
Attention? Attention!
이 글은 lilianweng의 Attention? Attention! 포스팅을 번역한 글입니다.
Attention은 최근 딥러닝 커뮤니티에서 자주 언급되는 유용한 툴입니다. 이 포스트에서는 어떻게 어텐션 개념과 다양한 어텐션 메커니즘을 설명하고 transformer와 SNAIL과 같은 모델들에 대해서 알아보고자 합니다.
- What’s Wrong with Seq2Seq Model?
- Born for Translation
- A Family of Attention Mechanisms
- Transformer
- SNAIL
- Self-Attention GAN
- References
Attention은 우리가 이미지에서 어떤 영역을 주목하는지, 한 문장에서 연관된 단어는 무엇인지를 찾는데서 유래하였습니다. 그림1에 있는 시바견을 살펴보세요.

그림1. 사람옷을 입은 시바견. 이미지의 모든 권리는 인스타그램 @mensweardog에 있습니다.
인간은 이미지의 특정 부분을 고해상도로(노란 박스안에 뽀족한 귀) 집중하는 반면, 주변 부분들은 저해상도((눈이 쌓인 배경과 복장)로 인식하고 이후 초점영역을 조정하여 그에 따른 추론을 합니다. 이미지의 작은 패치가 가려져있을때, 나머지 영역의 픽셀들은 그 영역에 어떤 것이 들어가야 하는지를 알려주는 힌트가 됩니다. 우리는 노란 박스 안은 뽀족한 귀가 있어야 하는 것을 알고 있습니다. 왜냐하면 개의 코, 오른쪽의 다른 귀, 시바견의 몽롱한 눈(빨란 박스안에 것들)를 이미 봤기 때문입니다. 반면 이 추론을 하는데 아래쪽에 있는 스웨터나 담요는 별 도움이 되지 못합니다.
마찬가지로, 한 문장이나 가까운 문맥 상에서 단어들간의 관계를 설명할수 있습니다. “eating”이라는 단어를 보았을때, 음식 종류에 해당하는 단어가 가까이 위치에 있을 것을 예상할수 있습니다. 그림2에서 “green”은 eating과 더 가까이 위치해있지만 직접적으로 관련있는 단어는 아닙니다.
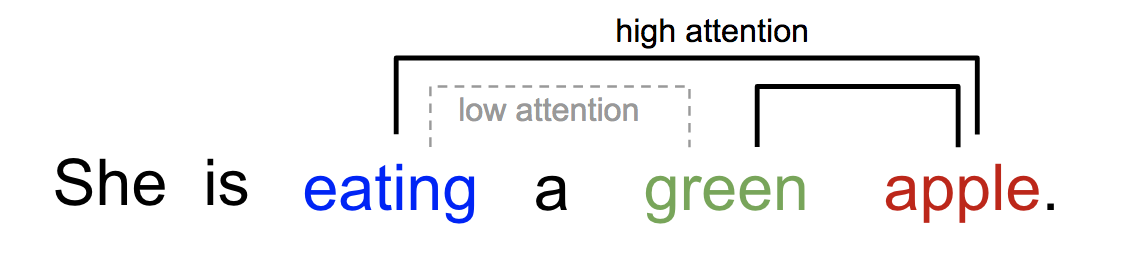
그림2. 한 단어는 같은 문장의 단어들에 서로 다른 방식으로 주목하게 만듭니다.
간단히 말해, 딥러닝에서 어텐션은 weights의 중요도 벡터로 설명할수 있습니다. 이미지의 픽셀값이나 문장에서 단어 등 어떤 요소를 예측하거나 추정하기 위해, 다른 요소들과 얼마나 강하게 연관되어 있는지 확인하고(많은 논문들에서 읽은 것처럼) 이것들과 어텐션 백터로 가중 합산된 값의 합계를 타겟값으로 추정할 수 있습니다.
What’s Wrong with Seq2Seq Model?
seq2seq 모델은 언어 모델링에서 유래되었습니다. 간단히 말해서 입력 시퀀스를 새로운 시퀀스로 변형하는 것을 목적으로 하며, 이때 입력값이나 결과값 모두 임의 길이를 갖습니다. seq2seq의 예로는 기계번역, 질의응답 생성, 문장을 문법 트리로 구문 분석하는 작업 등이 있습니다.
seq2seq 모델은 보통 인코더-디코더 구조로 이루어져있습니다 :
- 인코더는 입력 시퀀스를 처리하여 고정된 길이의 컨텍스트 벡터(context vector, sentence embedding 또는 thought vector로도 알려진)로 정보를 압축합니다. 이러한 차원 축소된 벡터 표현은 소스 시퀀스의 문맥적인 요약 정보로 간주할수 있습니다.
- 디코더는 컨텍스트 벡터를 다시 처리하여 결과값을 만들어 냅니다. 인코더 네트워크의 결과값을 입력으로 받아 변형을 수행합니다.
인코더와 디코더 모두 LSTM이나 GRU 같은 Recurrent Neural Networks 구조를 사용합니다.
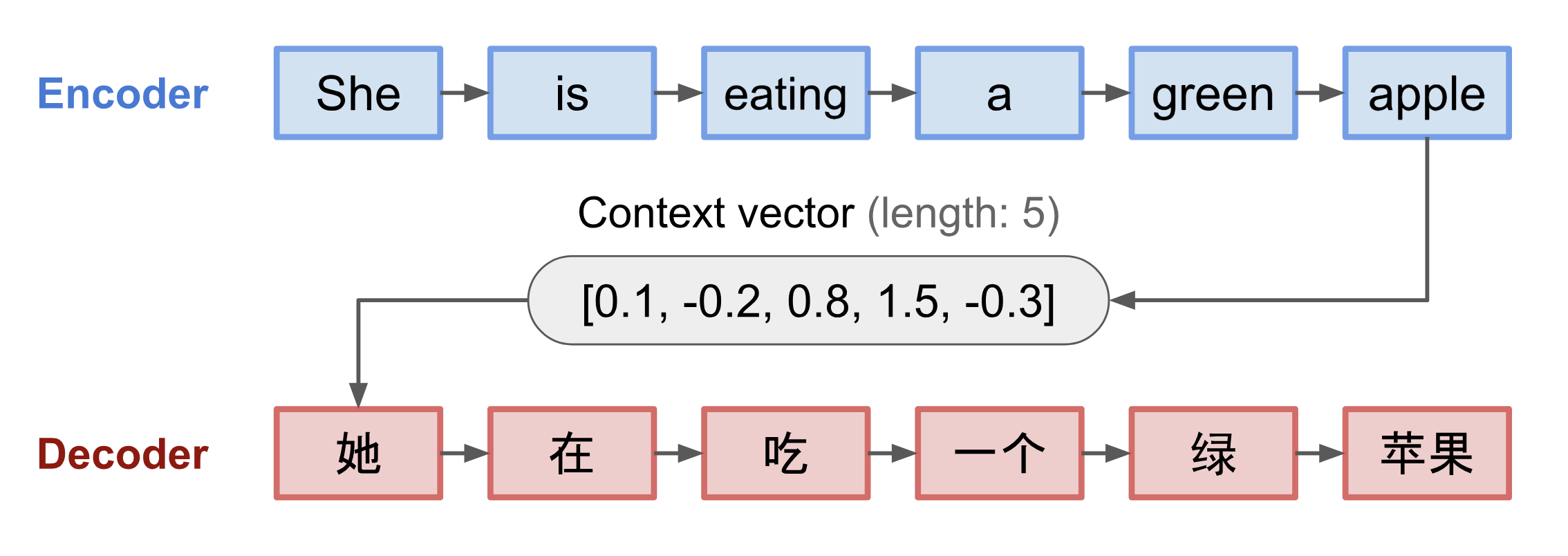
그림3. 인코더-디코더 모델, she is eating a green apple 이란 문장을 중국어로 변형함. 순차적인 방식으로 풀어서 시각화함
고정된 길이의 컨텍스트 벡터로 디자인하는 것의 문제점은 아주 긴 문장의 경우, 모든 정보를 다 기억하지 못한다 것입니다. 일단 전체 문장을 모두 처리하고 나면 종종 앞 부분을 잊어버리곤 합니다. 어텐션 메커니즘은 이 문제점을 해결하기 위해 제안되었습니다. (Bahdanau et al., 2015)
Born for Translation
어텐션 메커니즘은 딥러닝 기반의 기계번역(NMT)에서 긴 소스 문장을 기억하기 위해서 만들어졌습니다. 인코더의 마지막 히든 스테이트의 컨텍스트 벡터뿐만아니라, 어텐션을 이용해 컨텍스트 벡터와 전체 소스 문장 사이에 지름길(shortcuts)을 만들어 사용하는 것입니다. 이 지름길의 가중치들은 각 아웃풋 요소들에 맞게 정의할 수 있습니다.
컨텍스트 벡터는 전체 입력 시퀀스에 접근할수 있고, 잊어 버릴 염려가 없습니다. 소스와 타겟 간의 관계은 컨텍스트 벡터에 의해 학습되고 제어됩니다. 기본적으로 컨텍스트 벡터는 세가지 정보를 사용합니다.
- 인코더 히든 스테이트
- 디코더 히든 스테이트
- 소스와 타겟 사이의 순차적 정보(alignment)
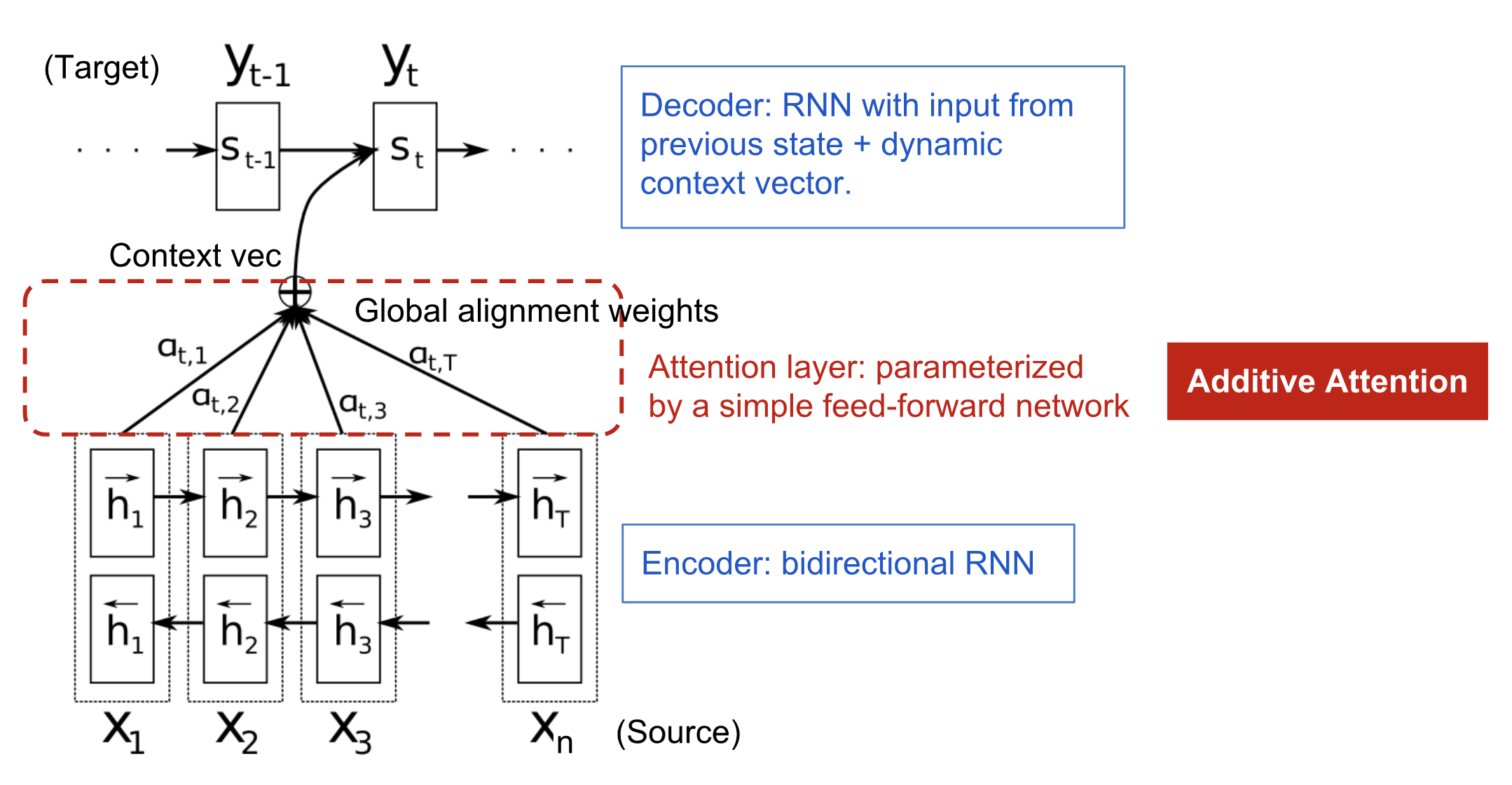
그림4. additive attention mechanism이 있는 인코더-디코더 모델 Bahdanau et al., 2015
Definition
NMT에서 사용되는 어텐션 메커니즘을 과학적으로 정의해보도록 하겠습니다. 우리는 길이가 \(n\)인 소스 문장 \(x\)를 이용해 길이가 \(m\)인 타겟 문장 \(y\)을 만든다고 해봅시다.
\[\mathbf{x} = [x_1, x_2, ..., x_n] \\ \mathbf{y} = [y_1, y_2, ..., y_m]\](볼드 표시된 변수는 벡터를 의미합니다. 이하의 모든 내용에 적용됩니다)
인코더는 bidirectional RNN(또는 다른 구조의 RNN를 갖을 수 있습니다)로 히든 스테이트 \(\mathbf{\overrightarrow{h_i}}\) 와 반대방향 히든 스테이트 \(\mathbf{\overleftarrow{h_i}}\)를 갖습니다. 두 표현식을 간단히 연결(concatenation)하여 인코더의 히든 스테이트를 나타냅니다. 이렇게 하여 한 단어의 앞 뒷 단어를 표시할수 있습니다.
\[\mathbf{h_i} = [\mathbf{\overrightarrow{h_i}}^\top; \mathbf{\overrightarrow{h_i}}^\top]^\top, \ i=1, ..., n\]디코더의 히든 스테이트는 t번째 아웃풋 단어를 만들기 위해 \(s_t = f(s_{t-1}, y_{t-1}, c_t)\) 로 정의됩니다. 이때, \(c_t\)(context vector)는 어라인먼트 스코어를 가중치로 갖는 인코더 히든스테이트의 가중 합계입니다.
\[\begin{align} \mathbf{c_t} & = \sum_{i=1}^{n}\alpha_{t, i} \mathbf{h_i} & ; \ Context \ vector \ for \ output \ y_t \\\\ \alpha_{t,i} & = align(y_t, x_i) & ; \ How \ well \ two \ words \ y_t \ and \ x_i \ are \ aligned. \\\\ & = \frac{score(s_{t-1}, \mathbf{h_{i^{'}}})}{\sum_{i=1}^{n} score(s_{t-1},\mathbf{h_{i^{'}}})} & ; \ Softmax \ of \ some \ predefined \ alignment \ score. & \end{align}\]alignment model은 i번째 입력과 t번째 결과값이 얼마나 잘 매치되는지 확인 한 후 스코어 \(\alpha_{t, i}\)를 이 쌍 \((y_t, x_i)\)에 할당합니다. \({\alpha_{t,i}}\)의 집합은 각 소스의 히든 스테이트가 결과값에 어느정도 연관되어 있는지를 정의하는 가중치 입니다. Bahdanau의 논문은 alignment score \(\alpha\)는 한개의 히든 레이어를 가진 feed-forward network로 파라미터라이즈됩니다. 그리고 이 네트워크는 모델의 다른 부분들과 함께 학습됩니다. 스코어 함수는 아래와 같은 형태이고, tanh는 비선형 활성함수로 사용되었습니다.
\[score(\mathbf{s_t}, \mathbf{h_i}) = \mathbf{v_a^\top} tanh(\mathbf{W_a}[\mathbf{s_t} ; \mathbf{h_i}])\]\(\mathbf{v_a}\) 와 \(\mathbf{W_a}\)는 alignment model에서 학습되는 가중치 메트릭스입니다.
alignment score를 메트릭스로 표시하여 시각적으로 소스 단어와 타겟 단어 사이의 상관관계를 명시적으로 확인할수 있습니다.

그림5. 프랑스어 “L’accord sur l’Espace économique européen a été signé en août 1992”와 영어 “The agreement on the European Economic Area was signed in August 1992”의 기계번역 모델의 Alignment matrix입니다. (출저 : Fig 3 in Bahdanau et al., 2015)
구현 방법은 텐서플로우팀의 튜토리얼을 확인하세요.
A Family of Attention Mechanisms
어텐션으로 인해서 소스와 타겟 시퀀스간의 의존성은 더이상 둘 간의 거리에 의해 제한되지 않습니다. 어텐션은 기계 번역에서 큰 성과를 보였고, 곧 컴퓨터 비전 분야로 확대되었으며(Xu et al. 2015) 다양한 어텐션 메커니즘이 연구되기 시작했습니다.(Luong, et al., 2015;Britz et al., 2017;Vaswani, et al., 2017)
Summary
아래는 대표적인 어텐션 메커니즘의 요약 정보입니다(또는 어텐션 메커니즘의 대략적인 분류).
| Name | Aligment socre function | citation |
|---|---|---|
| Additive(*) | \(score(\mathbf{s}_t\), \(\mathbf{h}_i\)) = \(\mathbf{v}_a^\top tanh(\mathbf{W}_a[\mathbf{s}_t; \mathbf{h}_i]\)) | Bahdanau2015 |
| Location-Base | \(\alpha_{t,i} = softmax(\mathbf{W}_a \mathbf{s}_t)\) Note : This simplifies the softmax alignment max to only depend on the target position. |
Luong2015 |
| General | \(score(\mathbf{s}_t, \mathbf{h}_i)=\mathbf{s}_t^\top \mathbf{W}_a \mathbf{h}_i\) where \(\mathbf{W}_a\) is a trainable weight matrix in the attention layer. |
Luong2015 |
| Dot-Product | \(score(\mathbf{s}_t, \mathbf{h}_i) = \mathbf{s}_t^\top \mathbf{h}_i\) | Luong2015 |
| Scaled Dot-Product(^) | \(score(\mathbf{s}_t, \mathbf{h}_i) =\) \({\mathbf{s}_t^\top \mathbf{h}_i}\over{\sqrt{n}}\) Note: very similar to dot-product attention except for a scaling factor; where n is the dimension of the source hidden state. |
Vaswani2017 |
| Self-Attention(&) | Retating different position of the same input sequence. Theoretically the self-attention can adopt any score functions above, but just replace the target sequence with the same input sequence. | Cheng2016 |
| Global/Soft | Attending to the entire input state space. | Xu2015 |
| Local/Hard | Attending to the part of input state space; i.e. a patch of the input image. | Xu2015;Luong2015 |
(*) 이 방식은 Luong, et al., 2015 에서는 “concat”이라고 언급되었으며, Vaswani, et al., 2017에서는 “additive attention”이라고 언급되었습니다.
(^)인풋이 매우 길어서 소프트맥스 함수의 그래디언트가 아주 작아져 학습이 어려운 경우를 보완하기 위해서 스케일링 펙터, \(1/\sqrt{n}\),가 더해진 것입니다.
(&) Cheng et al., 2016 등 다른 논문들에서는 intra-attention이라고도 불리웁니다.
Self-Attention
Self-attetion, 또는 intra-attention 으로 알려진 어텐션 메커니즘은 시퀀스의 representation을 계산하기 위해 시퀀스의 서로 다른 포지션과 연관된 방법입니다. 기계 판독, 추상 요약 또는 이미지 설명 생성에 매우 유용합니다.
long short-term memory network 논문에서 기계판독 문제를 해결하기위해 셀프어텐션 기법을 사용하였습니다. 아래 예제와 같이 셀프 어텐션 메커니즘을 통해 현재 단어와 이전 단어들간의 상관관계를 학습할수 있습니다.

그림6. 현재 단어는 빨간색으로 표시하였고, 파란색 그림자의 크기는 엑티베이션 정도를 나타남(출저 : Cheng et al., 2016)
show, attend and tell 논문에서는 셀프어텐션을 이미지에 적용하여 적절한 설명 문구을 생성하였습니다. 이미지는 먼저 컨볼루션 뉴럴 넷을 이용해 인코딩되었고, 인코딩된 피쳐 멥을 인풋으로하는 리커런트 네트워크(셀프 어텐션이 적용된)를 이용해 묘사하는 단어를 하나 하나 생성하였습니다. 어텐션 가중치를 시각화한 결과, 모델이 특정 단어를 생성할 때 이미지에서 어떤 영역을 중점으로 반영하는지 확인할 수 있습니다.

그림7. “A woman is throwing a frisbee in a park.” (Image source: Fig. 6(b) in Xu et al. 2015)
Soft vs Hard Attention
어텐션의 또 다른 정의 방식은 soft와 hard 어텐션입니다. 기본적인 아이디어는 show, attend and tell 논문에서 제안되었습니다. 어텐션이 전체 이미지를 대상으로하는지 혹은 일부 패치 영역을 대상으로 하는지에 따라 :
- soft attention : 가중치가 학습되어, 소스 이미지의 모든 패치에 “소프트하게” 맵핑됨; 근본적으로 Bahdanau et al., 2015와 유사함
- 장점 : 모델이 스무스하고 미분가능함
- 단점 : 소스 이미지가 클 때 계산비용이 큼
- hard attention : 이미지의 일부 패치영역이 한번에 하나씩 선택되는 방식
- 장점 : 인퍼런스에서 더 적은 계산 비용
- 단점 : 모델이 미분불가능하고, 학습 시 variance reduction이나 reinforcement learning같은 더 복잡한 기법들이 필요함 (Luong et al., 2015)
Global vs Local Attention
Luong et al., 2015)에서는 global과 local 어텐션을 제안하였습니다. 글로벌 어텐션은 소프트 어텐션과 유사하고, 로컬 어텐션은 하드와 소프트 개념이 모두 이용해 미분가능하도록 만든 하드 어텐션이라고 생각할수 있습니다. 현재 타겟 단어를 위해 한개의 포지션을 예측하고 소스 포지션 주위로 센터된 윈도우을 이용해 컨텍스트 벡터를 계산합니다.
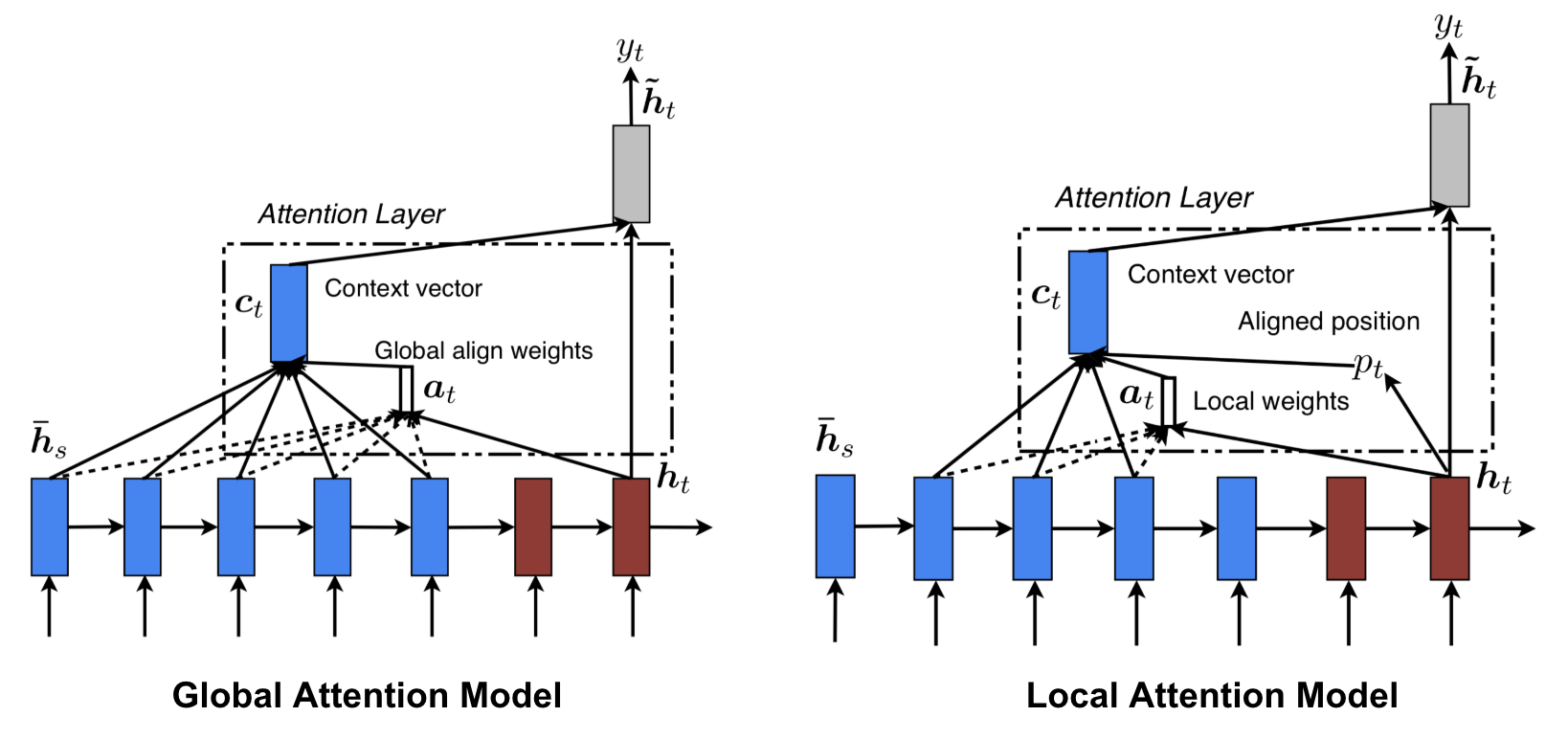
그림8. “글로벌 vs 로컬 어텐션” (Image source: Fig 2 & 3 in Luong et al., 2015)
Transformer
“Attention is All you Need”(Vaswani, et al., 2017), 는 2017년 논문중에서 가장 임팩트있고 흥미로운 논문입니다. 기존 소프트 어텐션 방식을 대폭 개선시키고 recurrent network units없이 seq2seq를 모델링할수 있다는 것을 보였습니다. transformer라는 것을 제안하여 순차적인 계산 구조 없이 셀프 어텐션 메커니즘을 구현할수 있습니다.
핵심은 바로 모델 구조에 있습니다.
key, Value and Query
가장 중요한 부분은 multi-head self-attention mechanism입니다. 트랜스포머는 인풋의 인코딩된 representation을 key-value 쌍, \((\mathbf{K, V})\)의 집합체로 보았습니다; 둘다 n(인풋 시퀀스 길이)차원 벡터로 인코더의 히든 스테이트에 해당. 디코더에서 이전 결과값들은 query(\(\mathbf{Q}\) of dimension m)로 압축되고, 다음 아웃풋은 이 쿼리와 키-벨류 셋트를 맵핑함으로써 계산됩니다.
트렌스포머는 scaled dot-product attention을 사용하였습니다: 아웃풋은 가중합산된 값이고, 가중치들은 쿼리와 키값들의 dot-product로 결정됩니다.
\[Attention(\mathbf{Q, K, V}) = softmax( {\mathbf{Q}\mathbf{K}^\top \over {\sqrt{n}}} )\mathbf{V}\]multi-Head Self-Attention
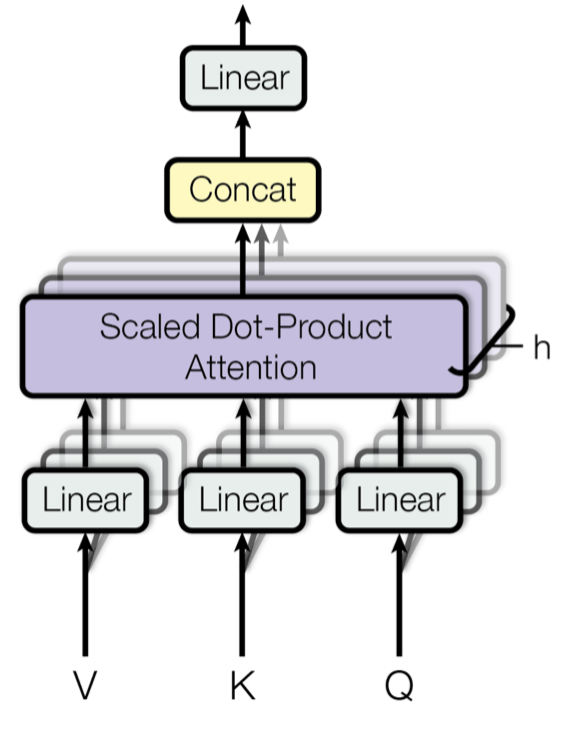
그림9. 멀티-헤드 스케일드 닷-프로덕트 어텐션 메커니즘 (Image source: Fig 2 in Vaswani, et al., 2017)
어텐션을 한번만 계산하는 것보다 멀티-헤드 메커니즘은 스케일 닷-프로덕트 어텐션을 병렬로 여러번 계산된다. 독립적인 어텐션 아웃풋은 단순히 concatenated되며, 선형으로 예상되는 차원으로 변형됩니다. 이렇게 하는 이유는 앙상블은 항상 도움이 되기 때문이 아닐까요? 논문에 따르면 “multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this (멀티-헤드 어텐션은 서로 다른 representation 공간에 있는 포지션 정보를 결합하여 이용할수 있게 해줍니다. 싱글 어텐션 헤드를 이용하면 이런 정보들이 서로 평균화되어 버립니다.)
\[MultiHead(\mathbf{Q, K, V}) = [head_1; ... ; head_h]\mathbf{W}^O \\ where \ head_i = Attenton(\mathbf{QW}_i^Q, \mathbf{KW}_i^K, \mathbf{VW}_i^V)\]where \(\mathbf{W}_i^Q, \mathbf{W}_i^K, \mathbf{W}_i^V\) and \(\mathbf{W}^O\) are parameter matrics to be learned.
Encoder
![]()
그림10. 트랜스포머의 인코더 (Image source: Vaswani, et al., 2017)
인코더는 무한히 클수있는 문백에서 특정 정보 조각을 찾을수 있도록 어텐션 기반의 representation을 생성합니다.
- 동일한 6개의 레이어를 쌓습니다.
- 각 레이어는 멀티-헤드 셀프어텐션 레이어와 포지션-와이즈 풀리 커넥티드 피드-포워드 네트워크를 서브 레이어로 갖습니다.
- 각 서브 레이어는
residual커넥션과layer normalization이 적용됩니다. 모든 서브 레이어는 \(d_{model}=512\)로 동일한 차원의 아웃풋을 갖습니다.
Decoder
![]()
그림11. 트랜스포머의 디코더 (Image source: Vaswani, et al., 2017)
디코더는 인코딩된 representation으로부터 정보를 다시 되돌리는 역할을 합니다.
- 동일한 6개의 레이어를 쌓습니다.
- 각 레이어는 멀티-헤드 셀프어텐션 레이어와 포지션-와이즈 풀리 커넥티드 피드-포워드 네트워크를 서브 레이어로 갖습니다.
- 인코더와 유사하게 각 서브 레이어는 residual 커넥션과 레이어 노말리제이션이 적용됩니다.
- 첫번째 서브레이어의 멀티-헤드 어텐션은 타겟 시퀀스의 미래을 보는 것은 관심이 없으므로, 현재 위치 이후의 포지션 정보는 이용하지 않도록 변형됩니다. (현재 포지션의 이전 정보만 이용하도록)
Full Architecture
트렌스포머의 전체적인 구조는 다음과 같습니다.
- 먼저 소스와 타겟 시퀀스 모두 동일한 디멘션 \(d_{model} = 512\)을 갖도록 임베딩 레이어를 거칩니다.
- 포지션 정보를 유지하기 위해 sinusoid-wave-based positional encoding을 적용한 후 임베딩 아웃풋과 합칩니다.
- 마지막 디코더 아웃풋에 소프트맥스와 선형 레이어가 추가됩니다.
![]()
그림12. 트랜스포머의 전체 모델 구조 (Image source: Fig 1& 2 in Vaswani, et al., 2017)>
SNAIL
트랜스포머는 리커런트 또는 컨볼루션 구조를 사용하지 않고, 임베딩 벡터에 포지션 인코딩이 더해지긴 하지만 시퀀스의 순서는 약하게 통합되는 수준입니다. 강화 학습과 같이 위치 종속성에 민감한 경우, 큰 문제가 될 수 있습니다. Simple Neural Attention Meta-Learner(SNAIL)Mishra et al., 2017는 트랜스포머의 셀프-어텐션 메커니즘과 시간적 컨볼루션을 결합하여 포지션 문제를 부분적으로 개선하기 위해 제안되었습니다. SNAIL은 지도학습과 강화학습 모두에서 좋은 결과를 보입니다.
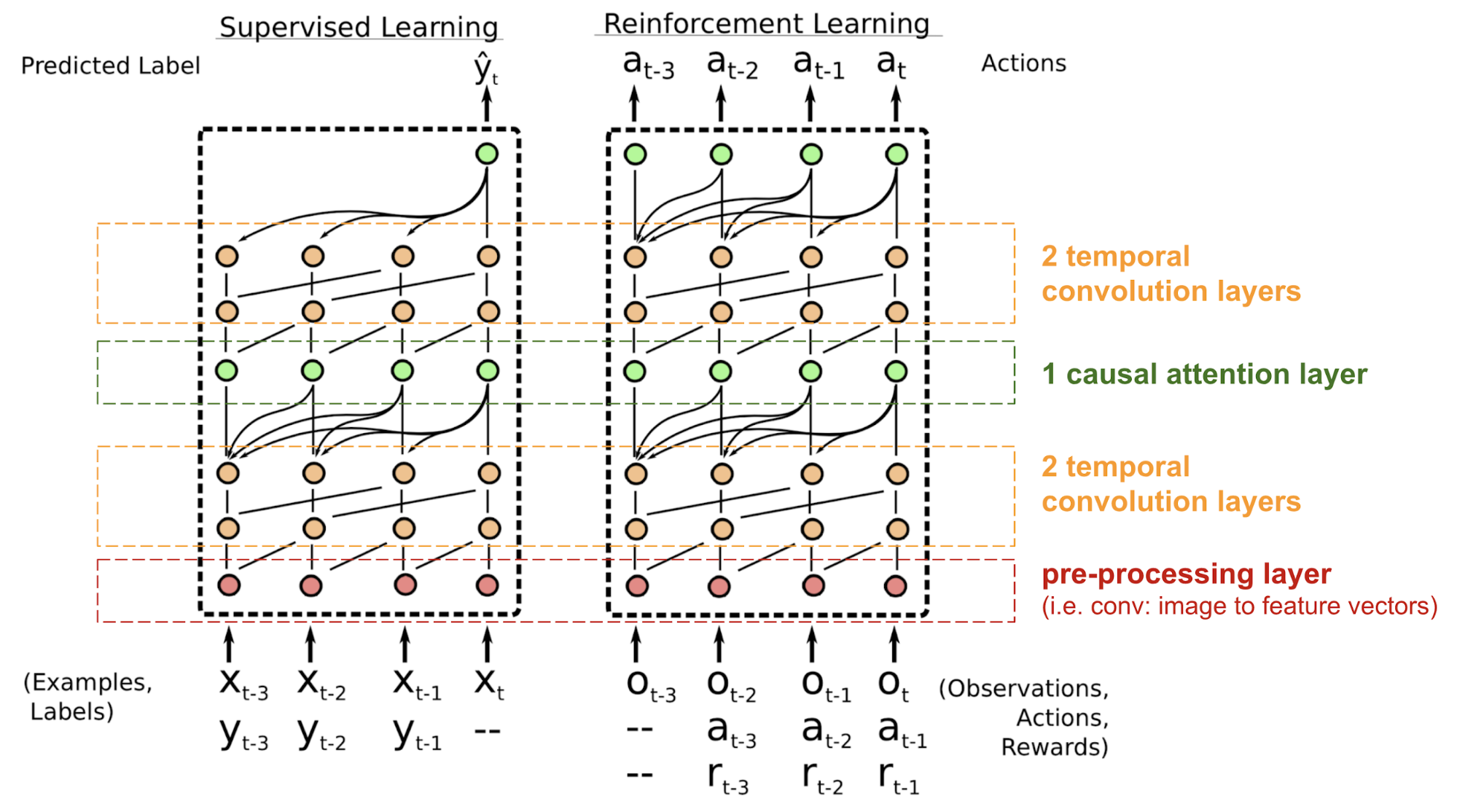
그림13. SNAIL 모델 구조 (Image source: Mishra et al., 2017)
SNAIL은 그 자체만으로도 중요한 토픽인 메타-러닝 분야에서 최초 제안되었습니다. 간단히 말해서 메타 러닝 모델은 비슷한 분포에서 nevel, unseen tasks들에 일반화할수 있습니다. 더 자세한 정보는 이 글을 확인하세요.
Self-Attention GAN
마지막으로 Generative Adversarial Network (GAN)타입의 모델인, `self-attention GAN(SAGAN; Zhang et al., 2018)을 통해서 어텐션이 생성이미지의 퀄리티를 향상시키는지 설명하도록 하겠습니다.
DCGAN(Deep Convolutional GAN)에서 discriminator와 generator은 멀티-레이어 컨볼루션 네트워크입니다. 하지만 하나의 픽셀은 작은 로컬 영역으로 제한되기 때무네, 네트워크의 representation capacity는 필터 사이즈에 의해 제한됩니다. 멀리 떨어진 영역을 연결하기 위해서 피쳐들이 컨볼루션 오퍼레이션을 통해 희석되어야하여 종속성이 유지되는 것이 보장되지 않습니다.
비전 컨텍스트에서 (소프트) 셀프-어텐션은 한 픽셀과 다른 포지션의 픽셀들간에 관계를 명시적으로 학습하도록 설계되어 있습니다. 멀리 떨어진 영역이더라도 쉽게 글로벌 디펜던시를 학습할수 있습니다. 따라서 셀프-어텐션이 적용된 GAN은 디테일한 정보를 더 잘 처리할수 있습니다.
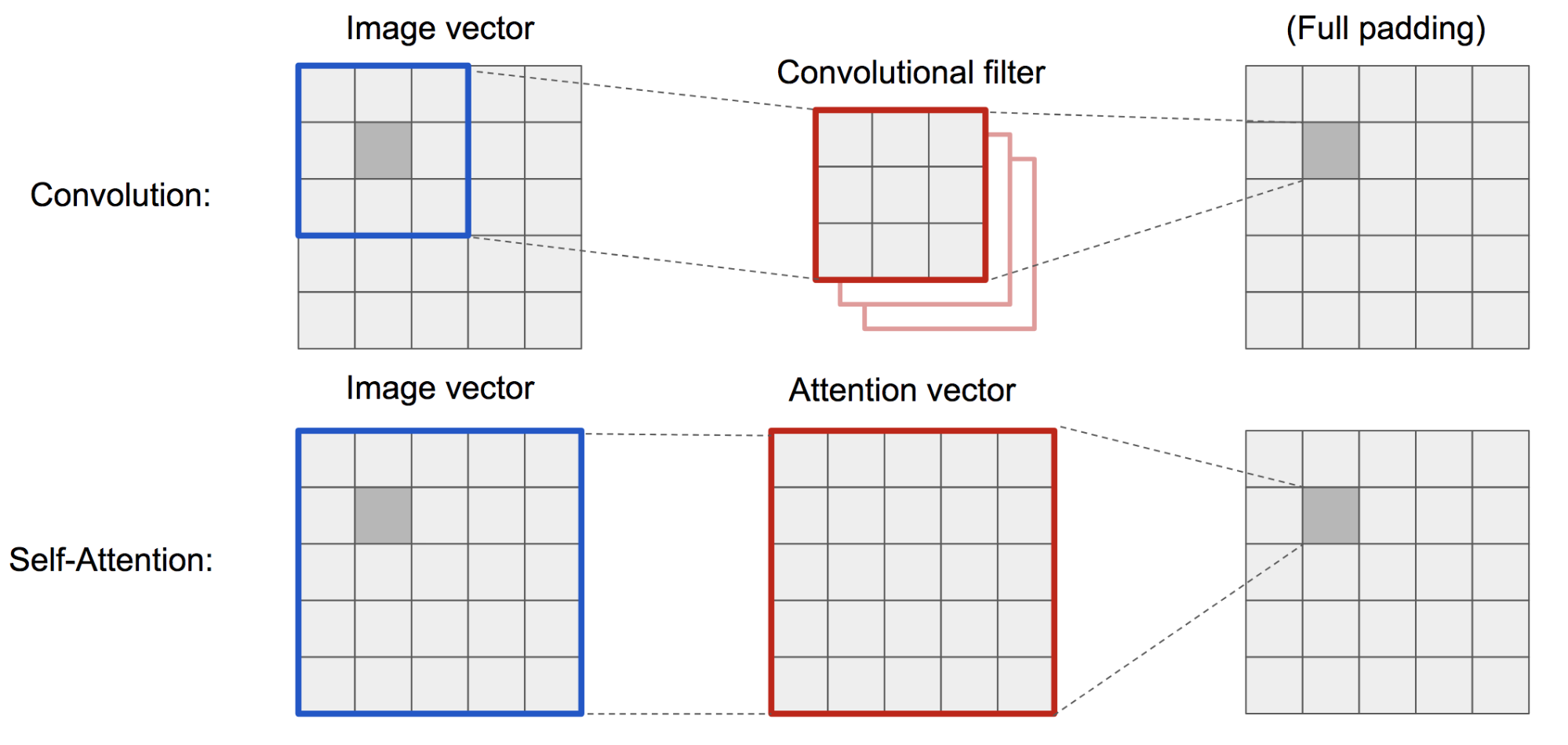
*그림14. 컨볼루션 오퍼레이션과 셀프-어텐션은 서로 다른 사이즈의 영역을 다룹니다. *>
SAGAN은 어텐션 계산을 위해서 non-local neural network를 도입하였습니다. 컨볼루셔널 이미지 피쳐맵 \(x\)는 3개로 복제되어 나눠지며, 이는 트랜스포머에서 각 각 key, value, and query 개념에 대응됩니다.
- Key : \(f(x)=W_fx\)
- Query : \(g(x)=W_gx\)
- Value : \(h(x)=W_hx\)
그리고 나서 dot-product 어텐션을 셀프-어텐션 피쳐맵에 적용합니다 :
\[\alpha_{i, j} = softmax(f(\mathbf{x}_i)^{\top}g(\mathbf{x}_j))\\ \mathbf{o}_j = \sum_{i=1}^{N} \alpha_{i,j}h(\mathbf{x}_i)\]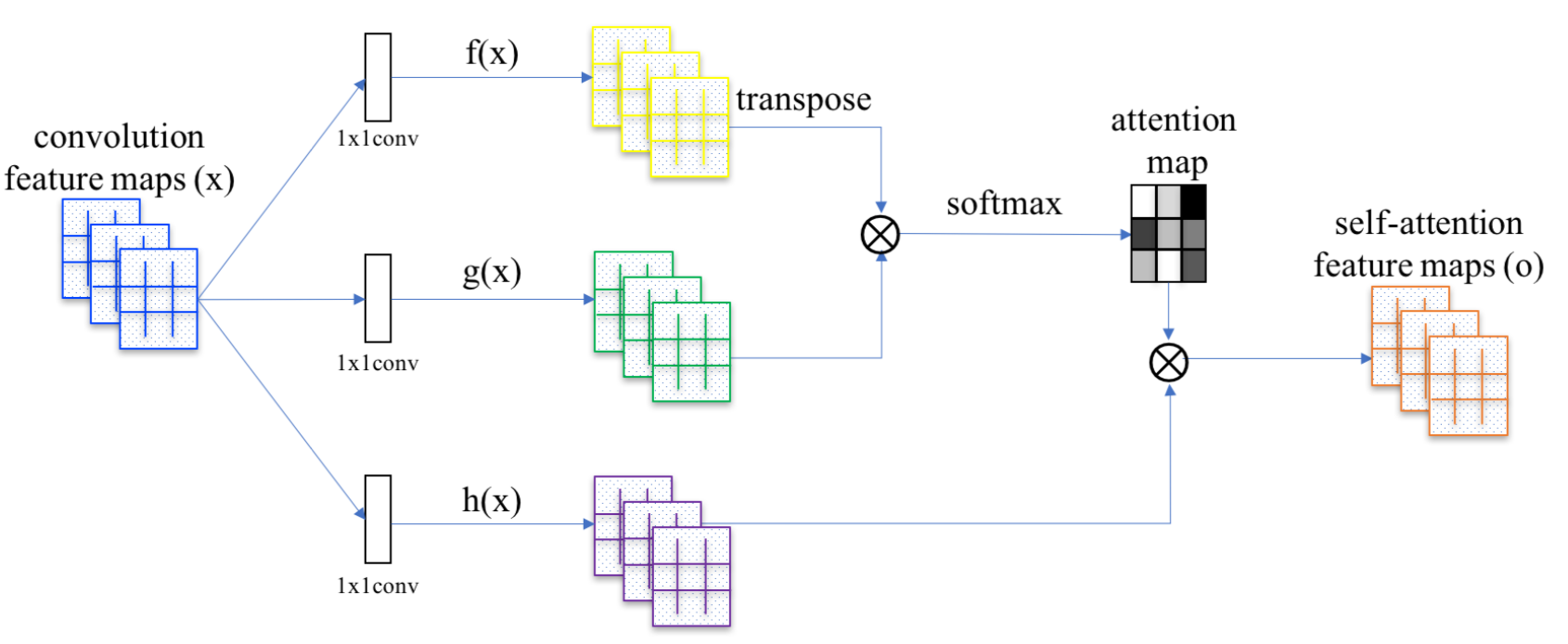
*그림15. SAGAN에서 셀프-어텐션 메커니즘 (Image source : Fig 2 in Zhang et al., 2018) *>
\(\alpha_{i,j}\)는 j번째 위치를 합성할 때 모델이 i번째 위치에 얼마나 많은 주의를 기울여야하는지를 나타내는 어텐션 맵의 엔트리입니다. \(\mathbf{W}_f, \mathbf{W}_g, \mathbf{W}_h\)는 1x1 컨볼루션 필터입니다. 만약 1x1 conv가 이상하다고 생각되면(단순히 피쳐맵 전체 값에 한개 값을 곱하는 것 아니냐?라고 생각한다면) 앤드류 응의 튜토리얼을 보세요. 아웃풋 \(\mathbf{o}_j\)는 마지막 아웃풋 \(\mathbf{o} = (\mathbf{o}_1, \mathbf{o}_2, ..., \mathbf{o}_j, ..., \mathbf{o}_N)\)의 컬럼 벡터입니다.
추가로 어텐션 레이어의 아웃풋에 스케일 파라미터를 곱하고, 오리지날 인풋 피쳐맵을 더해줍니다.
\[\mathbf{y} = \mathbf{x}_i + \rho \mathbf{o}_i\]스케일링 파라미터 \(\rho\)는 학습과정에서 0에서 점차 증가하고, 네트워크는 처음에는 로컬 영역에만 의존하다가 점차 멀리있는 영역에 더 많은 가중치를 주는 방법을 배우도록 구성됩니다.

*그림16. SAGAN에 의해 생성된 이미지(128x128) 예들 (Image source : partial Fig 6 in Zhang et al., 2018) *>
References
[0] lilianweng의 Attention? Attention!
[1] “Attention and Memory in Deep Learning and NLP.” - Jan 3, 2016 by Denny Britz
[2] “Neural Machine Translation (seq2seq) Tutorial”
[3] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. “Neural machine translation by jointly learning to align and translate.” ICLR 2015.
[4] Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Yoshua Bengio. “Show, attend and tell: Neural image caption generation with visual attention.” ICML, 2015.
[5] Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. “Sequence to sequence learning with neural networks.”NIPS 2014.
[6] Thang Luong, Hieu Pham, Christopher D. Manning. “Effective Approaches to Attention-based Neural Machine Translation.” EMNLP 2015.
[7] Denny Britz, Anna Goldie, Thang Luong, and Quoc Le. “Massive exploration of neural machine translation architectures.” ACL 2017.
[8] Ashish Vaswani, et al. “Attention is all you need.” NIPS 2017. http://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf
[9] Jianpeng Cheng, Li Dong, and Mirella Lapata. “Long short-term memory-networks for machine reading.” EMNLP 2016.
[10] Xiaolong Wang, et al. “Non-local Neural Networks.” CVPR 2018
[11] Han Zhang, Ian Goodfellow, Dimitris Metaxas, and Augustus Odena. “Self-Attention Generative Adversarial Networks.” arXiv preprint arXiv:1805.08318 (2018).
[12] Nikhil Mishra, Mostafa Rohaninejad, Xi Chen, and Pieter Abbeel. “A simple neural attentive meta-learner.” NIPS Workshop on Meta-Learning. 2017.
[13] “WaveNet: A Generative Model for Raw Audio” - Sep 8, 2016 by DeepMind.
Comments