
from GAN to WGAN
이 글은 lilianweng의 from GAN to WGAN 포스팅을 동의하에 번역한 글입니다.
From GAN to WGAN
이 포스트는 generative adversarial netowrk (GAN) model에 사용되는 수식과 GAN이 왜 학습하기 어려운지를 설명합니다. Wasserstein GAN은 두 분포간의 거리를 측정하는데 더 향상된(smoooth한) 메트릭를 사용하여 GAN의 학습과정을 개선하였습니다.
Generative adversarial network(GAN)은 이미지나 자연어, 음성과 같은 현실의 다양한 컨텐츠를 생성하는 분야에서 큰 성과를 보여주고 있습니다. generator와 discriminator(a critic) 두 모델이 서로 경쟁하듯 학습되어 동시에 서로의 성능이 올라가는 게임 이론에 근본을 두고 있습니다. 하지만 GAN의 학습이 불안정하거나 실패로 이어지는 경우가 많아, 최적값에 수렴된 모델로 학습하는 것은 어려운 문제입니다.
여기서는 GAN에 사용되는 수식들을 설명하고자 하며, 왜 학습이 어려운지, 그리고 학습의 어려움을 해결하기 위해 향상된 GAN을 소개하고자 합니다.
- Kullback–Leibler and Jensen–Shannon Divergence
- Generative Adversarial Network (GAN)
- problems in GANS
- Improved GAN Training
- Wasserstein GAN (WGAN)
- Example : Create New Pokemons!
- Reference
Kullback–Leibler and Jensen–Shannon Divergence
GAN을 자세히 설명하기 전에 두 분포사이의 유사도를 정량화하는 두 가지 메트릭을 살펴보도록 하겠습니다.
1) KL(Kullback - Leibler) divergence 는 p 분포가 다른 분포 q와 얼마나 떨어져 있는지를 측정합니다.
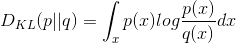
DKL는 p(x)==q(x)일때 최소값 zero를 갖습니다. KL divergence는 비대칭적인 형태라는 점을 기억해두시길 바랍니다. 또한 p(x)가 0에 가깝고 q(x)가 non-zero일 경우, q의 효과는 무시됩니다. 이로 인해 두 분포를 동등하게 사용하여 유사도를 측정하고자 할때 잘못된 결과를 얻을수 있습니다.
2) Jensen-Shannon Divergence 는 두 분포의 유사도를 특정하는 다른 메트릭으로 [0, 1] 사이값을 갖습니다. JS divergence는 대칭적입니다(야호!) 그리고 더 스무스(smooth)합니다. KL divergence와 JS divergence를 더 자세히 비교하는 내용은 이 Quora post를 참고하세요.
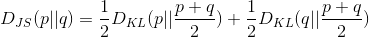
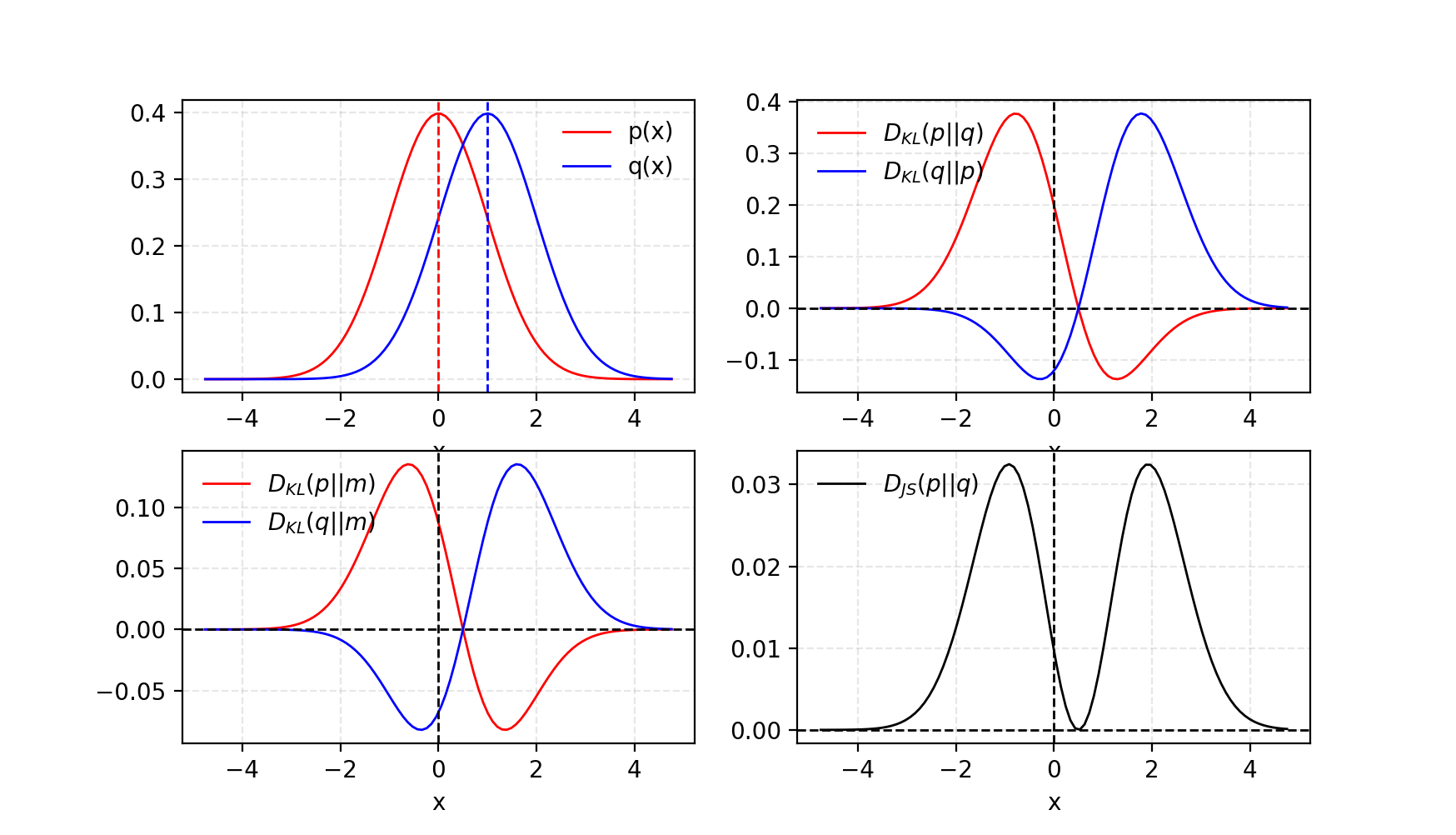
Fig.1. 두 가우시안 분포, p는 평균 0과 분산 1이고 q는 평균 1과 분산 1. 두 분포의 평균은 m=(p+q)/2. KL divergence는 비대칭적이지만 JS divergence는 대칭적입니다.
Generative Adversarial Network (GAN)
GAN은 두 모델로 이루어져있습니다.
- discriminator D는 주어진 샘플이 실제 데이터셋에서 나왔을 확률을 추정합니다. 감별사 역할로 실제 샘플과 가짜 샘플을 구분하도록 최적화됩니다.
- generator G는 노이즈 변수인 z (z는 가능한 출력의 다양성을 나타냅니다)를 입력으로 받아 위조된 샘플을 만듭니다. 실제 데이터의 분포를 모사하도록 학습되어 생성된 샘플은 실제 데이터의 샘플과 유사하며, discriminator를 속이는 역할을 합니다.
Fig.2. GAN의 구조 (출처 : 여기)
학습과정에서 두 모델은 경쟁구조에 놓여 있습니다 : G는 D를 속이려고 하고, 동시에 D는 속지 않으려고 합니다. zero-sum 게임에서 두 모델은 각자의 기능을 최대로 향상시킴으로써 서로의 목적을 달성하게 됩니다.
| Symbol | Meaning | Notes |
|---|---|---|
| pz | 노이즈 입력값 z의 분포 | 보통, uniform |
| pg | data x에 대한 generator의 분포 | |
| pr | 실제 샘플 x에 대한 데이터 분포 |
우리는 실제 데이터에서 뽑힌 샘플 x에 대해서 D가 높은 확률로 진짜라고 감별하기를 원합니다. 반면에 생성된 샘플 G(z)에 대해서는, z ~ pz(z), D의 감별결과값 D(G(z))이 zero에 가깝기를 원합니다. 즉, Ex ~ pr(x)[ logD(x) ]와 Ez ~ pz(z)[ log ( 1 - D(G(z))) ]가 최대화되길 원합니다.
하지만 G는 위조된 샘플을 D가 높은 확률로 진짜 데이터라고 판단하도록 최적화됩니다. 따라서 Ez ~ pz(z) [ log ( 1 - D(G(z))) ]가 최소화되길 원합니다.
이 두 가지를 합쳐서, D와 G는 minmax game을 하게 되고 아래와 같은 손실함수를 최적화하도록 설계되어 있습니다.
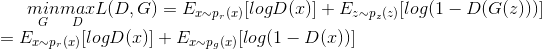
(Ex ~ pr(x)[logD(x)]는 그래디언트 디센트 업데이트에서 G에 아무런 영향을 주지 않습니다.)
What is the optimal value for D?
자, 이제 잘 정의된 손실함수를 이용해 D에 대해서 가장 최적화된 값을 찾아보도록 하겠습니다.
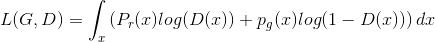
우리는 L(G, D)를 최대화는 최적의 D(x)값을 찾는 것이 목적입니다. 아래와 같은 라벨을 사용하여 인테그랄 안쪽의 식을 다시 나타내도록 하겠습니다. (x는 가능한 모든 경우에 대해서 샘플된 값이기때문에 인테그랄은 무시해도 됩니다.)
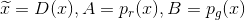
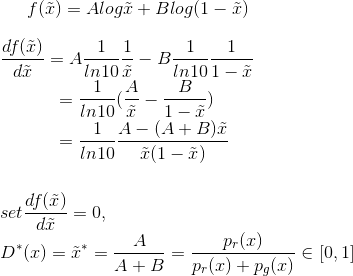
일단 generator가 최적으로 학습이 된다면, pg는 pr에 매우 가까워질것입니다. pg = pr 가 되면, D*(x)은 1/2가 됩니다.
what is the global optimal?
G와 D 모두 최적값일때, pg = pr이고, D*(x)=1/2가 되어 손실함수는 -2log2가 됩니다.
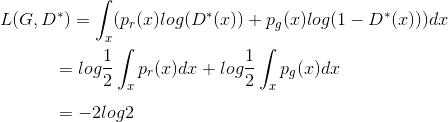
what does the loss function represent?
앞서 설명한 JS divergence를 적용하여 pr과 pg 사이의 JS divergence는 아래처럼 계산됩니다.
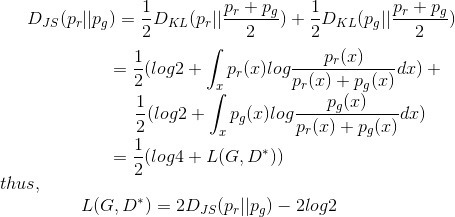
즉, 핵심은 discriminator가 최적으로 학습되었을때 GAN의 손실함수는 데이터에 의해 생성된 분포 pg와 실제 샘플데이터의 분포 pr 사이의 유사도를 JS divergence로 정량화하는 것과 같습니다. 실데 데이터 분포를 모사하는 최적의 G*는 최소값으로 L(G*, D*) = -2 log2 가 됩니다.
- GAN의 변형체 : 서로 다른 목적의 문제 상황을 풀기 위한 GAN의 다양한 변형체들이 존재합니다. 예를 들어 semi-supervised learning에서 discriminator가 fake (label : K)를 구분하는 것뿐만아니라 실제 클래스 라벨(label : 1, …, K-1)를 구분하도록 학습시키는 구조가 있습니다. 이때 generator의 목적은 K보다 작은 값으로 분류되도록 하여 discriminator를 속이는 것 입니다.
Tensorflow Implementation : carpedm20/DCGAN-tensorflow
problems in GANS
GAN이 실제 이미지 생성에서 좋은 성능을 보이고 있지만, 학습하는 것이 쉬운 일은 아닙니다. 일반적으로 학습 과정이 느리고 불안정한 것으로 알려져 있습니다.
hard to achieve Nash equilibrium
Salimans et al. (2016) 에서는 그래디언트 하강 방식 기반으로 GAN을 학습할 때 생기는 문제점들을 논의하였습니다. 두 모델이 내쉬 균형을 찾기 위해서 동시에 학습됩니다. 하지만 각 모델은 게임 내 다른 플레이어와 관련없이 손실함수를 독립적으로 업데이트합니다. 두 모델의 그래디언트를 동시에 업데이트한다고해서 수렴이 반드시 보장되는 것은 아닙니다.
비협동적인 게임에서 내쉬 균형을 찾는 것이 왜 어려운지 이해하기 위해 간단한 예를 확인해보도록 하겠습니다. 한 플레이어는 f1(x) = xy를 최소화하기 위해 x를 업데이트하고, 다른 플레이어는 f2(y) = -xy를 최소화하기 위해 y를 업데이트하는 상황을 가정해보도록 하겠습니다.
∂f1/∂x = y, ∂f1/∂x = -x이기 때문에 한 iteration에서 x와 y는 각 각 x - η⋅y와 y + η⋅x로 동시에 업데이트 됩니다(η는 러닝 레이트임). x와 y가 서로 다른 부호를 가지면, 다음의 모든 그래디언트 업데이트는 진동하게 되고 그림3과 같이 불안정성이 시간이 갈수록 심해지는 경향으로 나타납니다.
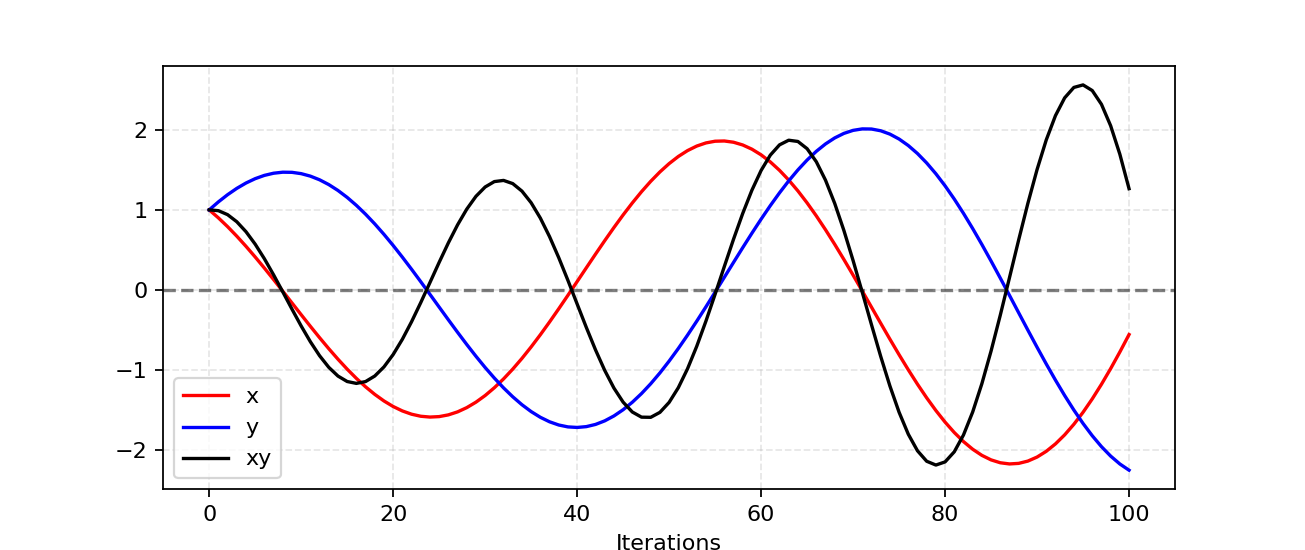
Fig.3. xy를 최소화하도록 x를 업데이트하고, -xy를 최소화하기 위해 y를 업데이트하는 상황을 시뮬레이션한 결과(러닝레이트 η =0.1) iteration이 증가할수록 진동폭이 점점 커지고 불안정해지는 현상이 나타납니다.
Low dimensional supports
| Term | Explanation |
|---|---|
| Manifold | 각 포인트 근처의 유클리드 공간과 지역적으로 유사한 토폴로지 공간. 정확하게,이 유클리드 공간이 차원 n 인 경우, 매니폴드는 n - 매니폴드라고합니다. |
| Support | 실수형 함수 f는 0으로 매핑되지 않은 요소들을 포함하는 도메인의 하위 집합입니다. |
Arjovsky and Bottou (2017) 에서는 저차원 매니폴드(Manifold) 공간에서의 pr과 pg의 서포트(Support) 문제를 다루고, 매우 이론적인 방법으로 그것들이 어떻게 GAN 학습과정의 불안정성(instability)을 야기하는지 논의하였습니다.
실제 세상의 데이터의 차원은 (pr로 나타내어지는 데이터) 인위적으로 매우 높은 차원으로 표현하지만, 저차원 매니폴드에서는 매우 밀집된 형태로 나타납니다. 사실 이것은 Manifold learning의 기본 가정에 해당합니다. 실제 세상에 존재하는 이미지를 생각하면, 일단 테마나 포함된 객체가 고정되면, 이미지는 많은 제약조건을 갖게 됩니다. 예를 들어 강아지는 두개의 귀와 꼬리 하나를 가져야하고, 초고층 건물은 기다란 직선형이어야합니다. 이러한 제약사항들로 인해 이미지들은 고차원 공간의 자유로운 형태와 멀어지게 됩니다.
pg 역시 저차원 매니포드 공간에 놓여있습니다. generator가 100차원 노이즈 인풋 z를 이용해 64x64와 같이 더 큰 차원의 이미지를 생성해야할 경우, 4096 픽셀들의 컬러 분포는 100차원의 작은 랜덤 넘버 벡터에 의해 결정되며 이 때 고차원의 공간 전체를 거의 채울 가능성은 매우 낮습니다.
결론적으로 pg와 pr이 저차원 매니포드 공간에 놓여있기때문에, 두 분포는 fig.4처럼 거의 확실하게 분리가능(disjoint)할 것입니다. 두 분포가 서로 분리할수있는 서포트를 갖을 경우, 우리는 항상 진짜와 가짜 샘플을 100% 구분할수 있는 완벽한 discriminator를 찾을수 있습니다. (증명과정이이 궁금하다면 이 논문을 참조하세요.)
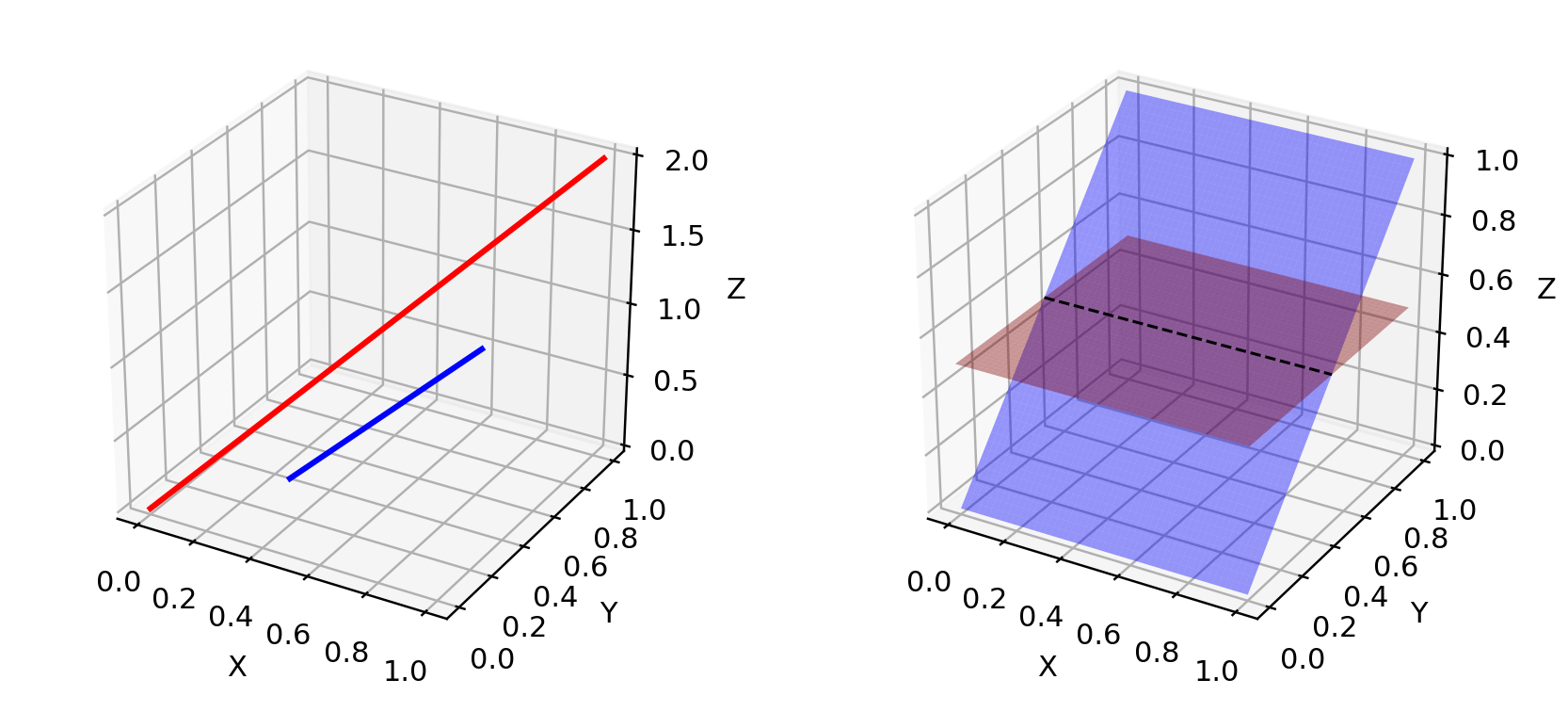
Fig.4. 고차원공간에서 저차원 매니폴드는 거의 서로 겹치지 않습니다.왼쪽의 3차원 공간에서 두 직선처럼요. 또는 오른쪽의 3차원공간에서 두 평면처럼요.
Vanishing gradient
만약 discriminator가 완벽하다면, 우리는 D(x) = 1 ∀x ∈ pr와 D(x) = 0 ∀x ∈ pg를 확신할수 있습니다. 따라서 손실함수 L은 0에 가까워지고, 학습 과정에서 loss를 업데이트할수 있는 gradient를 얻지 못하여 결국 학습이 종료됩니다. fig.5는 discriminator가 점점 좋아질수록 gradient가 더 빨리 사라지는(vanish) 현상을 나타냅니다.
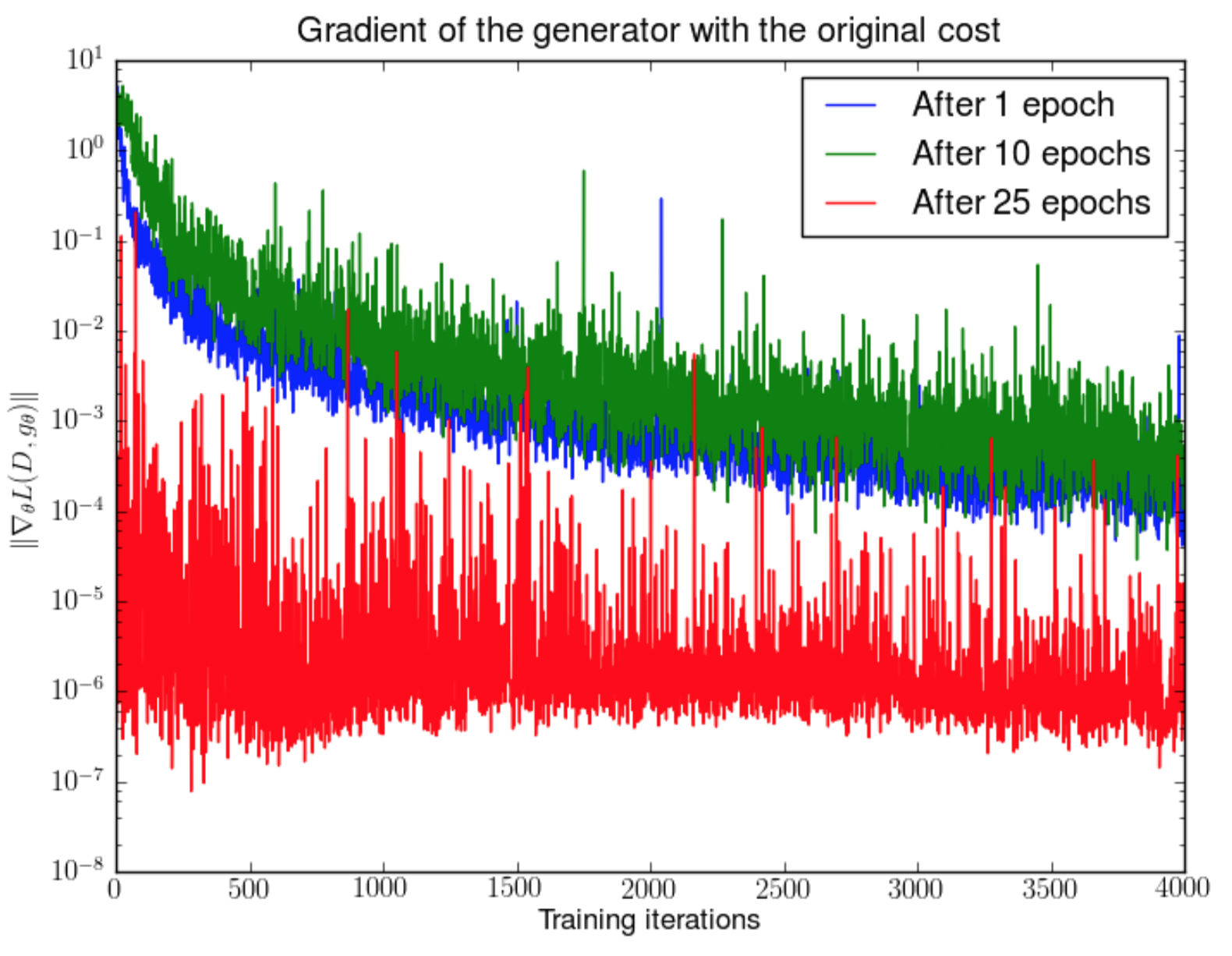
Fig.5.먼저 DCGAN 모델을 1, 10, 25 epoch만큼 학습시킵니다. 그리고, generator는 고정시킨채, discriminator를 학습시키면서 손실함수의 gradient를 측정하였습니다. 4000번의 이터레이션 후에 5 order 수준으로 gradient가 빠르게 감소하는 것을 볼수 있습니다(in best case = after 1 epoch, Image source: Arjovsky and Bottou, 2017))
결론적으로, GAN을 학습시키는 것은 아래와 같은 딜레마를 격게 됩니다:
- 만약 discriminator가 잘못된 판단하게 될 경우, generator는 정확한 피드백을 받지 못하게 되고 손실함수는 현실을 반영하지 못하게 됩니다.
- 만약 discriminator가 매우 정확하게 판단하게 될 경우, 손실함수의 gradient가 0에 가까운 값으로 빠르게 떨어지고 학습 속도가 현저히 늦어지거나 심지어 방해가 됩니다.
이 딜레마는 분명히 GAN 학습을 매우 어렵게 만듭니다. ㅠ_ㅠ
Mode collapse
학습과정에서 generator가 항상 동일한 아웃풋을 만들어낼수도 있습니다. 이 살패 현상은 ‘Mode Collapse’라고 부르며, GAN 학습과정에서 흔하게 발생합니다. 비록 generator가 discriminator를 속이는 데는 성공하였지만, 실제 데이터의 복잡한 분포를 학습하는데 실패하고 극단적으로 낮은 다양성을 갖는 작은 공간 안에 갇혀버린 경우입니다.

Fig. 6. 학습된 DCGAN(MLP network with 4 layers, 512 units and ReLu activation function)에 의해 생성된 이미지들로 mode collapse 현상을 보이고 있습니다. Image source : Arjovsky, Chintala, & Bottou, 2017.
Lack of a proper evaluation metric
GAN은 태생적으로 학습 진행과정을 알려주는 적절한 목적 함수가 없습니다. 적절한 평가 지표 없이는 어둠 속에서 학습이 진행되는 것과 같습니다. 언제 학습을 중단해야하는지, 복수개의 모델 중 어떤 것이 더 나은지 등을 판단하기 어렵습니다.
Improved GAN Training
여러 연구를 통해 안정된 GAN 학습을 위해 아래와 같은 방법들이 도입되었습니다. 앞의 다섯가지 방법은 “Improve Techniques for Training GANS”에서 제안된 방법으로 GAN이 더 빠르게 수렴할수 있도록 하는 실용적인 기법들입니다. 마지막 두가지 방법은 “Towards principled methods for training generative adversarial networks”에서 제안한 방법으로 disjoint distribution 문제를 해결하기 위해 사용되었습니다.
(1) Feature Matching
Feature matching은 generator의 결과와 실제 샘플 데이터를 비교하여 기대 수준의 통계값을 얻도록 discriminator를 최적화시키는 것입니다. 손실함수를 ||Ex~prf(x) - Ez~pzf(G(z))||22와 같은 형태로 정의하고, f(x)는 평균이나 중간값같은 feature의 통계값을 사용합니다.
(2) Minibatch Discrimination
Minibatch Discrimination 방식은 discriminator가 각 데이터를 독립적으로 처리하는게 아니라, 하나의 배치 안에서의 다른 데이터간의 관계를 고려하도록 설계하는 것입니다.
미니배치에서 각 샘플들의 간의 유사도, c(xi, xj)를 추정하고 한개의 데이터가 같은 배치 내에서 다른 데이터들과 얼마나 가까운지를 나타내는 값, o(xi) = ∑j c(xi, xj)를 계산합니다. 계산된 o(xi)를 모델 입력값에 명시적으로 추가하여 다른 데이터들 간의 관계를 고려하여 학습되도록 합니다.
(3) Historical Averagin
dicrimnator와 generator의 손실함수 모두에 ||Θ - 1/t∑i=1tΘi||2를 추가합니다. Θ는 모델 파라미터를 나타내고, Θi는 i번째 학습 과정에서의 파라미터로 Θ가 급격히 변화하는 것에 대해서 패널티를 주는 방식입니다.
(4) One-sided Label Smoothing discriminator를 학습할때 라벨링 정보로 0과 1을 사용하는게 아니라, 0.9와 0.1를 사용하는 것입니다. 이렇게 하는 것이 모델의 불안정성을 감소시키는 효과를 준다고 합니다.
(5) Virtual Batch Normalization (VBN) 데이터를 노말라이즈할때 미니배치단위로 하는 것이 아니라, 고정된 배치(reference batch)를 이용하는 방식입니다. reference batch는 학습 초기에 한번 선별되어 학습이 진행되는 동안 변하지 않습니다.
Theano Implementation : openai/improved-gan
(6) Adding Noises
low dimensional supports부분에서 설명한 것처럼 pr과 pg는 고차원공간에서 서로 겹치지 않고(disjoint), 이 때문에 그래디언트가 사라지는 문제가 발생한다. 인위적으로 분포를 펼쳐 두 확률분포가 서로 겹칠 확률을 높이기 위해, discriminator D의 인풋으로 연속적인 노이즈 값을 추가할 수 있습니다.
(7) Use Better Metric of Distribution Similarity
바닐라 GAN의 손실함수는 pr과 pg간의 JS divergence를 측정하는 것입니다. JS divergence는 두 분포가 서로 겹치지 않을때 의미있는 값을 가지지 않습니다.
이를 해결하기 위해 Wasserstein metric를 사용할 수 있습니다. Wasserstein metric는 더 연속적인 값의 범위를 가지고 있습니다. 다음 장에서 자세히 설명해보겠습니다.
Wasserstein GAN (WGAN)
What is Wasserstein distance?
Wasserstein Distance은 두 확률분포간의 거리를 측정하는 지표입니다. Earth Mover’s distance, 짧게 EM distance,라고도 부릅니다. 왜냐하면 어떤 확률 분포 모양을 띄는 흙더미를 다른 확률분포 모양을 가지도록 하는데 드는 최소 비용으로 해석할수 있기 때문입니다. 이 때 비용은 옮겨진 흙의 양과 이동한 거리를 곱하여 정량화합니다.
먼저 간단한 이산(discrete) 확률 분포를 이용해 예를 들어 설명해보겠습니다. 예를 들어서 P와 Q 라는 두 분포가 있을때, 각 각은 4개의 흙더미를 가지고 있고 흙의 총량은 10이라고 해봅시다. 각 흙더미에 있는 흙의 양은 아래와 같습니다.
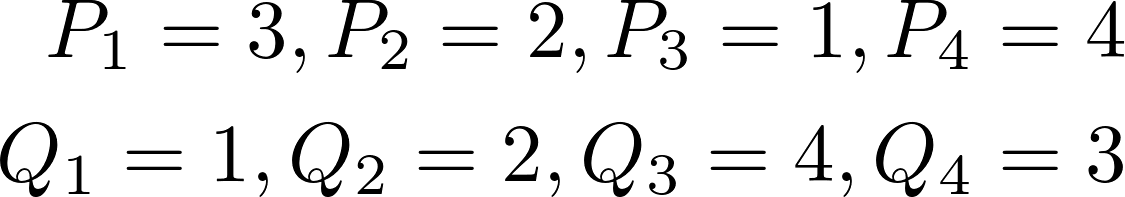
P를 Q처럼 바꾸기 위해서는
- 먼저 P1에서 2만큼을 P2로 이동시킵니다. => (P1, Q1)이 같아집니다.
- P2에서 2만큼을 P3로 이동시킵니다. => (P2, Q2)가 같아집니다.
- Q3에서 1만큼을 Q4로 이동시킵니다. => (P3, Q3)과 (P4, Q4)가 같아집니다.
Pi와 Qi가 같아지게 하는데 드는 비용을 δi라고 표시하면, δi+1 = δi + Pi - Qi로 나타낼수 있습니다. 따라서 위의 과정을 수식으로 표현하면 아래와 같습니다.
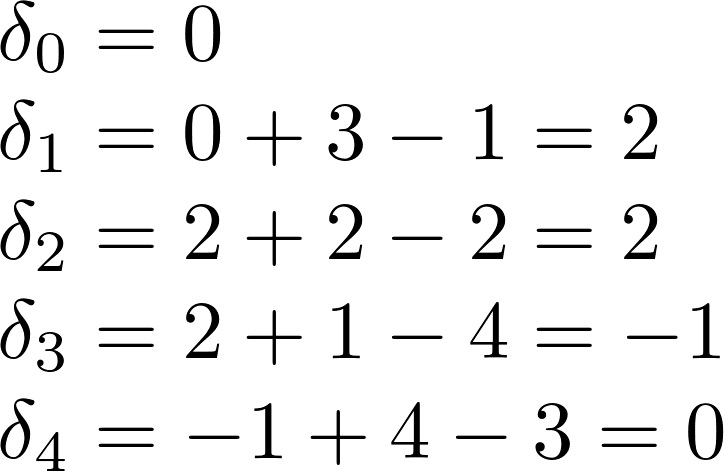
최종적으로 Earth Mover’s distance W = ∑|δi| = 5 가 됩니다.
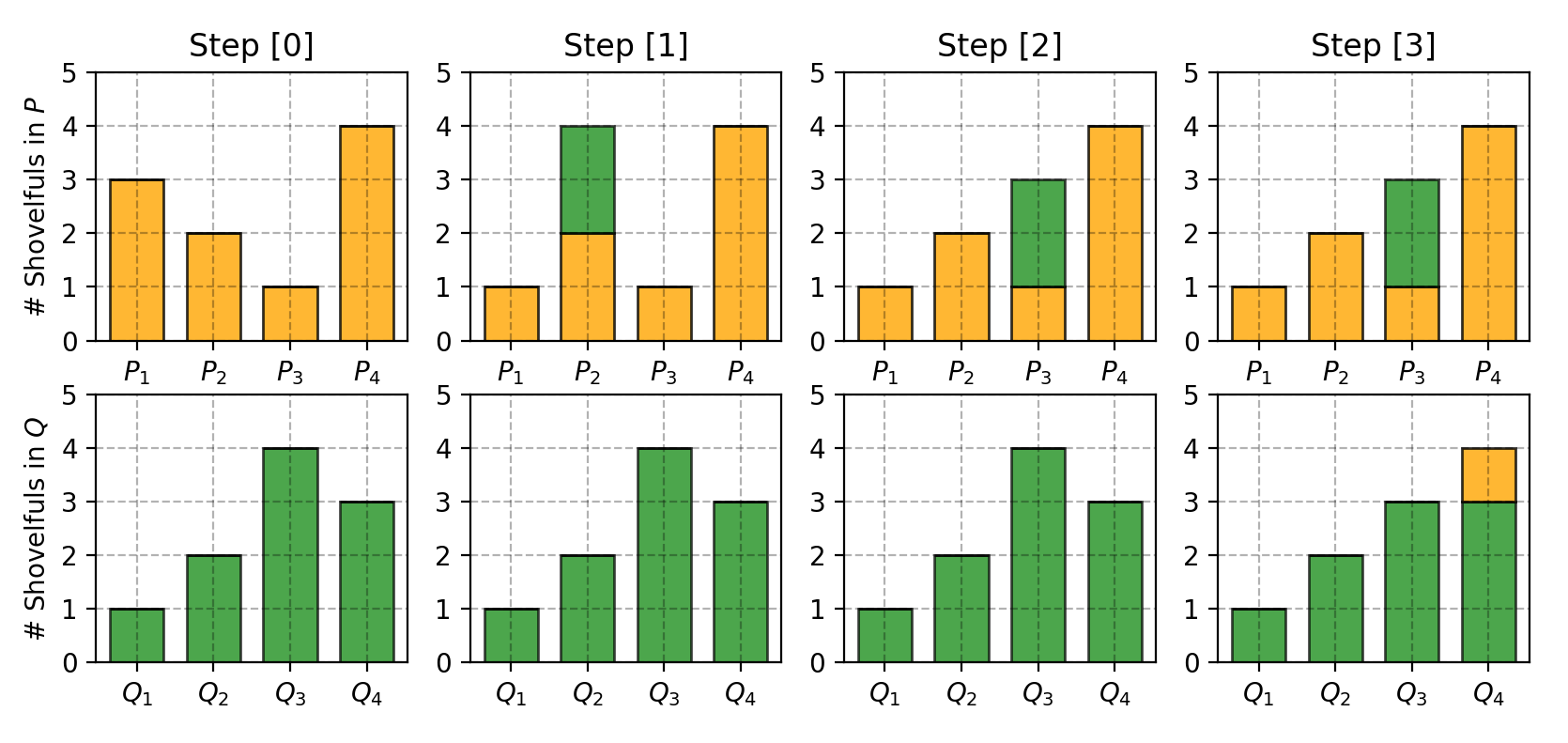
Fig. 7. P와 Q가 같아지도록 흙더미를 옮기는 과정을 단계별로 나타낸 그림.
연속형 확률분포이 경우에는 아래와 같은 공식을 사용합니다.
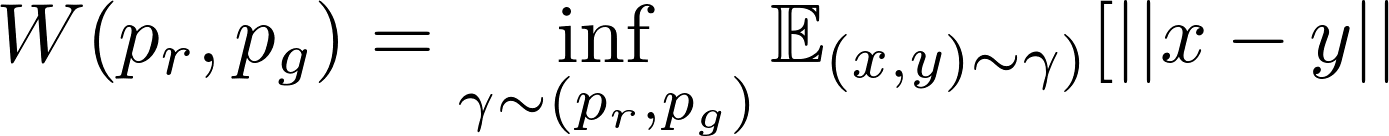
이 공식에서 Π(pr, pg)는 pr과 pg 사이의 가능한 모든 결합확률분포(joint probability distribution)의 집합을 나타냅니다. 이 집합에 속하는 감마라는 분포는, γ ∈ Π(pr,pg), 위의 예시처럼 흙더미는 옮기는 한가지 방법에 대응됩니다(연속확률분포라는 점은 다르고요). 정확하게 설명하면, γ(x, y)는 x가 y분포를 따르게 하기 위해서 x에서 y로 옮겨야하는 흙더미의 비율을 나타냅니다. 따라서 γ(x, y)를 x에 대한 marigal distribution으로 계산하면 pg와 같아집니다. ∑x γ(x,y)=pg(y) (x를 pg를 따르는 y가 되도록 흙더미를 옮기고 나면, 마지막 분포는 pg와 같아지겠죠) 마찬가지로 y에 대한 marginal distribution은 pr(x)가 됩니다. ∑y γ(x,y)=pr(x)
x를 출발점으로 하고 y를 도착점으로 할 때, 전체 옮겨지는 흙의 양은 γ(x,y)이고, 이동하는 거리는 ||x-y||이기때문에 총 비용은 γ(x,y)*||x-y||가 됩니다. 모든 (x, y)경우에 대해서 기대 비용을 구하면 아래와 같습니다.
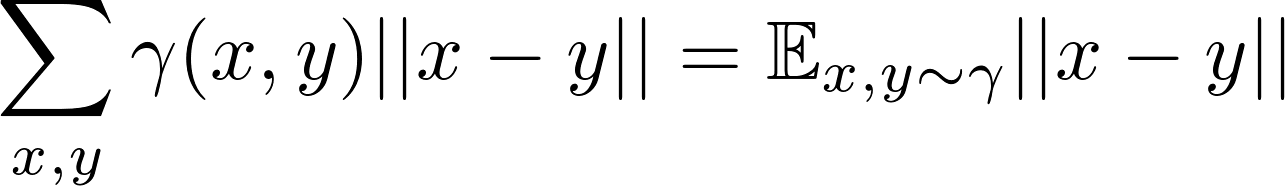
최종적으로 우리는 EM distance로 계산되는 모든 값 중에서 최소값을 선택합니다. 위의 Wasserstein distance 정의에서 inf는 최소값에만 관심이 있다는 표시입니다. (infimum, greatest lower bound로도 알려져있습니다)
why Wasserstein is better than JS or KL divergence?
저차원 매니폴드에서 두 분포가 겹치지 않을 때, Wasserstein distance는 여전히 의미있는 값과 연속적으로(smooth, 미분가능하게) 표현됩니다.
WGAN 논문에서는 간단한 예제를 통해서 이 아이디어를 설명합니다.
P와 Q라는 두 분포가 있다고 가정합시다.
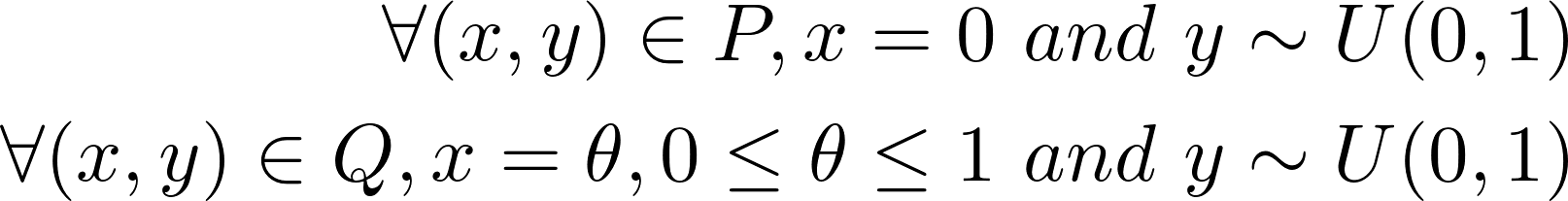
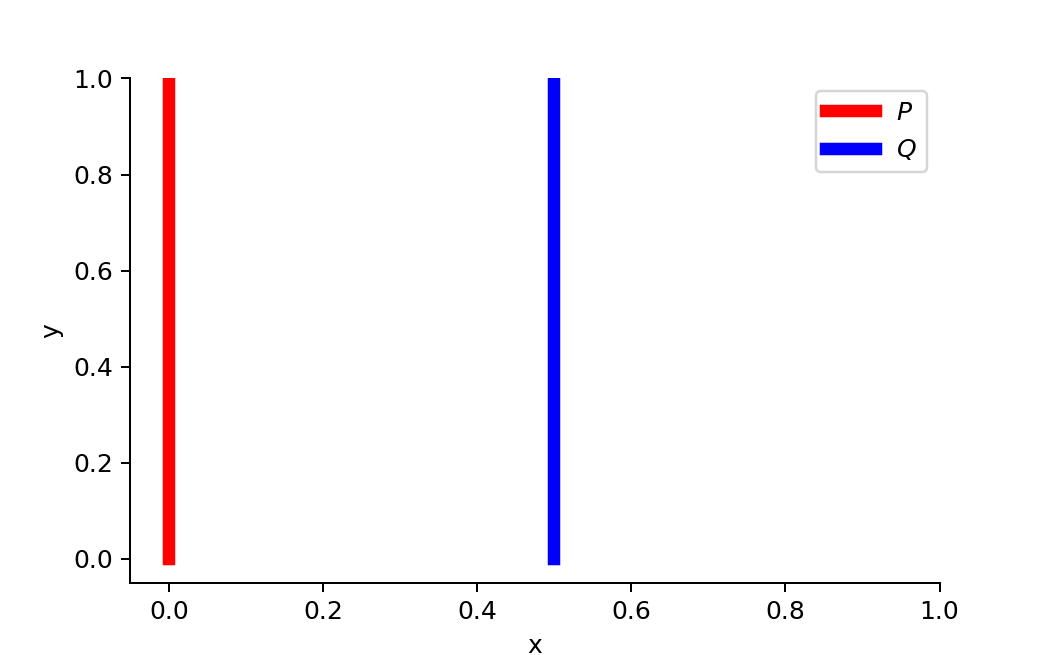
Fig.8. θ가 0이 아니라면 P와 Q는 겹치지 않음.
when θ≠0 :
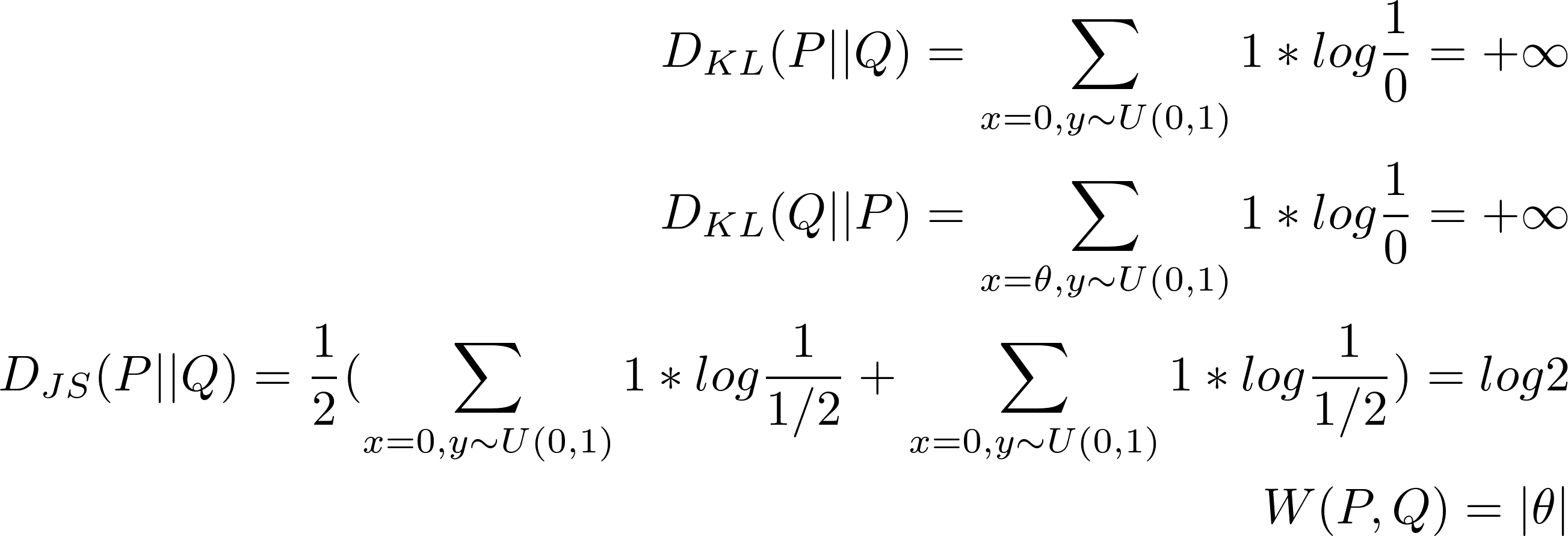
when θ = 0일때는 두 분포는 완전히 겹쳐집니다 :
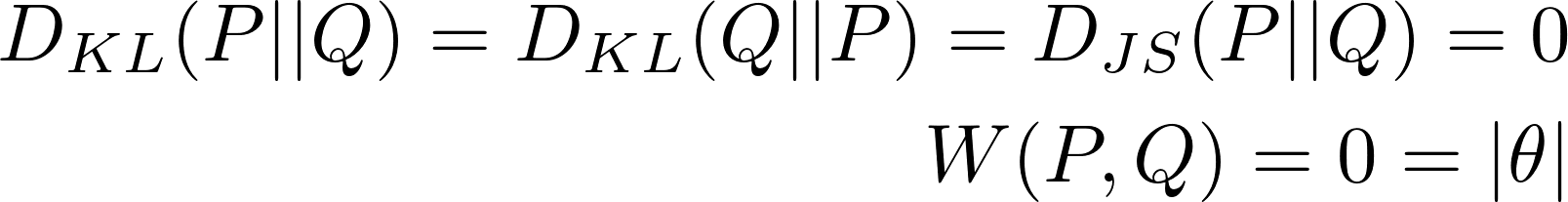
DKL는 두 분포가 서로 겹치지 않을 때는 무한대 값을 갖게 되고, DJS는 θ가 0일 때 값이 갑자기 튀게 되어 미분불가능해집니다. Wasserstein metric만 연속적인 값으로 측정되며, 이러한 성질은 그래디언 디센트를 사용하여 안정적인 학습을 하는데 큰 도움이 됩니다!
Use Wasserstein distance as GAN loss function
infγ∼Π(pr,pg)를 구하기 위해 Π(pr, pg)에 속하는 모든 경우의 결합확률분포를 추적하는 것은 불가능합니다. 논문의 저자는 Kantorovich-Rubinstein duality를 이용해 새롭게 변형된 형태를 제안하였습니다.
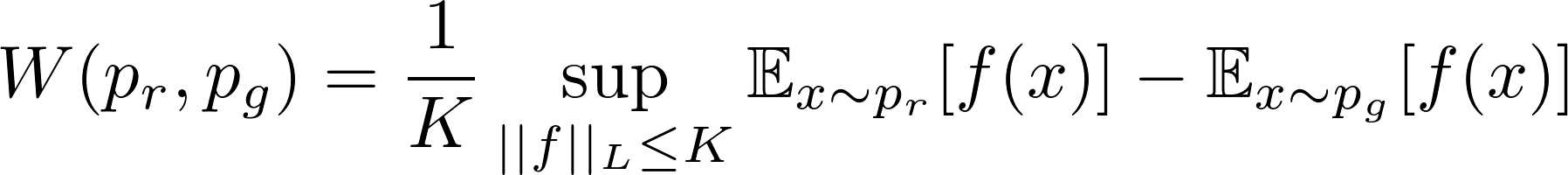
sup(supremum)는 inf(infimum)의 반대로 least upper bound를 측정하고자 하는 것, 즉 최대값을 의미합니다.
Lipschitz continuity?
새로운 형태의 wasserstein metric에서 f는 ||f||L ≤ K라는 조건을 만족해야합니다. 즉, K-Lipschitz continuous 조건을 만족해야합니다.
모든 x1, x2 ∈ ℝ 에 대해서 |f(x1) -f(x2)| ≤ K |x1 - x2| 를 만족하는 실수값 K≥0이 존재할 때, 실수형 함수 f : ℝ → ℝ 가 K-Lipschitz continuous를 만족한다고 합니다.
여기서 K는 f(.)의 Lipschitz 상수라고 부릅니다. 모든 점에서 연속적으로 미분가능한 함수는 Lipschitx continuos합니다. 왜냐하면 미분은 |f(x1) -|f(x2)| / |x1 - x2|이고, 미분가능하다는 것은 이값이 제한되어 있음을 의미하기 때문입니다. 하지만 반대로 Lipschitz continuous function이라고 해서 항상 모든 점에서 미분 가능함을 의미하지 않습니다. (그 예로 f(x) =|x|가 있습니다.)
Wasserstein distance를 어떻게 변경하는지 설명하는 것은 그 자체로서 의미가 있기때문에 여기서는 자세한 내응은 스킵하도록 하겠습니다. 만약 선형 프로그래밍을 사용하여 Wasserstein metric를 계산하는 방법이 알고 싶거나, Kantorovich-Rubinstein Duality를 통해 어떻게 그 쌍대 문제로 변형되는지 알고 싶다면 이 포스트를 참고하세요.
함수 f가 w를 파라미터로 가진 K-Lipschitz continuous functions의 집합, {fw}w ∈ W 에서 추출되었다고 가정해봅시다. 수정된 Wassertein-GAN에서 discriminator는 좋은 fw를 찾기위해 학습이 되고, 손실함수는 pr과 pg 사이의 wasserstein distance를 측정하게 됩니다.
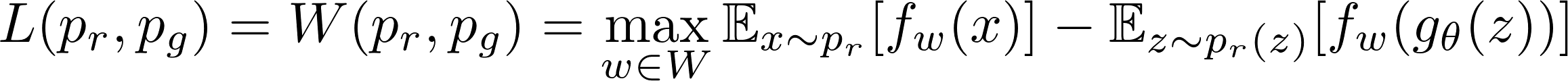
따라서 discriminator는 더이상 진짜 데이터와 generator가 생성한 가짜 데이터를 식별하는 직접적인 기준치가 아닙니다. 대신에 Wasserstein distance를 계산하기 위기 위해 사용되는 K-Lipschitz continuous function을 학습하게 됩니다. 학습과정에서 손실함수가 작아질수록, wasserstein distance는 점점 작아지게 되어 generator의 결과값은 실제 데이터 분포와 점점 가까워지게 됩니다.
한가지 중요한 문제는 모든 것이 잘 작동하기 위해서는 학습과정에서 K-Lipschitz continuity를 유지하도록 하는 것입니다. 논문에서는 간단하지만 매우 실용적인 트릭을 사용하였습니다. 그래디어트가 업데이트될 때마다, 가중치 w를 아주 작은 범위로, 예를 들면 [-0.01, 0.01]로 고정시면 컴팩트한 파라미터 공간 W가 되도록 합니다. fw는 하한선과 상한선이 생기게 되어 Lipschitz continuity를 유지하게 됩니다.

Fig.9. Wasserstein GAN 알고리즘 (Image source : Arjovsky, Chintala, & Bottou, 2017.)
원래의 GAN 알고리즘과 비교하여 WGAN은 다음과 같은 변경을 수행합니다 :
- 손실함수가 업데이트된 후, 가중치는 고정된 작은 범위 [-c, c]사이값으로 고정됩니다.
- Wasserstein distance로 부터 유도된 새로운 손실함수를 사용합니다. (로그 형태가 더이상 아닙니다) discriminator는 직접적인 식별자 역할을 하지 않고 실제 데이터 분포와 생성자의 분포 간에 거리를 추정하는 것을 도와주게 됩니다.
- 논문의 저자는 Adam과 같은 모멘텀 기반의 옵티마이저를 사용하는 것이 학습과정에서 불안정성을 야기하기 때문에, 실험적으로 RMSProp 옵티마이저를 사용하는 것을 추천하였습니다. (이 부분에 대해서는 명확한 이론적 설명을 하지 않았습니다)
슬프게도 Wasserstein GAN은 완벽하지 않습니다. 심지어 WGAN 논문에서도 “가중치를 고정시키는 것은 명백히 Lipschitz constraint를 강제하는 끔찍한 방법”이라고 했습니다.(웁스!) WGAN은 여전히 학습이 불안정하거나, 가중치를 고정시킨 후 수렴속도가 느려지거나(고정 범위가 너무 큰 경우에 해당), 그래디언트가 사라지는(고정 범위가 너무 작은 경우)문제가 생길수 있습니다.
이후 가중치를 고정시키는 방법 대신에 그래디언트 패널티를 사용하는 등의 개선책이 논의되기도 하였습니다.Gulrajani et al. 2017. 여기서는 자세히 설명하진 않겠습니다.
Example : Create New Pokemons!
carpedm20/DCGAN-tensorflow을 작은 데이터셋 Pokemon sprites에 적용해보았습니다. 같은 종이지만 다른 레벨까지 포함하여 총 900장의 포켓몬 이미지가 있습니다.
모델이 만든 새로운 포켓몬 종류를 확인해보겠습니다. 불행히도 학습데이터가 적어서 새로운 포켓몬은 디테일이 잘 살아나지 않고 러프한 모양압니다. 전체적인 형태나 색깔은 학습 에폭이 진행될수록 더 나아지는 것으로 보이네요. 와우!

Fig.10. 포켓몬 이미지에 carpedm20/DCGAN-tensorflow를 학습시킨 결과. epoches = 7, 21, 49에서 샘플 결과들.
만약 carpedm20/DCGAN-tensorflow에 관심이 있고, 이 알고리즘을 WGAN이나 그래디언 패널티를 사용한 WGAN으로 수정하는 것이 궁금하다면 lilianweng/unified-gan-tensorflow를 확인해주세요.
Reference
[0] Original post : lilianweng/fromGANtoWGAN
[1] Goodfellow, Ian, et al. “Generative adversarial nets.” NIPS, 2014.
[2] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. “Improved techniques for training gans.” In Advances in Neural Information Processing Systems.
[3] Martin Arjovsky and Léon Bottou. “Towards principled methods for training generative adversarial networks.” arXiv preprint arXiv:1701.04862 (2017).
[4] Martin Arjovsky, Soumith Chintala, and Léon Bottou. “Wasserstein GAN.” arXiv preprint arXiv:1701.07875 (2017).
[4] Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, Aaron Courville. Improved training of wasserstein gans. arXiv preprint arXiv:1704.00028 (2017).
[5] Computing the Earth Mover’s Distance under Transformations
[6] Wasserstein GAN and the Kantorovich-Rubinstein Duality
[7] zhuanlan.zhihu.com/p/25071913
[8] Ferenc Huszár. “How (not) to Train your Generative Model: Scheduled Sampling, Likelihood, Adversary?.” arXiv preprint arXiv:1511.05101 (2015).
Comments