
Clustering and Unsupervised Anomaly Detection with l2 Normalized Deep Auto-Encoder Representations
Caglar Aytekin, Xingyang Ni, Francesco Cricri and Emre Aksu (Nokia) 2017
Introduction
- Recently, there are many works on learning deep unsupervised representations for clustering analysis.
- Works rely on variants of auto-encoders and use encoder outputs as representation/features for cluster.
- In this paper, l2 normalization constraint during auto-encoder training makes the representations more separable and compact in the Euclidean space.
Related Work
- DEC : First, dense auto-encoder is trained with minimizing reconstruction error. Then, as clustering optimization state, minimizing the KL divergence between auto-encoder representation and an auxiliary target distribution.
- IDEC : proposes to jointly optimize the clustering loss and reconstruction loss of the auto-encoder
- DCEC : adopts a convolutional auto-encoder
- GMVAE : adopts variational auto-encoder
Proposed Method
- Clustering on l2 normalized deep auto-encoder representations
-
after training auto-encoder with loss function, the clustering is simply performed by k-means algorithm.
-
Unsupervised Anomaly Detection using l2 normalized deep auto-encoder representations
Experimental result
- clustering : evaluation metrics - accuracy
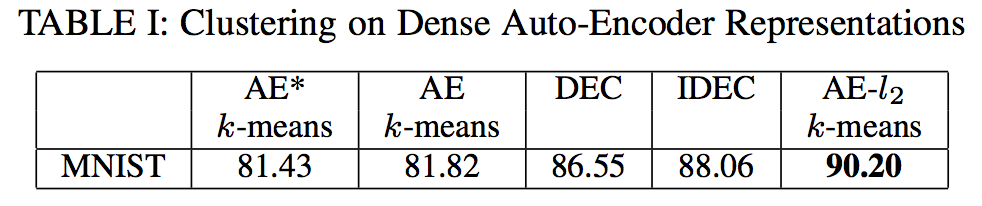
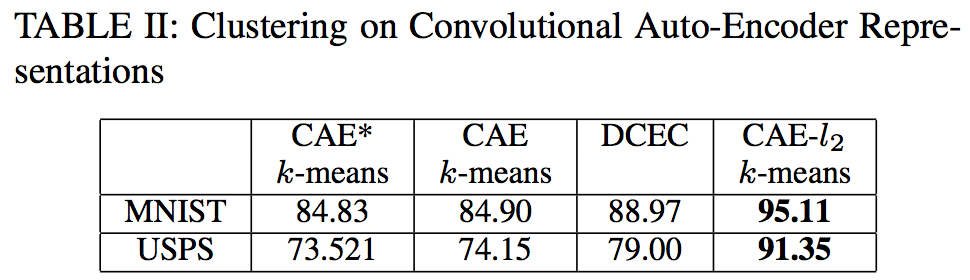

- comparision of normalization method : neither batch nor layer normalization provides a noticeable accuracy increase over CAE + k-means. Moreover in MNIST dataset, layer and batch normalization results into a significant accuracy decrease.
-
This is an important indicator showing that the performance upgrade of our method is not a result of a input conditioning, but it is a result of the specific normalization type that is more fit for clustering in Euclidean space.
- anomaly detection : evaluation metrics - AUC
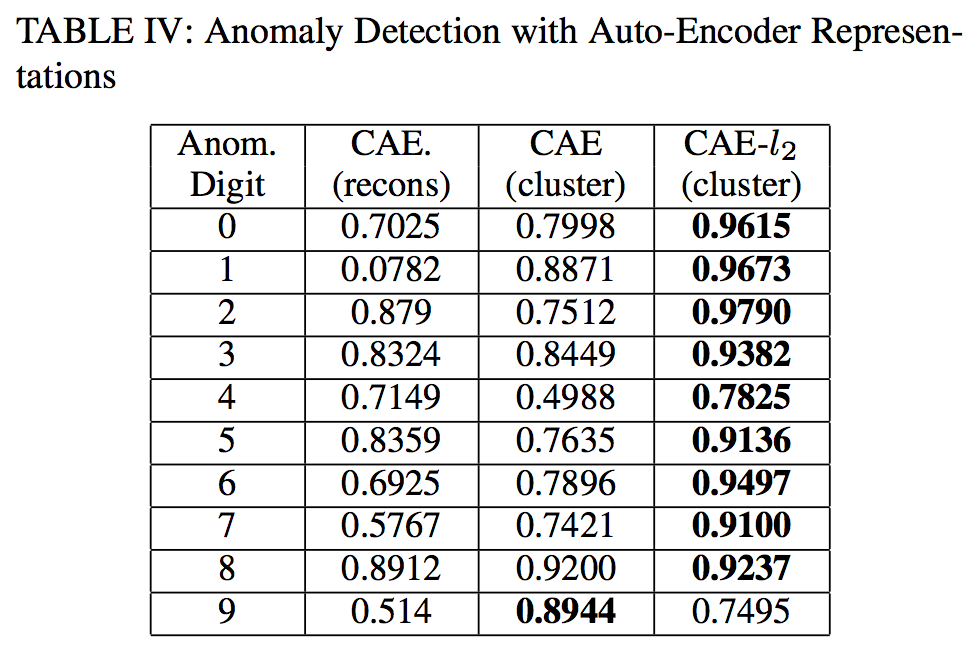
Comments