력을 받습니다.
convolved = inks
## params.num_conv에 지정된 수만큼 컨볼루션 레이어를 쌓습니다.
for i in range(len(params.num_conv)):
convolved_input = convolved
## 만약 parmas.batch_num == True이면 배치놈을 사용하여 입력값을 정규화합니다.
if params.batch_norm:
convolved_input = tf.layers.batch_normalization(
convolved_input,
training=(mode == tf.estimator.ModeKeys.TRAIN))
# Add dropout layer if enabled and not first convolution layer.
## 첫번째 컨볼루션은 제외하고, params.dropout이 지정되어 있으면 드랍아웃 regularization을 사용합니다.
if i > 0 and params.dropout:
convolved_input = tf.layers.dropout(
convolved_input,
rate=params.dropout,
training=(mode == tf.estimator.ModeKeys.TRAIN))
## 배치놈, regularization 이후 컨볼루션 레이어를 쌓습니다. 필터 갯수와 사이즈는 param.conv와 param.conv_len을 사용합니다.
convolved = tf.layers.conv1d(
convolved_input,
filters=params.num_conv[i],
kernel_size=params.conv_len[i],
activation=None,
strides=1,
padding="same",
name="conv1d_%d" % i)
return convolved, lengths
_add_rnn_layers
컨볼루션 결과를 bidirectional LSTM의 입력값으로 사용합니다. contrib 라이브러리에서 헬퍼 함수를 이용합니다.
outputs, _, _ = contrib_rnn.stack_bidirectional_dynamic_rnn(
cells_fw=[cell(params.num_nodes) for _ in range(params.num_layers)],
cells_bw=[cell(params.num_nodes) for _ in range(params.num_layers)],
inputs=convolved,
sequence_length=lengths,
dtype=tf.float32,
scope="rnn_classification")
자세한 정보와 CUDA를 이용한 가속 실행은 코드를 참고하세요.
압축된, 고정된 길이의 임베딩을 위해서 LSTM 결과값들을 모두 더합니다. 먼저 배치 영역에서 시퀀스 데이터가 없는 곳은 0으로 채웁니다.
mask = tf.tile(
tf.expand_dims(tf.sequence_mask(lengths, tf.shape(outputs)[1]), 2),
[1, 1, tf.shape(outputs)[2]])
zero_outside = tf.where(mask, outputs, tf.zeros_like(outputs))
outputs = tf.reduce_sum(zero_outside, axis=1)
_add_fc_layers
인풋의 임베딩이 fully connected layer로 연결됩니다. 소프트맥스 레이어를 사용합니다.
tf.layers.dense(final_state, params.num_classes)
Loss, predictions, and optimizer
마지막으로 loss, 옵티마이저, predictions을 만듭니다.
cross_entropy = tf.reduce_mean(
tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=targets, logits=logits))
# Add the optimizer.
train_op = tf.contrib.layers.optimize_loss(
loss=cross_entropy,
global_step=tf.train.get_global_step(),
learning_rate=params.learning_rate,
optimizer="Adam",
# some gradient clipping stabilizes training in the beginning.
clip_gradients=params.gradient_clipping_norm,
summaries=["learning_rate", "loss", "gradients", "gradient_norm"])
predictions = tf.argmax(logits, axis=1)
return model_fn_lib.ModelFnOps(
mode=mode,
predictions={"logits": logits,
"predictions": predictions},
loss=cross_entropy,
train_op=train_op,
eval_metric_ops={"accuracy": tf.metrics.accuracy(targets, predictions)})
Training and evaluating the model
모델을 학습하고 평가하기 위해 Estimator APIs의 함수들을 사용합니다. 학습과 평가를 쉽게 실행하기 위해서 EXperiment APIs를 사용합니다.
estimator = tf.estimator.Estimator(
model_fn=model_fn,
model_dir=output_dir,
config=config,
params=model_params)
# Train the model.
tf.contrib.learn.Experiment(
estimator=estimator,
train_input_fn=get_input_fn(
mode=tf.contrib.learn.ModeKeys.TRAIN,
tfrecord_pattern=FLAGS.training_data,
batch_size=FLAGS.batch_size),
train_steps=FLAGS.steps,
eval_input_fn=get_input_fn(
mode=tf.contrib.learn.ModeKeys.EVAL,
tfrecord_pattern=FLAGS.eval_data,
batch_size=FLAGS.batch_size),
min_eval_frequency=1000)
이 튜토리얼은 상대적으로 적은 데이터셋을 사용해서 RNN APIs와 estimators에 익숙해지기 위한 간단한 예제 입니다. 이러한 모델은 더 큰 데이터셋을 사용할때 더 유용할지 모릅니다.
1M스텝에 가깝게 모델을 학습하면 top-1 condiate에 대해서 70%의 정확도를 얻을 수 있을것입니다. 이 정확도는 사용자가 만족할 때까지 그림을 수정할수 있으므로 충분합니다. 또한 top-1 candiates만 사용하는게 아니라, 고정된 threshold를 사용하여 이 값을 넘은 타겟 카테고리들은 모두 옳다고 할수 있습니다.
Comments