
Detecting Spacecraft Anomalies Using LSTMs and Nonparametric Dynamic Thresholding
Kyle Hundman et al (2018 KDD, NASA)
Implementation : https://github.com/khundman/telemanom
Abstract
- NASA의 우주선은 많은 양의 원격 데이터를 송신합니다. NASA 연구원들은 우주선이 보내는 데이터들을 이용해 엔지니어의 모니터링 부담과 운영 비용을 줄이기 위해서 어노말리 디텍션 시스템을 구축/개선하고 있습니다.
- 이 논문은 우주선 데이터에 적용가능한 어노말리 디텍션 알고리즘을 제안합니다. expert-labeled 어노말리 데이터가 포함된 Soil Moiture Active Passive(SMAP) satelite와 Mars Science Laboratory(MSL) rover 데이터에 LSTM 모델을 적용한 새로운 어노말리 디텍션 방법을 제안하였습니다.
- 이 방식은 지도학습에 의한 모델 학습이 아니라 unsupervised and nonparametric anomaly thresholding approach에 해당하며, 후반부에는 false positive를 줄이기 위한 방법들을 추가적으로 논의하였습니다.
Introduction
- 우주선에서는 온도, 방사선, 전력, 소프트웨어의 계산량 등 복잡하고 방대한 양의 데이터들이 수집되며 각 데이터들의 어노말리 디텍션은 매우 중요한 문제입니다.
- 기존의 어노말리 디텍션 방법들은 사전에 정의된 제한값을 벗어나면 발생하는 알람 형식이거나 수작업이 포함된 시각화 방법과 채널별 통계 분석을 이용합니다. 이러한 방식은 적지않은 전문가적 지식을 요구하며 각 규칙을 정의하거나 노말 범위를 업데이트하는데 수기 작업이 필요합니다. 특히 하루에 85테라바이트의 데이터가 생성되는 방대한 양의 데이터를 처리하는 빅데이터 시스템에서는 더욱 문제가 악화됩니다.
-
다변량 시계열 데이터의 어려운 이슈이 우주선 데이터를 분석하는데 여전히 유효하고, 라벨링 부족한 상황에서 비지도학습방식이나 세미지도학습방법의 필요성 역시 존재합니다. 또한 대부분의 실제 시계열 데이터가 그러하듯이 non-stationary한 특징과 현재 컨텍스에 매우 종속된 특징을 갖는 것들도 어려운 점입니다. 또한 엔지니어에게 인사이트를 줄수 있도록 interpretability도 필요한 요소입니다. 마지막으로 false positive와 false negative를 최소화하면서 적절한 발런스를 찾는 것 역시 중요합니다.
- Contributions
- 이 논문은 LSTM을 이용하여 높은 예측력을 얻고, 각 채널별 예측모델을 구축하여 전체 시스템의 interpretability를 유지하였습니다.
- 일단 모델의 예측값을 이용해 실제 값과의 오차(residual)을 이용해 어노말리인지 판단하게 됩니다. 이때 nonparametric, dynamic, and unsupervised thresholding approach를 사용합니다. 이 방식을 이용해 신호의 다양성, 비정상성과 노이즈에 대해서 논의하고 이후 사용자 피드백과 과거 데이터를 이용해 시스템을 향상시키는 방법도 함께 논의하였습니다.
Background and Related Work
- 일반적으로 3가지 종류의 어노말리가 존재합니다.
- point anomaly : low density regions에 해당하는 싱글 포인트가 발생하는 것을 의미합니다.
- contextual anomaly : low density region은 아니지만 로컬 값들과 비교했을때는 비정상적인 싱글 포인트가 발생하는 경우입니다.
- collective anomaly : 여러개의 시퀀스값들이 비정상적일 때를 의미합니다.
- 가장 기본적인 어노말리 디텍션은 out-of-limit(OOL)입니다.
- 그 외 clustering based approaches, nearest neighbors approaches, expert systems, dimensionality reduction approaches 등이 있지만, parameter specification, interpretability, generalizability, or computational expense 등의 단점이 존재합니다.
- 기존에도 우주선에 적용가능한 어노말리 디텍션 방법들이 다수 연구되었습니다. ISACS-DOC, IMSE, ELMER, Deep Space One spacecrash 등과 같은 프로젝트들이 있었습니다만, 여전히 직관적인 결과를 얻을수 있고 관리가 쉬운 OOL 방식이 사용되고 있습니다.
- 최근 딥러닝이 발전하면서 seq-to-seq 학습에서도 큰 성과를 얻고 있습니다. LSTM과 RNN계열의 모델을 이용해 과거값을 이용해 예측값을 학습할수 있습니다. 정상데이터로 학습된 LSTM을 이용하여 정상적인 상태에서의 시스템을 모니터링할수 있습니다. LSTM은 차원축소를 하지 않아도 다변량 시계열 데이터에 적용가능하고, 특별한 도메인 날리지를 요구하지 않기 때문에 다른 우주선에 일반적으로 적용가능합니다.
Method
Telemetry Value Prediction with LSTMs
- single channel models : 여기서는 각 채널별로 모델을 생성합니다. 싱글 모델의 장점은
- 채널 레벨로 추정가능하다는 것
- 로우 레벨의 어노말리를 그룹핑하여 서브시스템 형태로 통합할수 있습니다. 이로인해서 더 세분화된 시스템 관리가 가능합니다.
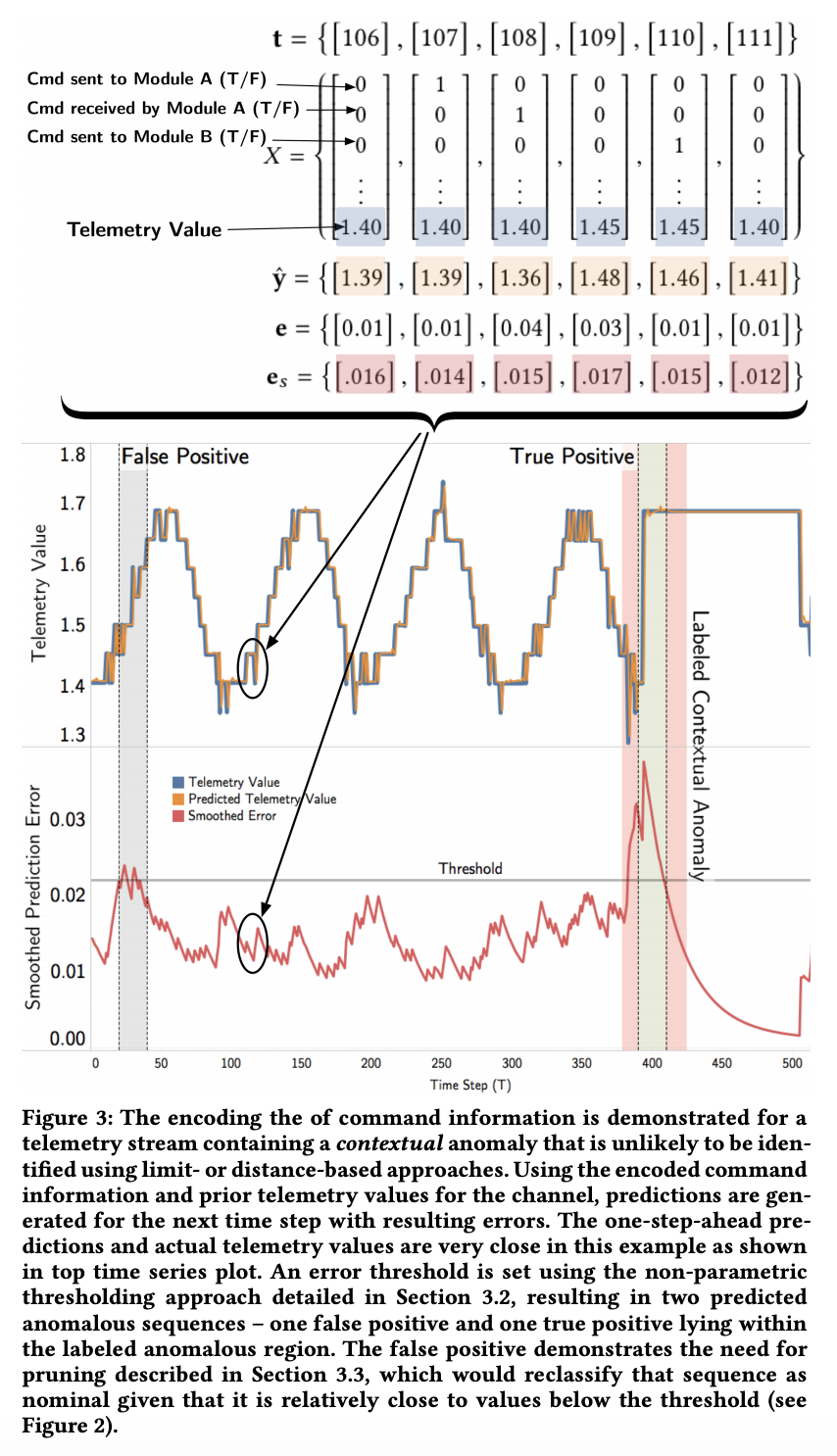
- predicting values for a channel : 주어진 시계열은 \(X=\left\{ x^{(1)}, x^{(2)}, ..., x^{(n)} \right\}\) 이고, \(x^{(t)}\)는 m차원의 벡터를 나타내고 각 element가 채널의 입력값을 나타냅니다. \(l_s\)는 모델 입력으로 사용한 시퀀스의 길이를 의미합니다. \(l_p\)는 예측할 시퀀스의 길이를 나타내며 이 논문에서는 계산 속도를 위해서 1을 사용하였습니다. 또한 각 채널별 예측을 수행하기 때문에 예측값의 차원 d=1로 설정하였습니다. \(x^{(t)}\) 는 각 채널의 이전 값과 함께 우주선에 전송된 encoded command information이 포함됩니다. 커멘드를 생성한 것과 커멘드를 수신한 정보가 one-hot encoded되어 입력으로 사용됩니다. (Fig3 참고)
Dynamic Error Thresholds
- 수천개의 원격 데이터를 자동으로 모니터링하기 위해서는 계산속도가 빠르고, 예측값이 어노말리인지 판단하는 과정이 비지도 학습방식이어야합니다. 이를 위한 일방적인 방식은 과거의 스무딩된 에러들을 가우시안 분포로 가정하여 새로운 에러값과 이전 값들의 compact representation간의 빠른 비교가 되도록 하는 것입니다. 하지만 이 방식은 가우시안 분포라는 가정이 맞지 않을때는 문제가 되기때문에 여기서는 어떠한 가정없이 extreme values를 찾아내는 방식을 제안합니다. distance-based method가 비슷하지만 기존의 distance based method는 각 포인트들을 인근의 k개와 비교하기 때문에 계산량이 많다는 단점이 있습니다.
- Errors and Smoothing : 우선 예측값과 실제값 사이의 에러를 계산합니다.
- 이때 각 에러값들은 스무딩(smoothed)된 값들을 사용합니다. 정상적인 상태라도 값이 급변하여 완벽하게 예측이 되지 않아 스파이크 형태의 에러값이 생기는 경우가 종종 있기 때문입니다. 여기서는 Exponentially-weighted average(EWMA)를 사용하였습니다.
-
값들이 정상인지 판단하기 위해서는 threshold를 설정하여 사용하였습니다. threshold보다 큰 값은 anomalies로 분류됩니다.
-
Threshold Calculation and Anomaly Scoring : 일반적으로 threshold를 결정하기 위해서 지도학습방식으로 학습을 합니다. 하지만 이 방식은 라벨링된 데이터가 필요하기 때문에 여기서는 비지도학습 형태로 threshold를 결정하는 방법을 제안하였습니다.
- Where \(\epsilon\) is determined by:
- such that:
- anomaly score
Mitigating False Positives
- Pruning Anomalies
- prediction-based 방식은 과거데이터의 갯수(h)에 영향을 많이 받습니다.
- 너무 많은 과거 데이터를 이용할 경우, 실시간 모니터링 시나리오에서 계산 비용이 너무 크게 됩니다. 너무 적은 과거 데이터를 이용할 경우, 좁은 컨텍스트만 고려하여 판단하기 때문에 false positive가 많아지게 됩니다. 그렇다고 false positive를 너무 줄이다보면 감지되지 못한 어노말리를 찾기위해서 휴먼 인스펙션 부담이 커지게 됩니다. 따라서 false positives를 약화시키기 위해서 pruning procedure를 도입하였습니다.
- \(\boldsymbol{e_{max}}\) is created containing \(max(\boldsymbol{e_{seq}})\) for all \(\boldsymbol{e_{seq}}\) sorted in descending order. we also add the maximum smoothed error that isn’t anomalous, \(max(\left\{ e_s \in \boldsymbol{e_s} \in \boldsymbol{E_{seq}} \vert e_s \ni \boldsymbol{e_a} \right\} )\), to the end of \(\boldsymbol{e_{max}}\).
- The sequence is then stepped through incrementally and the the percent decrease \(d^{(i)} = ( e_{max}^{(i-1)} - e_{max}^{(i)}) / e_{max}^{(i-1)}\) at each step \(i\) is calculated where \(i \in \left\{1, 2, ..., (\left\vert \boldsymbol{E_{seq}} \right\vert + 1)\right\}\).
- If at some step \(i\) a minimum percentage decrease p is exceeded by \(d^{(i)}\), all \(e_{max}^{(j)} \in \boldsymbol{e_{max}} \vert j \lt i\) and their corresponding anomaly sequences remain anomalies.
- If the minimum decrease p in not met by \(d^{(i)}\) and for all subsequent errors \(d^{(i)}, d^{(i+1)}, ..., d^{(i+\left\vert \boldsymbol{E_{seq}} \right\vert + 1)}\) those smoothed error sequences are reclassified as nominal.
- 이와 같은 pruning 과정은 정상적인 흐름에서의 노이즈가 어노말리로 판단되는 것을 방지합니다. 또한 단순히 값과 값을 여러번 비교하여 판단하는 것보다 잠재가능성이 있는 비정상적인 시퀀스 중에 맥시멈 에러갓을 비교하는 것이 더 효율적이라는 장점이 있습니다.
- Learning from History
- false postive를 감소시키는 두번째 전략은 적은양이더라도 과거의 비정상 값들 또는 라벨링된 데이터를 적용시키는 것입니다. 각 채널 데이터에서 일정 비율 이상 수집된 값들을 어노말리로 판단하여 미니멈 값 \(s_{min}\)로 설정합니다. 이후 새로운 값들 중 \(s \lt s_{min}\)조건을 만족하는 경우 정상값으로 분류합니다. \(s_{min}\)는 precision과 recall사이의 적절한 밸러스가 되도록 설정할수 있습니다.
- 또는 유저가 제공하는 라벨링 정보를 이용하여 \(s_{min}\)를 설정할수도 있습니다.
Comments