
recommender systems 2
추천시스템에 대해서 알아보자! - 지난 1편에서는 앤드류 응의 강의를 통해서 추천시스템의 전반적인 내용에 대해 알아보았습니다. 이번에는 Collaboratvie Filtering에 대해서 더 자세히 알아보고자 합니다.
Collaborative filtering을 이용해 상품을 추천하는 방법은 크게 2가지 접근 방식이 있습니다. neighborhood method와 latent factor models 입니다.
Neighborhood method
neighborhood method는 아이템간 혹은 유저간 관계를 계산하는 것에 중점을 둡니다.
유저 기반의 방법은 해당 유저와 유사한 다른 유저를 찾은 후, 비슷한 유저가 좋아하는 아이템을 추천하는 방식입니다. 그림1에서처럼, 세가지 영화를 좋아하는 Joe를 위해서, 세가지 영화를 동일하게 좋아하는 비슷한 유저를 찾습니다. 이들이 좋아하는 영화 중에서 가장 인기있는 영화인 Saving Private Ryan(라이언 일병 구하기, denoted #1)를 Joe에게 추천할 수 있습니다.
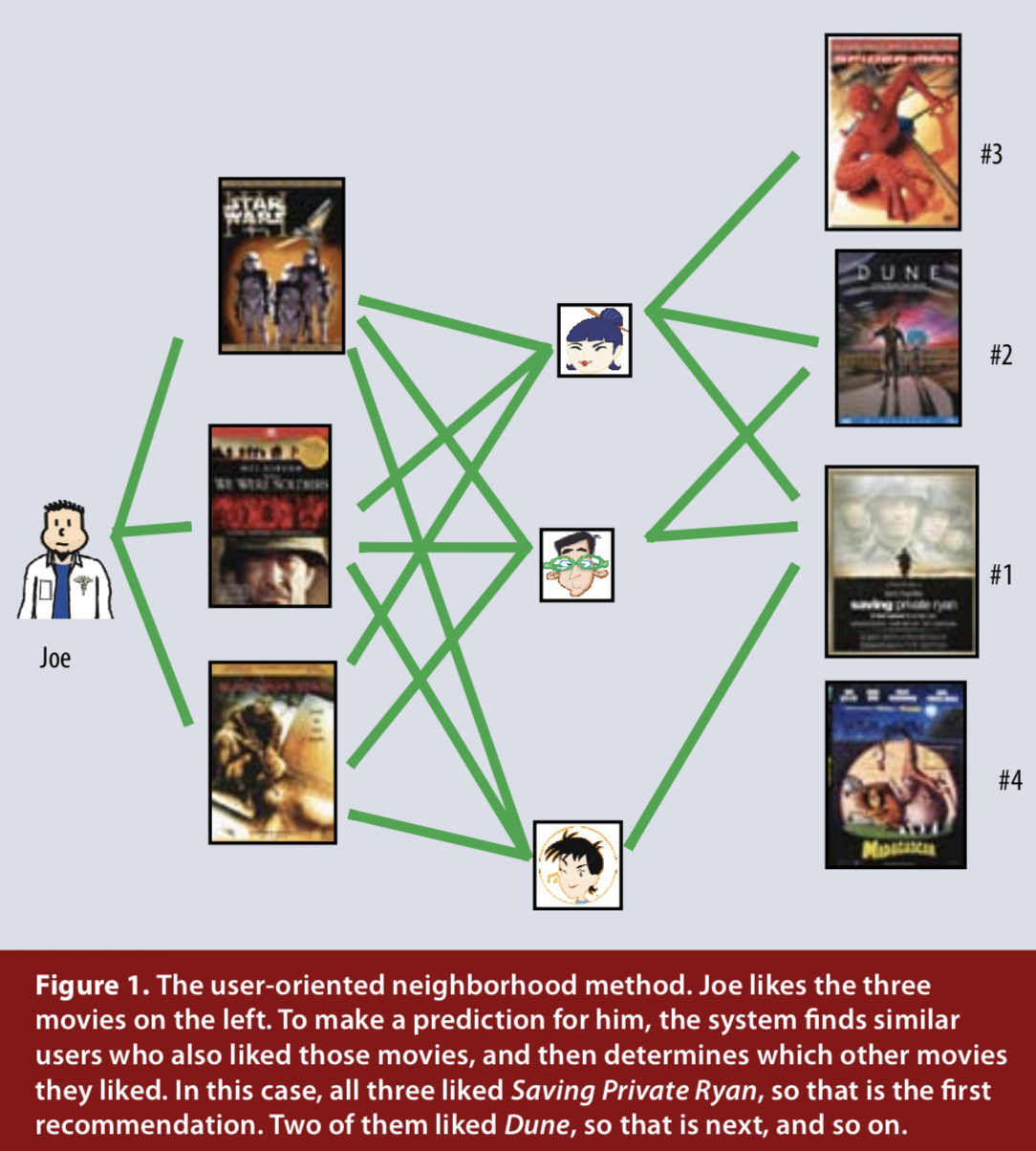
그림1. user-oriented neighborhood method (Image source: Fig 1 in Yehuda Koren et al., 2009)
아이템 기반의 방법은 해당 유저가 좋아하는 아이템과 유사한 아이템을 추천하는 방식입니다. 유사한 아이템은 해당 유저에게 동일한 평가를 받을 가능성이 크기 때문입니다. 예를 들어, Saving Private Ryan와 유사한 영화는 전쟁 영화거나, 톰행크스가 나오거나, 스필버그 감동의 다른 영화일 수 있습니다. 만약 누군가가 Saving Private Ryan를 어떻게 평가할지 궁금하다면, 그 사람이 실제로 본 영화 중에서 Saving Private Ryan와 유사한 영화를 어떻게 평가했는지 찾는 것과 같은 맥락입니다.
similarity
neighborhood method는 두 유저간 혹은 아이템간 유사도를 계산해야합니다. 유사도를 정량적으로 평가하기 위해서 일반적으로 2가지 measure를 사용합니다.
(1) pearson correlation coefficient
유저 \(u\)와 유저 \(v\)의 유사도를 \(s(u, v)\)로 나타내면,
\(s(u, v) = { {\sum_{i \in I_{uv}} (r_{ui} - \mu_u) \cdot (r_{vi} - \mu_v)}\over{\sqrt{\sum_{i \in I_{uv}} {(r_{ui} - \mu_u)}^2} \cdot \sqrt{\sum_{i \in I_{uv}} {(r_{vi} - \mu_v)}^2}}}\)
- \(r_{ui}\)는 사용자 u가 아이템 i에 대해서 평가한 평점
- \(I_{uv}\)는 유저 \(u\) 와 유저 \(v\) 모두에 의해 평가된 아이템의 집합
- \(\mu_u\)는 유저 \(u\)의 평균 평점과 \(\mu_v\)는 유저 \(v\)의 평균 평점
마찬가지로 아이템 \(i\)와 아이템 \(j\)의 유사도를 \(s(i, j)\)로 나타내면,
\(s(i, j) = { {\sum_{u \in U_{ij}} (r_{ui} - \mu_i) \cdot (r_{uj} - \mu_j)}\over{\sqrt{\sum_{u \in U_{ij}} {(r_{ui} - \mu_i)}^2} \cdot \sqrt{\sum_{u \in U_{ij}} {(r_{uj} - \mu_j)}^2}}}\)
- \(U_{ij}\)는 아이템 \(i\) 와 아이템 \(j\)를 모두 평가한 유저들의 집합
- \(\mu_i\)는 아이템 \(i\)의 평균 평점과 \(\mu_j\)는 아이템 \(j\)의 평균 평점
의미적으로는 유저 \(u\)(혹은 아이템 \(i\)) 평점이 1점 증가할때, 유저 \(v\)(혹은 아이템 \(j\)) 평점은 어느정도 증가/감소하는지를 평가하는 것입니다. 상관계수는 상관관계가 클수록 \(\pm1\)에 가까운 값을 갖고, 0일 경우 상관관계가 거의 없는 것을 의미합니다.
(2) Cosine Similarity
코사인 유사도는 두 non-zero vector간의 코사인 각을 측정하는 것입니다. 두 벡터 A와 B의 코사인 유사도는 두 벡터의 내적을 이용해 정의됩니다. 각도 \(\theta\)가 0도이면 코사인 유사도는 1이 되고, \(\theta\)가 90도이면 코사인 유사도는 0이 됩니다.
\[\begin{align} A \cdot B & = |A| |B| cos \theta \\ \\ similarity = cos \theta & = \frac{A \cdot B}{|A||B|} \\ & = \frac{\sum_{i=1}^{n}A_i \cdot B_i}{\sqrt{\sum_{i=1}^{n}(A_i)^2}{\sqrt{\sum_{i=1}^{n}(B_i)^2}}} \end{align}\]유저 \(u\)와 유저 \(v\)의 유사도를 \(s(u, v)\)로 나타내면,
\[s(u, v) = \frac{\sum_{i \in I_{uv}} r_{ui} \cdot r_{vi} }{ \sqrt{\sum_{i \in I_{uv}}r_{ui}^2} \sqrt{\sum_{i \in I_{uv}}r_{vi}^2} }\]- \(r_{ui}\)는 사용자 u가 아이템 i에 대해서 평가한 평점
- \(I_{uv}\)는 유저 \(u\) 와 유저 \(v\) 모두에 의해 평가된 아이템의 집합
마찬가지로 아이템 \(i\)와 아이템 \(j\)의 유사도를 \(s(i, j)\)로 나타내면,
\[s(i, j) = \frac{\sum_{u \in U_{ij}} r_{ui} \cdot r_{uj} }{ \sqrt{\sum_{u \in U_{ij}}r_{ui}^2} \sqrt{\sum_{u \in U_{ij}}r_{uj}^2} }\]- \(U_{ij}\)는 아이템 \(i\) 와 아이템 \(j\)를 모두 평가한 유저들의 집합
pearson correlation coefficient와 비교하여 평균 평점에 대한 교정이 포함되지 않은 것을 볼수 있습니다.
Matrix Factorization
SGD vs. ALS
Reference
https://en.wikipedia.org/wiki/Collaborative_filtering
https://medium.com/@cfpinela/recommender-systems-user-based-and-item-based-collaborative-filtering-5d5f375a127f
https://datajobs.com/data-science-repo/Recommender-Systems-[Netflix].pdf
http://jeongchul.tistory.com/553
http://nicolas-hug.com/blog/matrix_facto_2
https://datascienceschool.net/view-notebook/fcd3550f11ac4537acec8d18136f2066/
Comments